RedisTutorial02
1.Redis存储过程
Redis数据存储的核心是基于redisDb结构,它是Redis中最顶层的数据库对象。
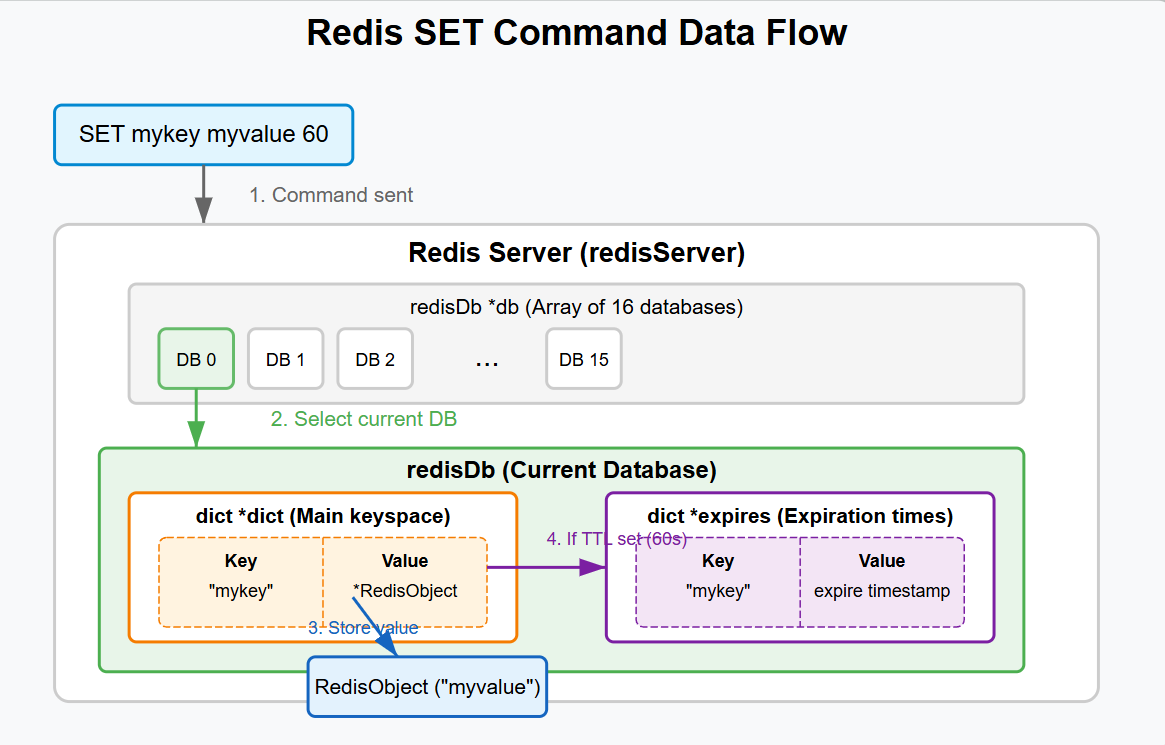
redisDb代表Redis数据库结构,上一章,我们讲到的各种操作对象,就是存储在dict数据结构里,本节后面的讲述中,我们都会以上一章节的操作对象为例来进行讲解。
redisDb结构
redisDb结构体(来自Redis 5.0.5)包含以下主要字段:
1 | typedef struct redisDb { |
这里我们重点关注dict结构,其它字段可以先忽略,它代表了我们存入的key-value存储,我们平常添加数据,就是往dict里添加。可以看到,dic其实就是我们前面介绍的Hash对象结构。
dict结构
在redisDb中,最核心的是dict字段,它是Redis键值对存储的主要结构。图片展示了dict的定义:
1 | typedef struct dict { |
存储过程解析
Redis存储数据的过程如下:
- Redis服务器维护一个redisDb数组,包含16个数据库
- 当我们使用SET命令存储一个键值对时:
- Redis首先找到当前使用的数据库(redisDb对象)
- 然后通过redisDb中的dict(主键空间)来存储这个键值对
- 键名直接作为key存入dict
- 值被封装为RedisObject对象,然后将其指针作为value存入dict
- 如果设置了过期时间,键名和过期时间会被存入expires字典
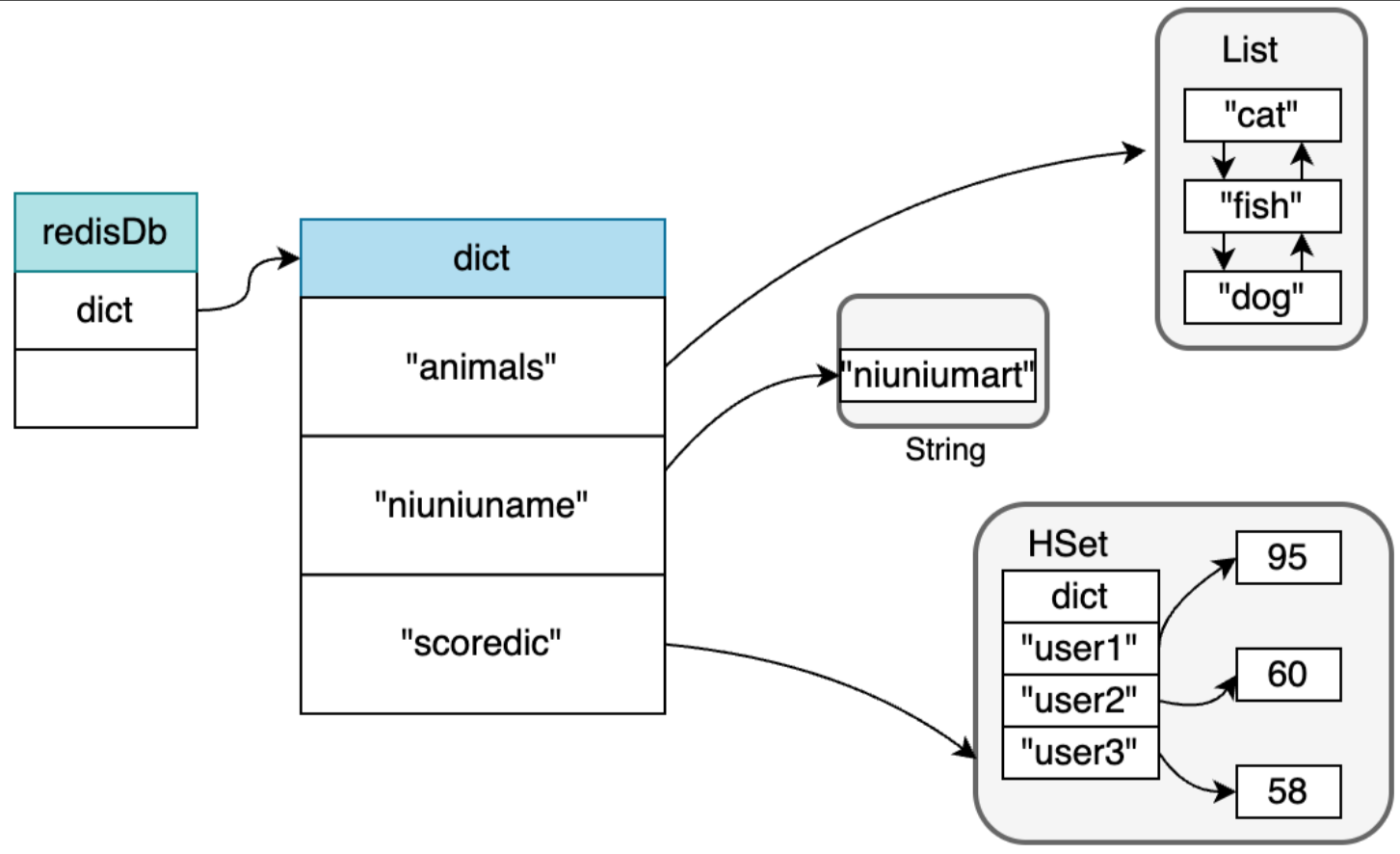
过期键
Redis数据都可以设置过期键,这样到了一定的时间,这些对象就会自动过期并回收。过期键就存储redisDb的expires字典上。
假设上面例子的Key,都设置了过期时间,那么其结构如下:
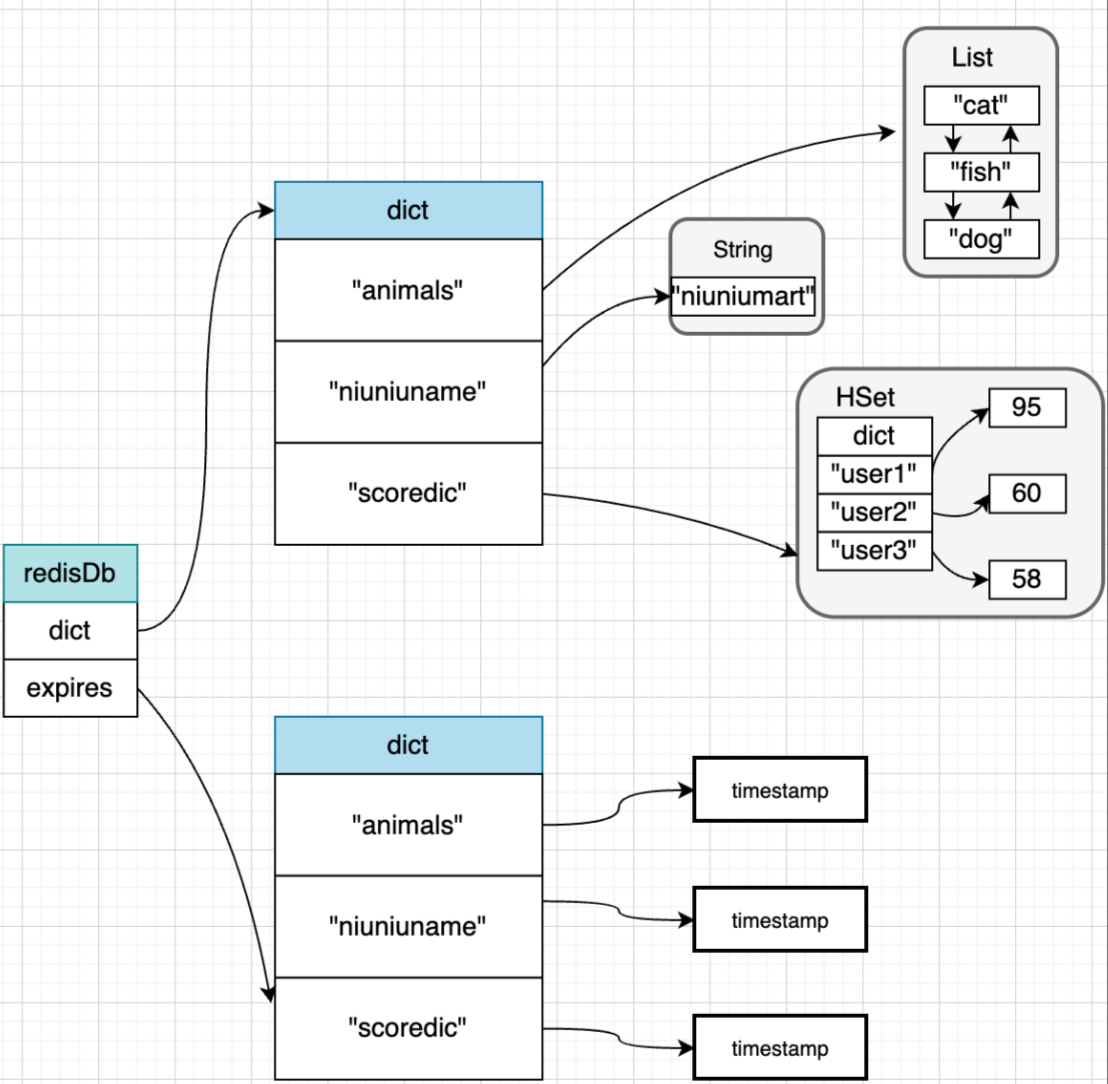
注意,这里的dict中和expires中Key对象,实际都是存储的String对象指针,所以并不是会重复占用内容。Redis对内存的使用都是很珍惜的。
个人理解:dict 和 expires 结构都是一样的,类似 java 里HashMap 的Node<K,V>数组,可以把 dict 和 expires 理解为两个 Node<K,V>数组,二者的K复用的同一个对象,作为指针指向同一个内存地址(比如”animals”)。区别是dict的V指向redisObj,expires的V指向过期时间 timestamp.
这就自然引出一个问题:过期后的键值对Redis是如何处理的呢?实际上,过期后的键不会立刻删除,一般会采用三种清除策略,分别是定时、定期、惰性删除。
定时删除,是在设置键的过期时间的同时,创建一个定时器,让定时器在键的过期时间来临时,立即执行对键的删除操作,定时删除对内存比较友好,但是对CPU不友好,如果某个时间段比较多的Key过期,可能会影响命令处理性能。
惰性删除,是指使用的时候,发现Key过期了,此时再进行删除,这个策略的思路是对应用而言,只要不访问,过期不过期业务都无所谓,但是这样的代价就是如果某些Key一直不来访问,那本该过期的Key,就变成常驻的Key。这种策略对CPU最友好,对内存不太友好。
定期删除,每隔一段时间,程序就对数据库进行一次检查,每次删除一部分过期键,这属于一种渐进式兜底策略。
定时删除实现起来其实没有想象的容易,主要考虑是如果出现异常,有Key遗漏了怎么办,以及如果程序重启,原来的定时器就随重启消失了,那就需要在启动时对过期键进行一些操作,可能是重建定时器,这些都是额外的工作,而且引入了多余的复杂度。
从实际功能而言,其实并不需要那么实时,所以惰性删除是可以考虑的,但是出于应删尽删的考虑,要保证最终没有漏网之鱼,那就需要加上定期删除作为兜底。所以Redis过期键采用的是惰性删除+定期删除二者结合的方式进行删除的。
2.Redis单线程
Redis是一个能高效处理请求的组件,一般而言,对这种组件,我们都需要了解其并发模型是怎样的,比如Nginx是多进程模型,Mysql是多线程模型,那Redis又是什么呢?多线程型吗?
先说结论,核心处理逻辑,Redis一直都是单线程的,但是其它辅助模块也会有一些多线程、多进程的功能,比如:
复制模块用的多进程;某些异步流程从4.0开始用的多线程,例如 UNLINK、FLUSHALL ASYNC、FLUSHDB ASYNC 等非阻塞的删除操作;
网络I/0解包从6.0开始用的是多线程;
但是这种分支模块,都只是辅助,最核心的还是处理架构,这块Redis始终是单线程的。
Redis采用Reactor模式的网络模型,对于一个客户端请求,主线程负责一个完整的处理过程:
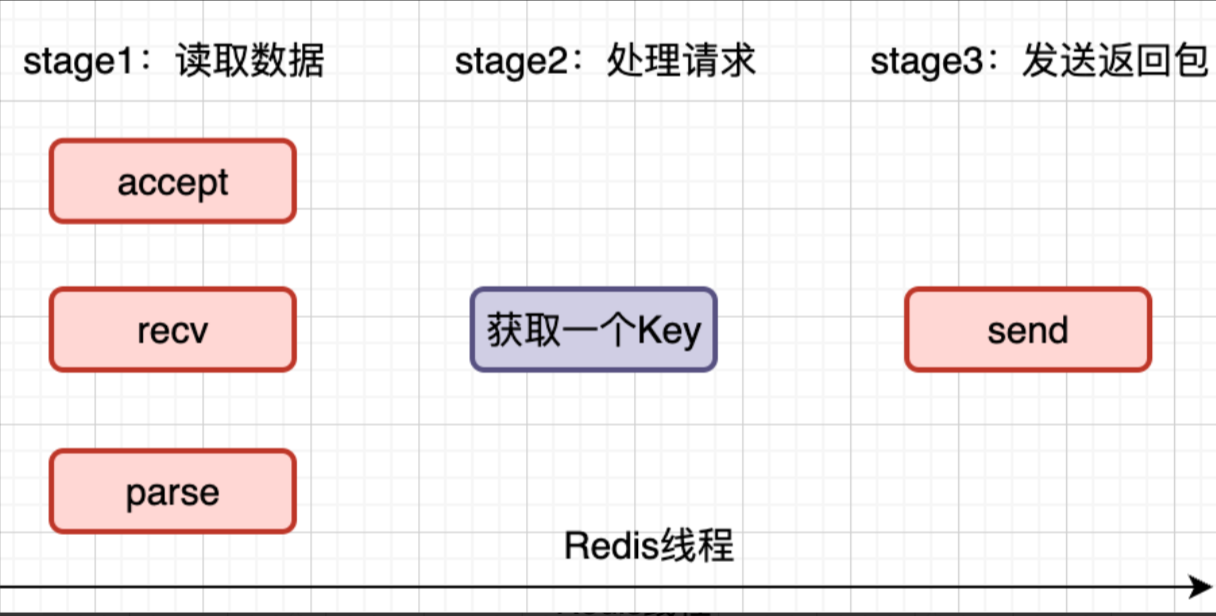
Redis 在处理客户端的请求时包括获取(socket 读)、解析、执行、内容返回(socket 写)等都由一个顺序串行的主线程处理这就是所谓的“单线程”。
为什么不用多线程?
1.引入多线程会带来很大的复杂度,比如所有数据类型都需要重构成线程安全的等等,对于追求简洁的Redis而言,这是一个需要非常谨慎的事,事实上Redis 6.0之后为I/O处理引入了多线程来提高性能,核心处理逻辑还是保留单线程,但是即使这样,6.0之后的复杂性还是多了许多,更别说完全改成多线程处理了。
2.多线程会带来额外的开销,比如:
- 上下文切换成本,多线程调度需要切换线程上下文,这个操作先存储当前线程的本地数据、程序指针等,然后载入另一个线程数据,这种内核操作的成本不可忽视。
- 同步机制的开销,一些公共资源,在单线程模式下直接访问就行了,多线程需要通过加锁等方式去进行同步,这也是不可忽视的CPU开销;
- 一个线程本身也占据内存大小,对Redis这种内存数据库而言,内存非常珍贵,多线程本身带来的内存使用的成本也需要谨慎决策。
所以综合来看,多线程其实会带来非常多的成本,如果将处理模块改为多线程,即使在性能上,可能也很难有一个很高的预期,毕竟Redis单线程的处理,已经够快了。
单线程为什么这么快?
有几个关键点:
第一,Redis 的大部分操作在内存上完成,内存操作本身就特别快;
第二,Redis追求极致,选择了很多高效的数据结构,并做了非常多的优化,比如ziplist,hash,跳表,有时候一种对象底层有几种实现以应对不同场景。
第三,Redis 采用了多路复用机制,使其在网络 IO 操作中能并发处理大量的客户端请求,实现高吞吐量。
第一点很好理解,第二点我们在数据结构部分,已经深入分析过了,Redis对数据结构真是近乎偏执地去优化,这里不做赘述。
接下来,我们重点看第三点多路复用机制。要理解多路复用机制,我们要先理解为什么要多路复用,没有多路复用情况下,哪些环节可能发生阻塞,Redis是单线程模型,一旦发生阻塞,整体服务都会下来。
下面,我们来分析下Redis是怎么处理请求的。
比如,客户端发来一个GET请求,服务端需要哪些事情?
1.客户端请求到来时候,使用accept建立连接
2.调用recv从套接字中读取请求
3.解析客户端发送请求,拿到参数
4.处理请求,这里是Get,那么Redis就是通过Key获取对应的数据
5.最后将数据通过send发送给客户端
我们要知道,套接字是默认阻塞模式的,这里阻塞可能会发生在两个地方。一个是accept,比如accept建立时间过长,另一个是recv时客户端一直没有发送数据。此时,Redis服务就会阻塞在那里。Redis本身定位就是单线程,发生这种阻塞会将整个服务都卡住。所以不能让这两个操作阻塞,这里Redis将套接字设置为非阻塞式的,这样accept和recv都可以非阻塞调用。
这里非阻塞的意思就是响应会立即返回,无论是否有连接请求。如果没有连接请求,accept 会返回一个特定的错误码通常是 EWOULDBLOCK 或EAGAIN),表明当前没有连接可接受。
最简单的思路,我们可以通过一个循环来不断轮询,但这种方式显然低效。好在各个操作系统实现了一种机制,叫I/O多路复用。
什么叫I/O多路复用,简单理解来说,就是有I/O操作触发的时候,就会产生通知,收到通知,再去处理通知对应的事件,针对I/O多路复用,Redis做了一层包装,叫Reactor模型。
如下图,本质就是监听各种事件,当事件发生时,将事件分发给不同的处理器。(注:考虑到Reactor模型是单核执行,这里比处理器更准确的说法应该是不同处理函数。)
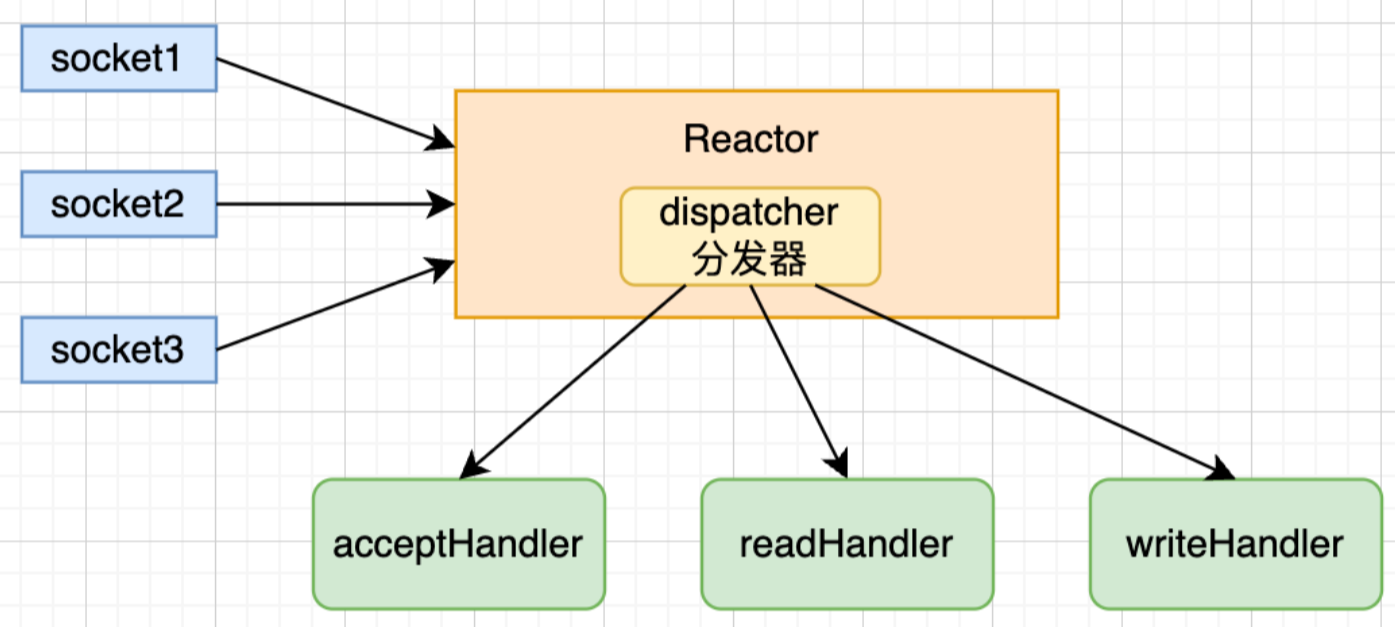
就这样通过调用系统的 IO多路复用技术的 api,比如 epoll,使得 redis 可以同时监听多个客户端的请求;然后哪个产生了请求,redis 就立马用 dispatcher 去分发处理。显然这里是通过并发执行优化了数据读取侧的IO。
3.Redis多线程实现
然而随着业务请求量越来越高,Redis不得不在原有结构上进行修改来优化读取请求、发送回包的IO操作。
Redis多线程的设计思路如下:
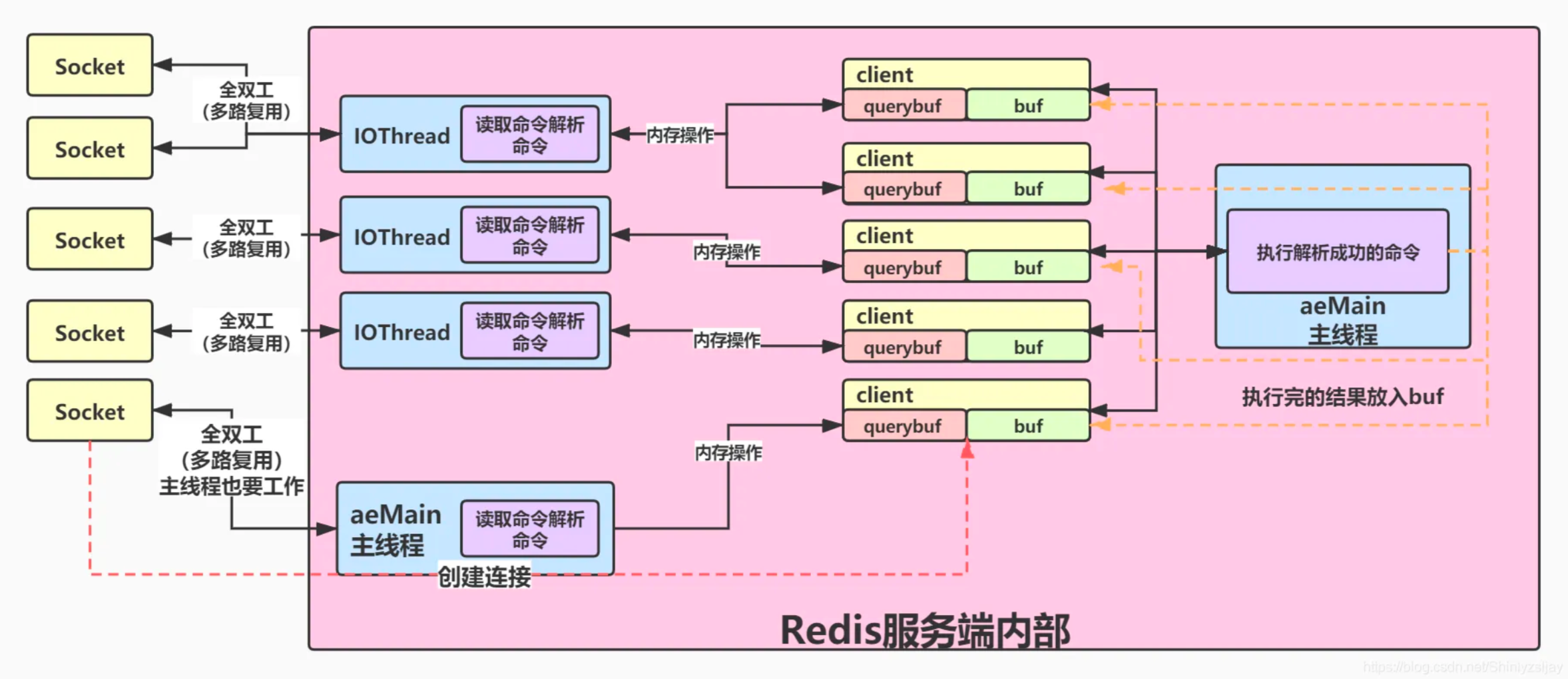
主线程视角
事件循环
主线程和6.0版本之前一样,还是使用aeMain来处理监听端口的事件循环。
1 | void aeMain(aeEventLoop *eventLoop){ |
当有客户端有连接过来,acceptTcpHandler 被调用,主线程使用 AE 的 API 将 readQueryFromClient 命令读取处理器绑定到新连接对应的文件描述符上,并初始化一个 client 绑定这个客户端连接;当client的读写请求过来,就会调用readQueryFromClient这个方法。
老版本是在readQueryfromClient函数中同步完成读取、解析、执行、将回包放入客户端输出缓冲区。但是多线程模式下,则只会调用postponeClientRead将client加入到 clients pending read任务队列中去,后面主线程再分配 I/O 线程去读取客户端请求命令。
1 | void readQueryFromClient(connection *conn) { |
放进队列之后,主线程会在事件循环beforeSleep函数中,调用 handleClientsWithPendingReadsUsingThreads,目的是通过 Round-Robin 轮询负载均衡策略把所有任务分配给 I/O 线程和主线程去读取并解析客户端命令。
和单线程时候一样,多线程版本也是在beforesleep来触发回包,不同的是多线程版本下的beforeSleep会使用多线程来进行回包:利用 Round-Robin 轮询负载均衡策略,把 等待回包队列中的连接均匀地分配给 I/O 线程各自的本地 FIFO 任务队列 和主线程自己,主线程轮询等待所有 I/O 线程完成回包任务。
子线程视角
等待事件
1.自旋1000000次等待资源(就是循环去看有没有分配给自己的任务)
2.获取io_threads_mutex互斥锁,一开始会阻塞在这里。(虽然发现有任务了,但是为了防止我和其他线程干同一个任务,所以要等到主线程把锁给我我才能执行,类似于一个信号)
此时,就需要等待主线程来触发资源。
处理事件
I/O 线程在感知到主线程通知的事件变化,会遍历自己的本地任务队列io_threads_list,取出client来执行。
1 | while(1) { |
可以看到,相比于主线程,子线程的逻辑还是比较清晰简单的。子线程会根据事件类型来决定是回包writeToClient,还是读取数据readQueryFromClient。如果是writeToClient,就诵过socket把缓冲区数据发送给客户端,如果是读取操作,就通过socket读取客户端命令,存入读取缓存,这里最终只会解析到第一条命令,然后就结束,不会去执行命令。
在全部任务执行完之后把自己的原子计数器置 0,以告知主线程自己已经完成了工作。
总结
主线程负责管理自己所监听的fd;
当监听到有读或者写事件时,就封装成一个任务,放到任务队列中,而其他的工作线程就从这个任务队列中取任务完成相应的数据准备(用户缓冲区<——>内核缓冲区 +数据解析)的工作。
而完成这些数据准备工作之后,所有任务的业务逻辑那一部分还是由单线程处理。
4.内存淘汰算法
主要的介绍思路是:淘汰时机、淘汰策略、如何选择。
内存满了怎么办
我们都知道Redis是基于内存存储,那我们能存入多少数据到Redis呢?
使用maxmemory配置,默认是被注释掉的,在 32 位操作系统中,maxmemory 的默认值是 3G,因为 32 位的机器最大只支持 4GB 的内存,而系统本身就需要一定的内存资源来支持运行,默认3G相对合理。而现在的机器基本都是64位机器,我们后面重点关注以及面试重点提到的也是64位机器下的情况,64位机器不会限制内存的使用。
淘汰策略的话,大方向有两个:
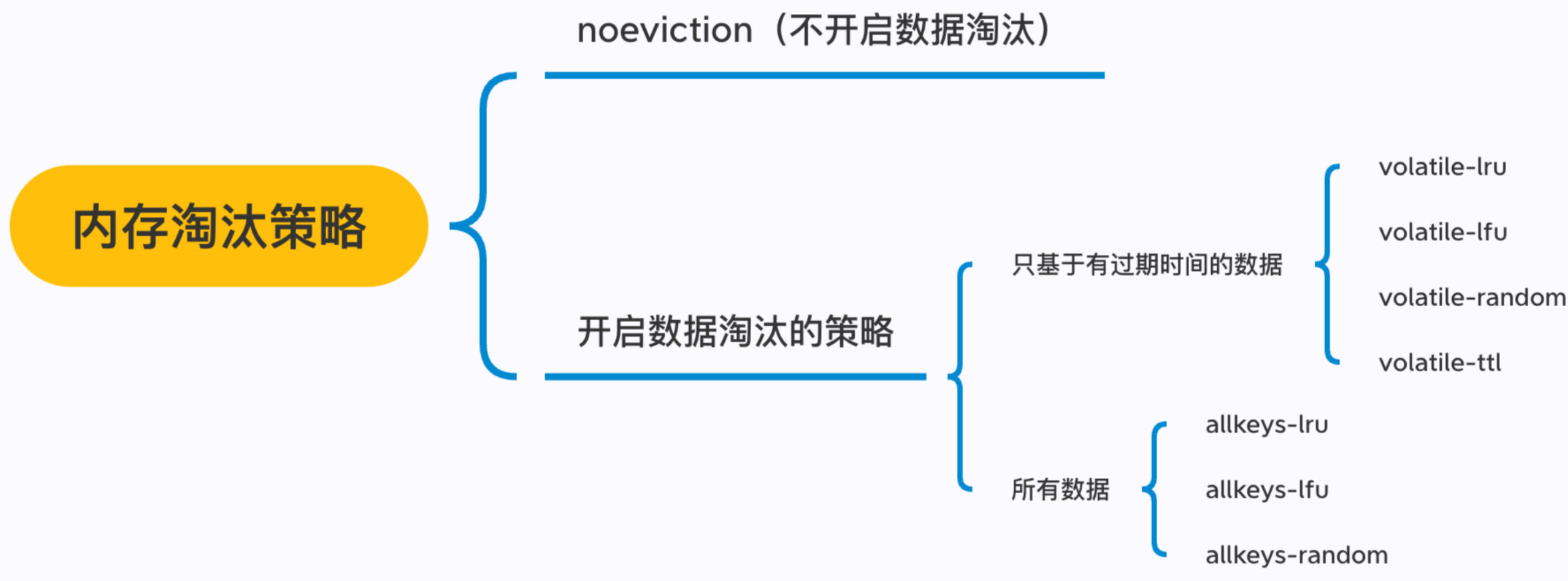
一个是noeviction,默认就是这种策略,此时如果内存达到maxmemory,则写入操作会失败,但不会淘汰已有数据。
第二个是多种淘汰策略,主要支持LRU,LFU,RANDOM,TTL这几个方式:
- lru:根据LRU(Least recently used,最近最少使用)算法尝试回收最长时间未使用的。
- lfu:根据LFU(Least Frequently Use)驱逐最不常用的键,lfu是在4.0引入的。
- random:回收随机的键使得新添加的数据有空间存放。
- ttl:回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
这四种策略,可以选择时volatile,也就是设置了过期时间的Key,或者是allkeys,即全部的Key,所以一共有8种淘汰方式。
volatile 这个单词在 Redis 内存淘汰策略中的使用,是基于其原本的意义“挥发“或“易变”,而与Redis 键的 过期性 相关。Java 中的 volatile 关键字是用来确保变量在多线程环境中的可见性,它和 Redis 的内存淘汰策略没有直接关系。
LRU
LRU算法是什么
最近最久未使用,即记录每个Key的最近访问时间,维护一个访问时间的数据。
Redis用LRU算法会有什么问题
如果为所有数据维护一个顺序列表,实际就是做一个双向链表,但是如果Redis数据稍微多些,这个链表就是巨大的成本,对于Redis而言,内存是最宝贵的,所以Redis选择了近似LRU算法。
算法概述
在LRU模式,redisObject对象中lru字段存储的是key被访问时Redis的时钟server.lruclock,当key被访问的时候Redis会更新这个key的redisObject的lru字段。
近似 LRU 算法在现有数据结构的基础上采用随机采样的方式来淘汰元素,当内存不足时,就执行一次近似 LRU 算法。
具体步骤是随机采样 n个 key(这个采样个数默认为 5)然后根据时间戳淘汰掉最旧的那个 key,如果淘汰后内存还是不足,就继续随机采样来淘汰。
近似 lru 的随机采样和 volatile-random 有什么区别呢?我的理解是 volatile-random 随机选取有过期时间的元素后就直接淘汰被选取的元素,而lru 在随机挑选出元素后,淘汰掉其中最久没有被访问的那个。区别在于是否直接淘汰被选择的元素。
采样范围与时机
采样范围是什么呢?Redis可以选择范围策略,有两种:
1.allkeys,所有key中随机采样。
2.volatile,从有过期时间的key随机采样。分别对应allkeys-lru,volatitle-lru。
触发时机也很简单,就是当使用内存超过 maxmemory 之后,会触发自动的数据淘汰。
淘汰池优化(重要)
近似LRU,优点在于节约了内存,但它的缺点就是不是一个完整的LRU,随机采样得到的结果,其实不是全局真正的最久未访问,在数据量大的情况,尤其是这样。
Redis3.0对近似LRU算法进行了一些优化。
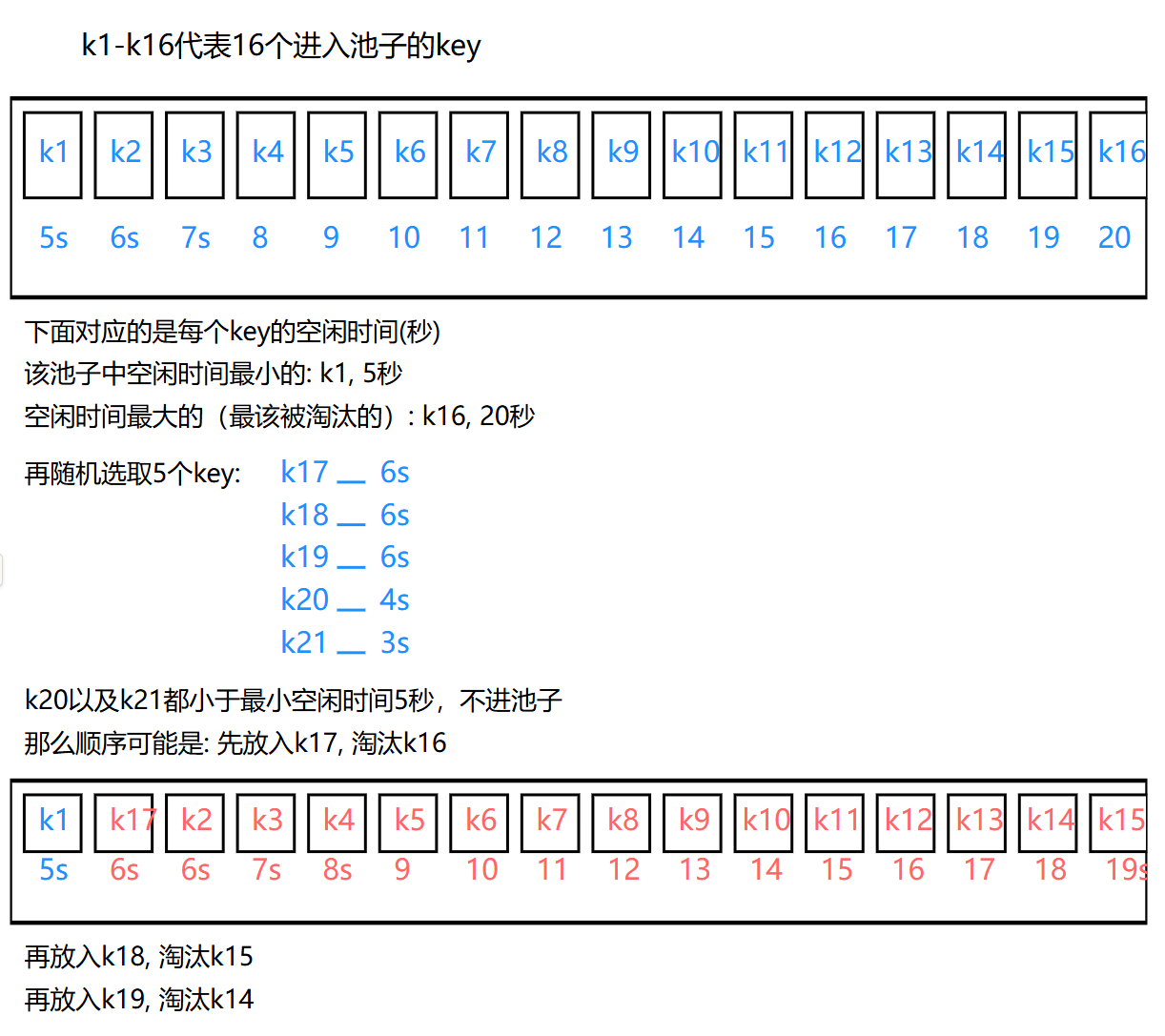
新算法会维护一个大小为16的候选池,池中的数据根据访问时间进行排序。第一次随机选取的key都会放入池中然后淘汰掉最久未访问的,比如第一次选了5个,淘汰了1个,剩下4个继续留在池子里。
注:Redis为了保证核心单线程服务性能,缓存了Unix操作系统时钟,默认每100毫秒更新一次,缓存的值是Unix
时间戳取模2^24。lru字段表示的时间戳越小,就代表这个key空闲的时间越大,就越应该被淘汰
- 如果池子未满,那不管空闲时间大还是小,都需要填充到池子里面
- 如果池子满了,每次随机选取的key只有空闲时间 > 当前池子里面最小空闲时间的key时才会放入池中,然后将池中空闲时间最大的key进行淘汰
通过池子存储,其表现也会非常接近真正的LRU。
以下图片可以帮助理解:
总结
数据触发内存上限时发生内存淘汰,开始采样。采样范围分成全域和过期域可以自己选,方式是随机采样,采到的样按照要求会发配到淘汰池,再根据规则淘汰。
LFU
LFU是什么
LFU淘汰算法,即Least Frequently Used,最不频繁淘汰算法,顾名思义,优先淘汰活跃最低,使用频率最低的。
为什么4.0引入LFU
LRU本身已经能解决大部分问题,但是脱离频率,只谈最近访问,在部分场景是得不到我们希望的结果,比如:
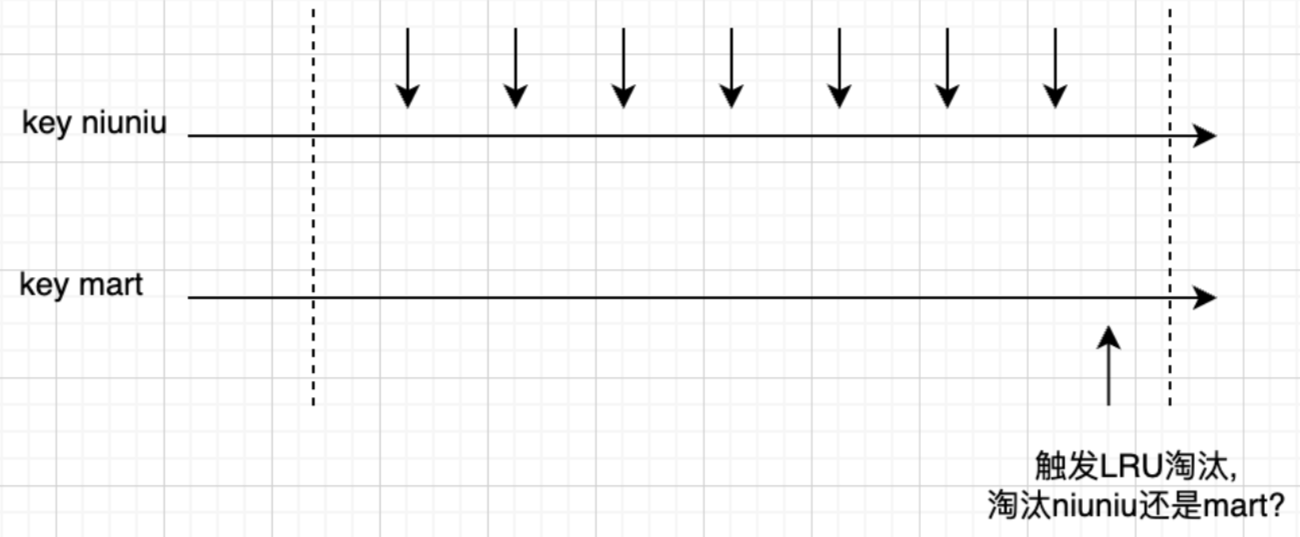
如上所示,key niuniu频率很高,key mart虽然是最近访问的,但是实际频率低(我们假设没有其他key的干扰),如果内存满了,会淘汰key niuniu。
但如果用LFU的话,会淘汰key mart,可以保留频率较高的keyniuniu希望按访问频率来进行淘汰,这其实是一个很正常的需求,LFU就是专门做这个事的。
我们都知道,redisObj里是有记录lru的字段的。如果想使用LFU,因为LRU、LFU是不会同时开启的,基于这个情况,加上节约内存的考虑,Redis在LFU策略下复用lru字段,还是用它来表示LFU的信息,不过将24拆解,高16bit存储ldt(Last DecrementTime),低8bit存储logc(Logistic Counter)。

如图所示,高的16位保存了上次访问时间戳,因为少了8位,所以LFU下时间的最小分度是1分钟,不然用秒的话2^16次方只能表示65536秒,后8位存储的是一个访问计数。
一个Key是否活跃,就是这两个字段综合决定的。
如果上一次访问时间很久,那么访问计数就会衰减,这里有同学问为什么要衰减,因为只是简单的增加访问计数的方法并不完美,访问的热度一直在变,比如一个Key,他原来是255,夸张一点,一年没访问了,不该归零么。而本身访问,会增加访问计数。
当然,最后起判断是否留存的变量就是访问计数。接下来我们讲一下数据更新的过程。
数据更新
第一步,计算次数衰减
因为无论是多快,相对于上次访问,一定有时间间隔,根据间隔,来计算你应该减少的次数。使用的函数就是LFUDecrAndReturn。
第二步,一定概率增加访问计数
这里可能会疑问,为什么是一定概率增加访问计数,次数不足5次,那一定会增加,如果大于5次,小于255次,会一定概率加1,原来的次数越大,越困难。
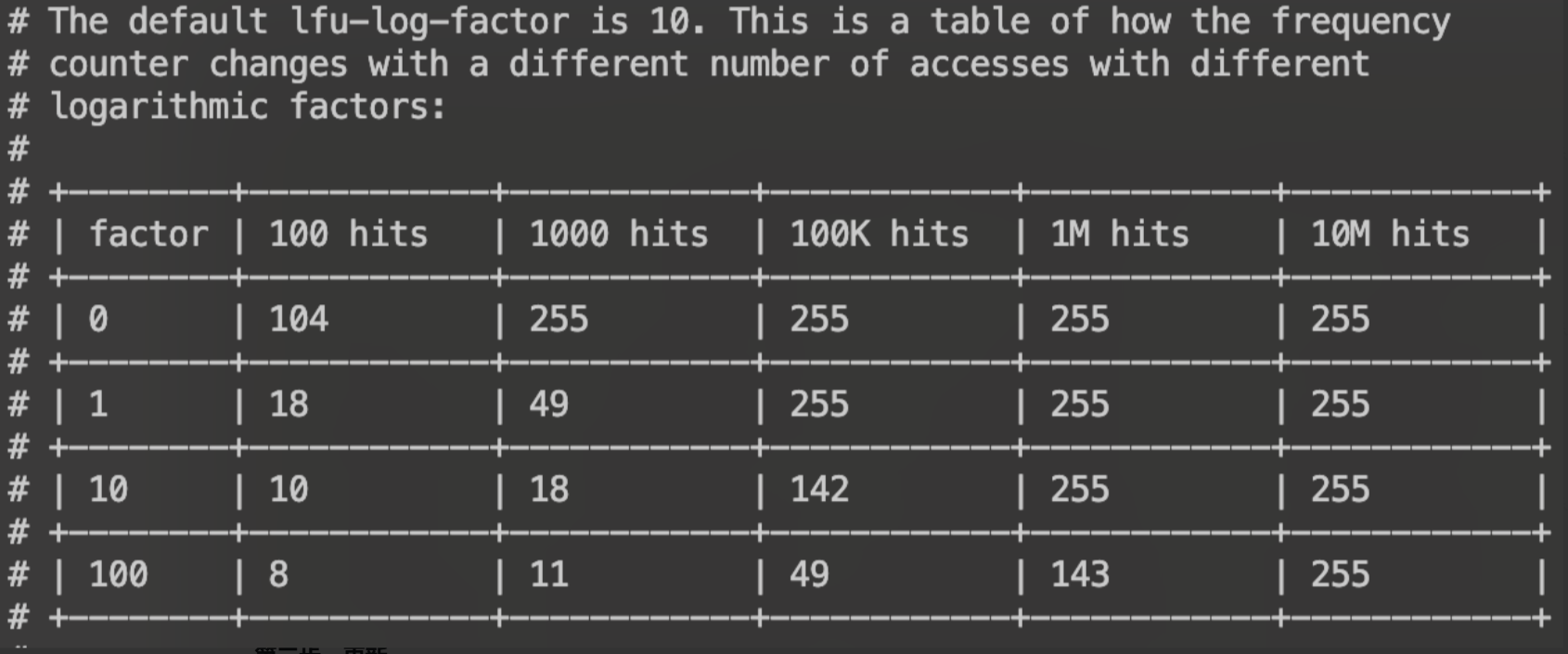
除了原来的次数影响之外,还有一个lfu-log-factor 参数可以被设置的。也就是说,可以通过lfu-log-factor参数来调节难度,这个越大,难度也越大,如果为0,那么每次必然+1,很快就能255,255[10]->1111 1111[2],255就是最大值。
此参数的默认值是10,需要1M流量才能达到最大值。
第三步,更新
当前时间更新到高16位,次数更新到低8位。
源码如下:
1 | /* Update LFU when an object is accessed. |
 微信
微信 支付寶
支付寶



