RedisTutorial01
Redis学习流程:对象、执行流程、持久化、场景、集群。本篇讲述第一部分:Redis的各种数据结构。
0.Why Redis?
相比与MySQL这种磁盘型的数据库,Redis是一款内存数据存储系统,所有数据采用键值对结构,以其卓越的性能和灵活性在现代应用架构中占据重要地位。它将数据直接存储在RAM中,提供毫秒级响应速度,同时支持多样化的数据结构(如后面要讲到的String、List、Hash、Set、ZSet等)。
在以前,Redis作为传统缓存层的首选技术充当请求与主数据库的缓冲。而现在,Redis不仅能够提供数据持久化保障,还支持JSON格式、高效搜索和对象映射功能,也能支持作为主数据库使用了。无论是自托管还是通过Redis Cloud服务使用,它都能为需要低延迟数据访问的应用场景(如缓存、会话管理、实时分析)提供理想解决方案,有效减轻主数据库负担并显著提升整体系统性能。
和之前语言的学习不同,对于Redis数据类型的讲解,我们都是应用方法+底层实现直接一锅端掉送走。在这里请注意仔细区分Redis数据类型和底层数据结构/编码的区别,如String和SDS的区别。
让我们先高屋建瓴地进行概述:
Redis 共有 5 种基本数据类型:String(字符串)、List(列表)、Set(集合)、Hash(散列)、Zset(有序集合)。
这 5 种数据类型是直接提供给用户使用的,是数据的保存形式,其底层实现主要依赖这 8 种数据结构:简单动态字符串(SDS)、LinkedList(双向链表)、Dict(哈希表/字典)、SkipList(跳跃表)、Intset(整数集合)、ZipList(压缩列表)、QuickList(快速列表)。
Redis 5 种基本数据类型对应的底层数据结构实现如下表所示:
| String | List | Hash | Set | Zset |
|---|---|---|---|---|
| SDS | LinkedList/ZipList/QuickList | Dict、ZipList | Dict、Intset | ZipList、SkipList |
Redis 3.2 之前,List 底层实现是 LinkedList 或者 ZipList。 Redis 3.2 之后,引入了 LinkedList 和 ZipList 的结合 QuickList,List 的底层实现变为 QuickList。从 Redis 7.0 开始, ZipList 被 ListPack 取代。
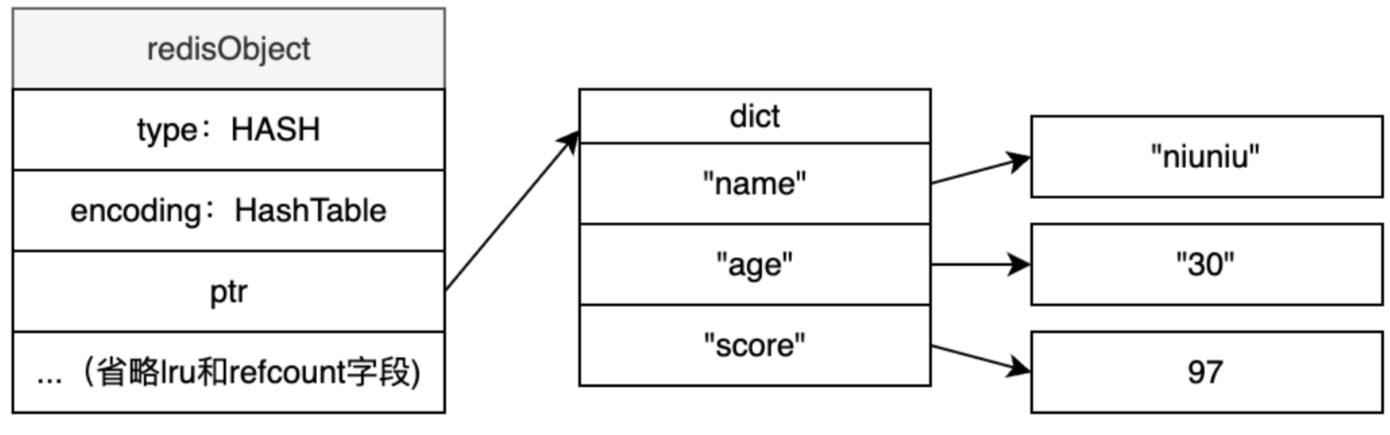
0.5 redisObject
Redis是key-value存储,key和value在Redis中都被抽象为对象,key只能是String对象,而Value支持丰富的对象种类,包括String、List、Set、Hash、Sorted Set、Stream等。
本部分的内容留个大概印象即可。

type:是哪种Redis对象
encoding:表示用哪种底层编码,用OBJECT ENCODING[key]可以看到对应的编码方式
lru:记录对象访问信息,用于内存淘汰,这个可以先忽略,后续章节会详细介绍。
refcount:引用计数,用来描述有多少个指针,指向该对象
ptr:内容指针,指向实际内容
1.String
String操作
String是Redis中最基本的数据类型,可以存储文本、整数或二进制数据。一个键最大能存储512MB的数据。
说到底,操作还是增删改查四个方面…
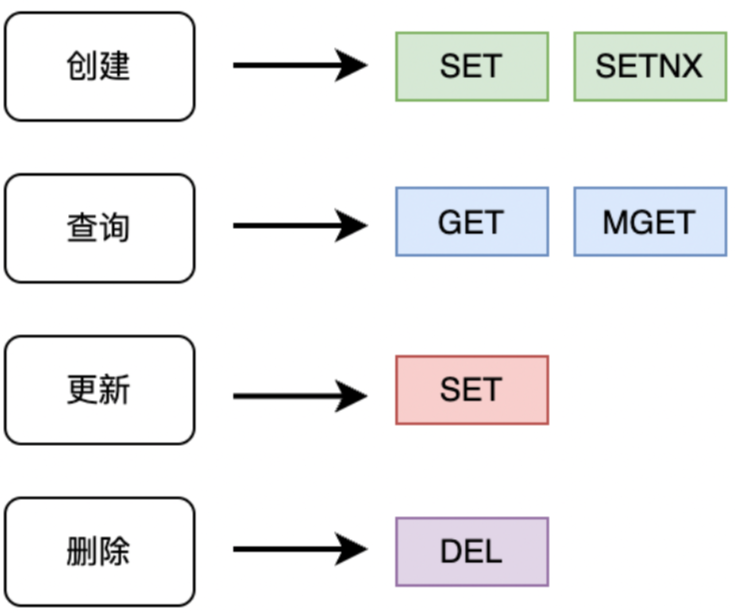
基本命令:
1 | # 创建 |
使用示例:
1 | # 创建操作 |
底层实现
String结构看起来很简单,但是实际上有三种编码方式:
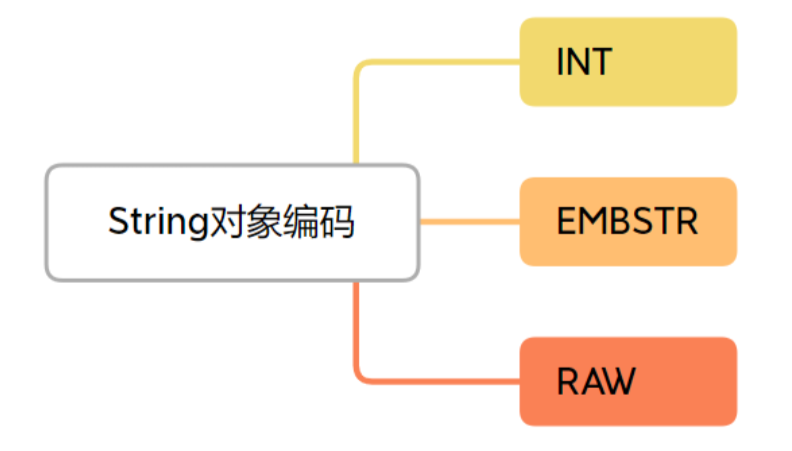
INT编码:这个很好理解,就是存一个整型,可以用long表示的整数就以这种编码存储;
EMBSTR编码:如果字符串小于等于阈值字节,使用EMBSTR编码;
RAW编码:字符串大于阈值字节,则用RAW编码。
这里的阈值字节在Redis3.2之前的版本是39,3.2以及之后的版本是44,原因这里不做探讨。
EMBSTR和RAW都是由redisObject和SDS两个结构组成,它们的差异在于,EMBSTR下redisObject和SDS是连续的内存,RAW编码下redisObject和SDS的内存是分开的。
EMBSTR优点是redisObject和SDS两个结构可以一次性分配空间,缺点在于如果重新分配空间,整体都需要再分配,所以EMBSTR设计为只读,任何写操作之后EMBSTR都会变成RAW,理念是发生过修改的字符串通常会认为是易变的。
那么EMBSTR和RAW内存的结构又是什么呢?请看:
EMBSTR内存结构:

RAW内存结构:
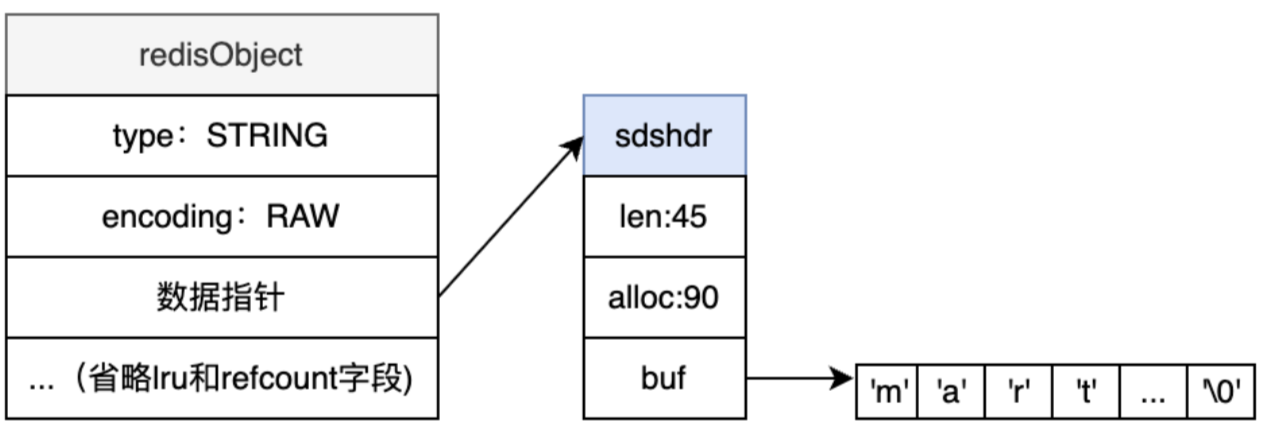
我们注意到,字符串编码EMBSTR和RAW都包含一个结构叫SDS,它是Simple Dynamic String的缩写,即简单动态字符串,这是Redis内部作为基石的字符串封装,十分重要,下面我们详细介绍下SDS。
为什么需要SDS?
在C语言中,字符串用一个”0”结尾的char数组表示,比如”hello 0kr” 即”hello 0kr\0”。然而
- 每次计算字符串长度的复杂度为O(N);
- 对字符串进行追加,需要重新分配内存;
- 非二进制安全(这里就是指在字符串中出现\0的情况)。
在Redis内部,字符串的追加和长度计算很常见,这两个简单的操作不应该成为性能的瓶颈,于是Redis封装了一个叫SDS的字符串结构,用来解决上述问题。下面我们来看看它是怎样的结构。
首先,Redis中SDS分为sdshdr8、sdshdr16、sdshdr32、sdshdr64,它们的字段属性都是一样,区别在于应对不同大小的字符串以节省内存开销。我们以sdshdr8为例:
1 | // from Redis 7.0.8 |
此结构中:
- len:表示已使用的字节数
- alloc:表示除头部和结束符外分配的字节数
- flags:SDS类型标志,低3位表示SDS类型(如SDS_TYPE_8),在代码中就是:
1 |
- buf[]:存储实际字符数据的数组(二进制存储,这使得Redis字符串可以处理任何类型的数据,而不仅限于文本)
于是我们能很清晰地看出SDS是如何解决上面三个问题的:
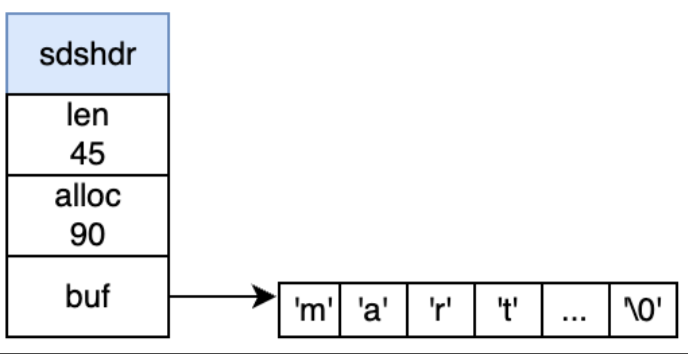
- 增加长度字段len,快速返回长度;
- 增加空余空间(alloc-len),为后续追加数据留余地;
- 不再以’\0’作为判断标准,二进制安全。
2.List
List是一个按照插入顺序排序的字符串链表。你可以添加元素到头部(左边)或尾部(右边)。一个列表最多可包含2^32 - 1个元素(超过40亿)。
List操作
基本命令:
1 | # 创建 |
使用示例:
1 | # 创建操作 |
这里需要解释一下DEL和UNLINK指令的区别:
del 命令同步删除命令,会阻塞客户端,直到删除完成。 unlink 命令是异步删除命令,只是取消Key在键空间的关联,让其不再能查到,删除是异步进行,所以不会阻塞客户端(相当于逻辑删除)。
底层实现
Redis的List在早期版本(3.2之前)使用两种数据结构:ziplist和linkedlist。在Redis 3.2之后,引入了quicklist作为List的统一实现:
- ziplist(压缩列表):当列表元素较少且元素值较小时使用
- linkedlist(双向链表):当列表元素多或元素值较大时使用
- quicklist(快速列表):结合了ziplist和linkedlist的优点,将linkedlist按段切分,每一段使用ziplist实现,相当于一个由ziplist组成的linkedlist
让我们分别介绍一下:
ZIPLIST
当满足如下条件时,用ZIPLIST编码:
- 列表对象保存的所有字符串对象长度都小于64字节;
- 列表对象元素个数少于512个,注意,这是LIST的限制,而不是ZIPLIST的限制。
ZIPLIST底层用压缩列表实现,这里我们假设列表中包含”hello”、”niuniu”、”mar”三个元素,ZIPLIST编码示意如下:
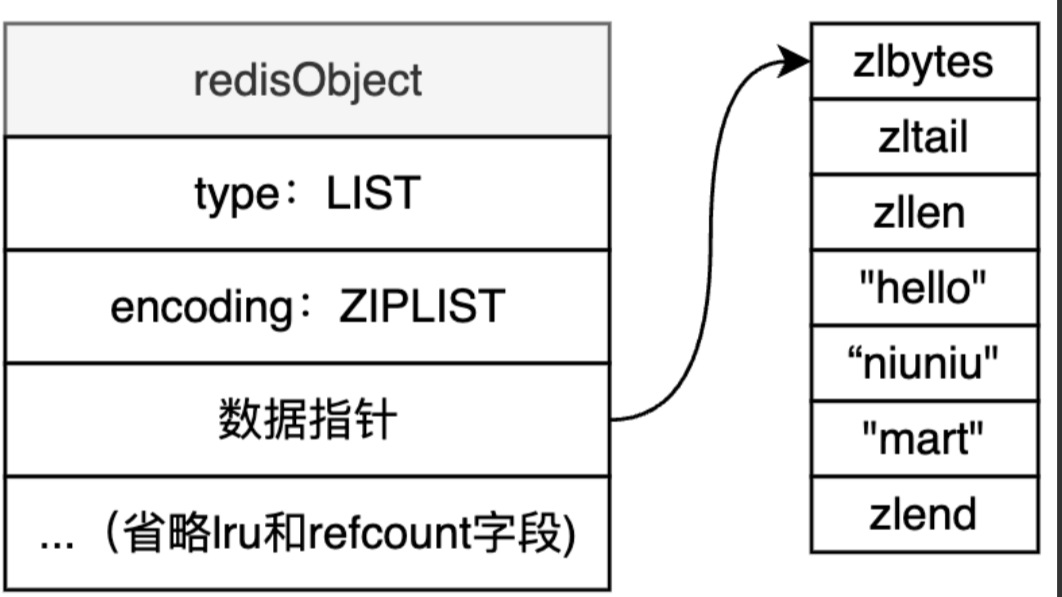
- zlbytes:表示该ZIPLIST一共占了多少字节数,这个数字是包含zlbytes本身占据的字节的。
- zitail: ZIPLIST 尾巴节点 相对于 ZIPLIST 的开头(起始指针)偏移的字节数。通过这个字段可以快速定位到尾部节点,例如现在有一个 ZIPLIST,z| 指向它的开头,如果要获取 tail 尾巴节点,即 ZIPLIST 里的最后一个节点可以 zl + zltail的值,这样定位到它。如果没有尾节点,就定位到 zlend。
- zllen:表示有多少个数据节点,在本例中就有3个节点。
- entry1~entry3:表示压缩列表数据节点。
- zlend:一个特殊的entry节点,表示ZIPLIST的结束。
这里的每一个entry又是由下面三个部分组成:
1 | <prevlen> <encoding> <entry-data> |
同样的,我们来看看,各字段的含义:
- prevlen:表示上一个节点的数据长度。通过这个字段可以定位上一个节点的起始地址——换言之,prevlen 可以跳到前一个节点的开头位置,实现从后往前操作,所以压缩列表才可以从后往前遍历。
- encoding:编码类型。编码类型里还包含了一个entry的长度信息,可用于正向遍历。
- entry-data:实际的数据。
如果前一节点的长度,也就是前一个ENTRY的大小,小于254字节,那么prevlen属性需要用1字节长的空间来保存这个长度值,(255是特殊字符,被zlend使用了.)
如果前一节点的长度大于等于254字节,那么prevlen属性需要用5字节长的空间来保存这个长度值,注意5个字节中的第一个字节为11111110,也就是254,标志这是个5字节的prevlen信息,剩下4字节来表示大小。
连锁更新问题
连锁更新(cascading update)问题发生在以下场景:
ZIPLIST使用可变长度编码来存储元素长度,长度编码可能占用1或5个字节。当一个元素的长度发生变化,可能导致其长度编码字节数也发生变化。
当长度编码字节数增加时,会导致后续所有元素位置发生偏移,这种偏移可能导致其他元素的长度编码也需要调整。在最坏情况下,一个元素的变化会引发整个ZIPLIST的所有元素需要重新定位。这就是连锁更新的问题。
为了解决这个问题,我们需要一种不记录prevlen,并且还能找到上一个节点的起始位置的办法,Redis使用了很巧妙的一种方式:LISTPACK。
LISTPACK
LISTPACK的内存布局大致如下:
1 | <total-bytes><num-elements><element-1>...<element-N><end-mark> |
每个元素的格式为:
1 | <encoding-type> <element-data> <element-tot-len> |
其中:
- encoding-type: 表示数据的编码类型(如整数、字符串等)
- element-data: 实际存储的数据内容
- element-tot-len: 记录整个节点的总长度(不包括自身)
在LISTPACK中,向后遍历很简单,因为我们知道每个节点的长度,可以直接跳到下一个节点。但向前遍历就有挑战性,因为我们需要知道前一个节点的起始位置。
Redis采用了一个巧妙的设计:在element-tot-len字段中,每个字节的最高位(第一个bit)用作标记位:
0表示这是结束字节
1表示还有后续字节
当我们需要向前遍历时,可以按照以下步骤:
- 从当前位置向前查找,检查每个字节的最高位
- 找到最高位为0的字节,这标志着前一个节点的
element-tot-len字段的结束 - 基于
element-tot-len的值,计算出前一个节点的起始位置
举例
假设某个节点的element-tot-len值为132(二进制:10000100),需要两个字节存储:
- 第一个字节:00000001(最高位为0,表示这是结束字节)
- 第二个字节:10000100(最高位为1,表示这是继续字节)
向前遍历时:
- 从当前位置向前扫描,查找最高位为0的字节(00000001)
- 读取完整的长度值:00000001 10000100 = 132
- 从当前位置减去132,就得到了前一个节点的起始位置
通过这样的设计,当一个节点的大小变化时,只需修改该节点本身。后续节点不存储关于前一个节点的长度信息,因此不会因为前一个节点的变化而需要更新。
总结
本质区别在于信息依赖关系:
- ZIPLIST:节点A存储节点B的长度信息 → 节点B变化 → 节点A需要更新
- LISTPACK:节点只存储自身信息 → 节点变化 → 只修改自身,不影响其他节点
即使LISTPACK需要从后向前遍历(通过检查字节的最高位来识别长度字段的结束),这种设计也不会导致连锁更新问题,因为每个节点的变化仍然是局部的、独立的。
LINKEDLIST
回到正文。如果不满足ZIPLIST编码的条件,则使用LINKEDLIST编码。为了便于描述,我们还是假设列表含”hello”、”niuniu”、”mart”三个元素,如果用LINKEDLIST编码,则是几个String对象的链接结构,结构示意图如下:
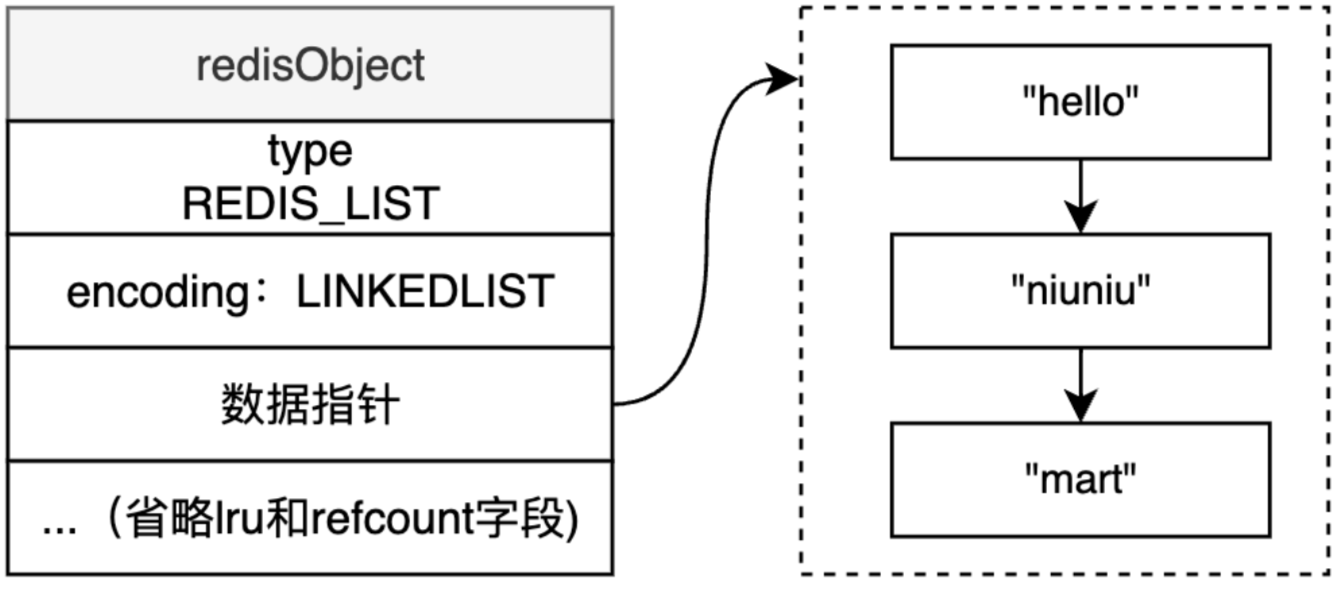
可以看到,”hello”、”niuniu”、”mart”这几个数据是以链表的形式连接在一起,实际上删除更为灵活,但是内存不如ZIPLIST紧凑,所以只有在列表个数或节点数据长度比较大的时候,才会使用LINKEDLIST编码,以加快处理性能,一定程度上牺牲了内存。
QUICKLIST
上面的分析有说到,ZIPLIST是为了在数据较少时节约内存,LINKEDLIST是为了数据多时提高更新效率,ZIPLIST数据稍多时插入数据会导致很多内存复制。
但如果节点非常多的情况,LINKEDLIST链表的节点就很多,会占用不少的内存。
为了解决上面的问题引入了QUICKLIST。

这种方案其实是用ZIPLIST、LINKEDLIST综合的结构,取代二者本身。
- 当数据较少的时候,QUICKLIST的节点就只有一个,此时其实相当于就是一个ZIPLIST;
- 当数据很多的时候,则同时利用了ZIPLIST和LINKEDLIST的优势。
3.Set
Set是一个无序且唯一的字符串集合。可以进行交集、并集、差集等集合运算。
Set操作
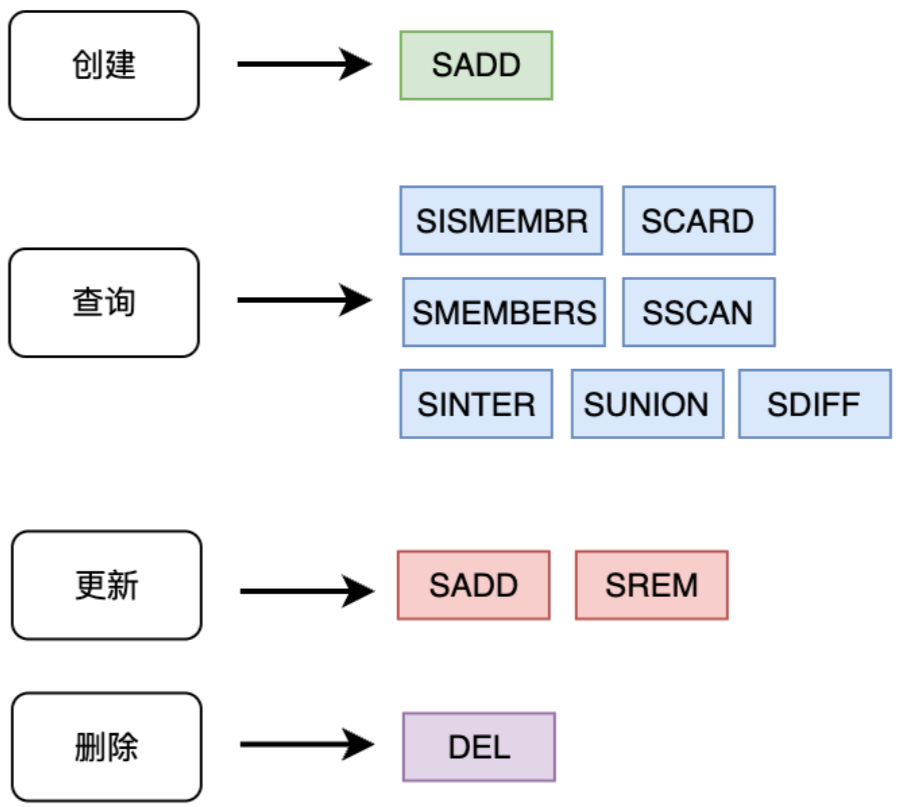
基本命令:
1 | # 创建 |
使用示例:
1 | # 创建操作 |
底层实现
Redis的Set在底层使用两种数据结构实现:
- intset(整数集合):当集合中的元素都是整数且元素数量较少时使用
- hashtable(哈希表):当集合中包含非整数元素或元素数量较多时使用
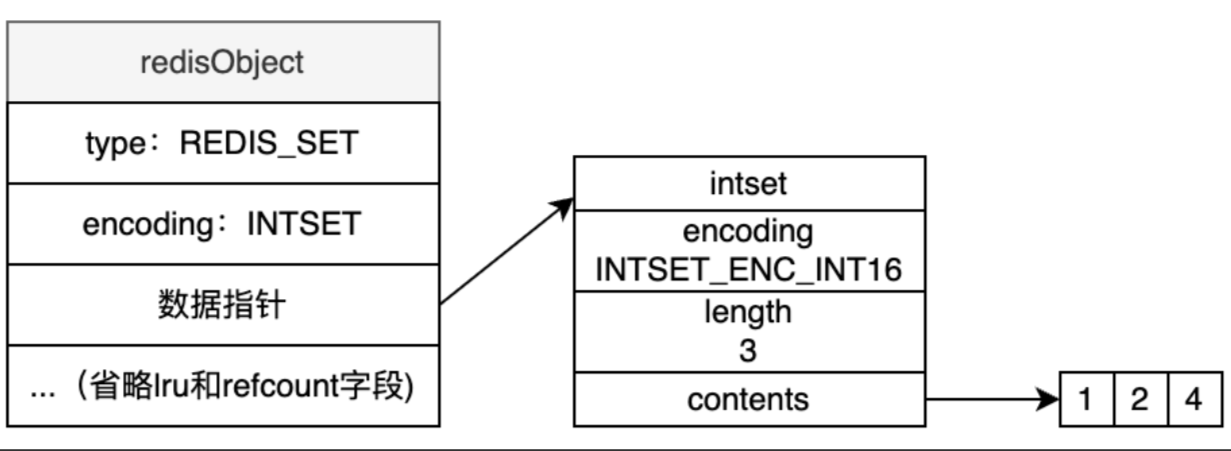
如果集合元素都是整数,且元素数量不超过512个,就可以用INTSET编码,结构如下图,可以看到INTSET排列比较紧凑,内存占用少,但是查询时需要二分查找。
如果不满足INTSET的条件,就需要用HASHTABLE,HASHTABLE结构如下图,可以看到HASHTABLE查询一个元素的性能很高,能O(1)时间就能找到一个元素是否存在。
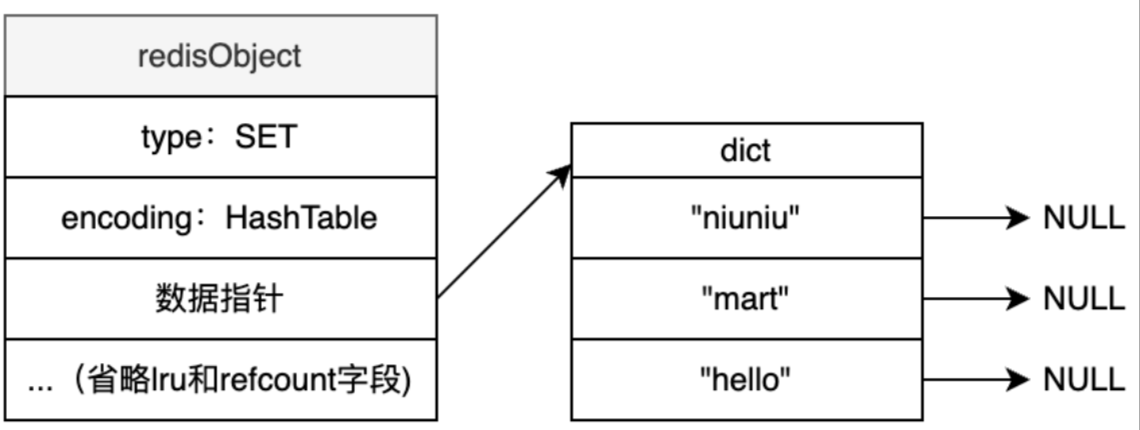
4.Hash
Redis Hash是一个field、value都为string的hash表,类似于编程语言中的Map或Dictionary类型。
每个hash可以存储2^32 - 1个键值对。
Hash操作
基本命令:
1 | # 创建 |
使用示例:
1 | # 创建操作 |
底层实现
Redis的Hash类型底层实现使用了两种数据结构:
- ziplist(压缩列表):当哈希表元素较少且元素值较小时使用(当然,新版本已经替换成LISTPACK)
- hashtable(哈希表):当哈希表元素较多或元素值较大时使用
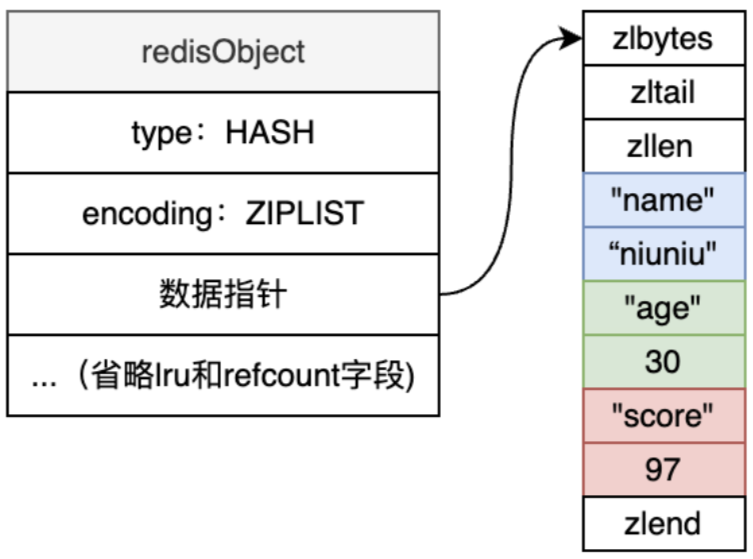
老样子,同时满足以下两个条件,用压缩列表:
- Hash对象保存的所有值和键的长度都小于64字节,
- Hash对象元素个数少于512个。
两个条件任何一条不满足,编码结构就用HASHTABLE。在之前无序集合Set中也有应用,和Set的区别在于,在Set中value始终为NULL,但是在Hash中,是有对应的值的。
由于HASHTABLE是面试的超级大热门,所以我们在这里也深究一下其中的原理。
HASHTABLE
Redis中HASHTABLE的结构如下:
1 | // from Redis 5.0.5 |
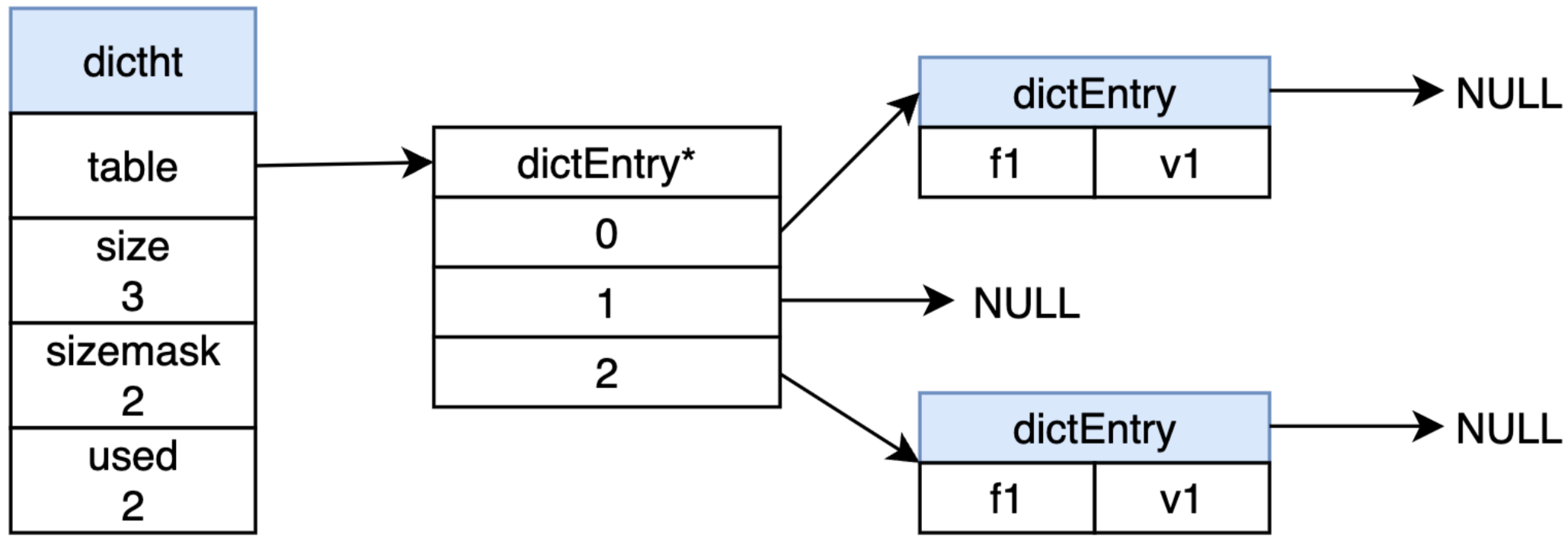
最外层是一个封装的dictht结构,其中字段含义如下:
- table:指向实际hash存储。
- size:哈希表大小。实际就是dictEntry有多少元素空间。
- sizemask:哈希表大小的掩码表示,总是等于
size-1。这个属性和哈希值一起决定一个键应该被放到table数组的哪个索引上面,规则Index=hash&sizemask - used:表示已有节点数量。
所以说查询HASHTABLE节点总数的时间复杂度是O(1),因为表头是有记录的。
接下来的重点是HASHTABLE的扩容、缩容和发生的时机。
扩容时机
- 负载因子过高:当哈希表的负载因子(used/size)超过1时,意味着平均每个bucket已经有至少一个元素,此时会触发扩容。通常情况下,当负载因子大于等于1时,会将哈希表的大小扩大为原来的两倍。
- 强制扩容:在没有开启自动rehash的情况下(如载入大量数据时),如果负载因子超过5,则强制执行rehash。
缩容时机
当负载因子小于0.1时,即哈希表中的元素数量不足哈希表大小的10%,会触发缩容操作,将哈希表大小缩小为当前使用量的一倍大小(used*2),以节省内存空间。
渐进式rehash过程
Redis的渐进式rehash分为以下几个步骤:
- 分配新哈希表:为字典的ht[1]分配空间,大小由扩容或缩容决定。
- 维护rehash标志:设置rehashidx为0,表示rehash工作正在进行。
- 渐进迁移:rehash不是一次性完成的,而是分多次、渐进式完成的:
- 在对字典执行添加、删除、查找或更新操作时,顺便将ht[0]中rehashidx索引上的所有键值对rehash到ht[1]
- 每完成一次rehash,rehashidx值+1
- 系统会在定时任务中执行rehash,每次最多执行1毫秒
- 完成rehash:当ht[0]的所有键值对都迁移到ht[1]后,将rehashidx设置为-1,并将ht[1]设置为ht[0],ht[1]重新初始化为空表
渐进式rehash的好处
- 避免阻塞:由于Redis是单线程模型,一次性rehash可能导致服务暂停响应。渐进式rehash将这个过程分散到多次操作中,减少了单次操作的时间消耗。
- 平滑性能:将rehash操作分摊到平时的各个增删改查操作中,使得服务器性能更加平稳,避免了突然的性能抖动。
在渐进式rehash过程中,字典的删除、查找、更新等操作会在两个哈希表上进行,而新增操作只会添加到ht[1]。这种设计保证了在rehash过程中服务依然可以正常运行,用户几乎感知不到rehash过程的存在。
5.ZSet
ZSet(Sorted Set,有序集合)是一个有序且唯一的字符串集合。与Set不同,ZSet中的每个成员都关联一个分数(score),Redis通过分数来为集合中的成员进行从小到大的排序。
ZSet操作
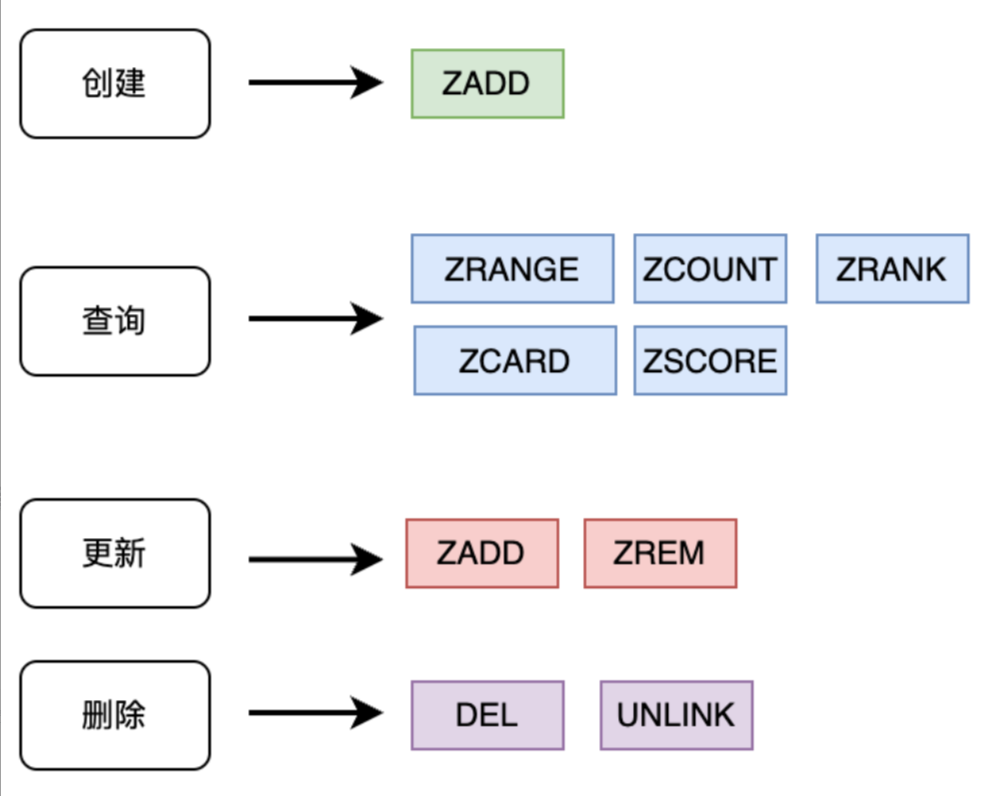
基本命令:
1 | # 创建 |
使用示例:
1 | # 创建操作 |
底层实现
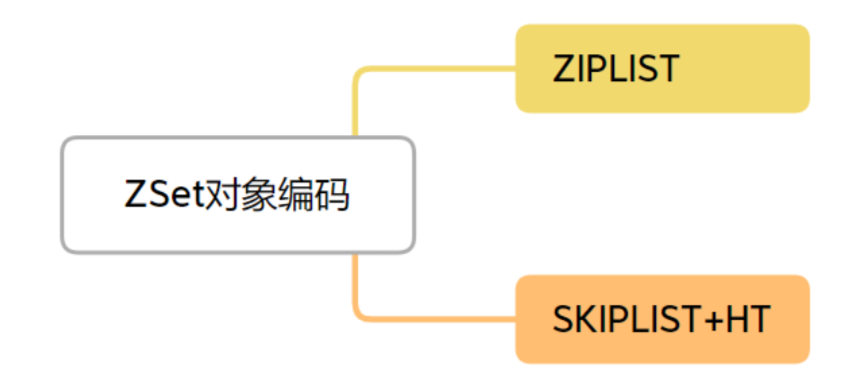
Redis的ZSet是一个复合结构,底层同时使用了两种数据结构:
- ziplist(压缩列表):当有序集合的元素数量较少且元素值较小时使用
- skiplist(跳表)+ hashtable(哈希表):当有序集合的元素数量较多或元素值较大时使用
ziplist不必多说,之前List、Hash中都有打过交道,同样在,在ZSet中ZIPLIST也是用于数据量比较小时候的内存节省,结构如下:

如果满足如下规则,ZSet就用ZIPLIST编码:
- 列表对象保存的所有字符串对象长度都小于64字节;
- 列表对象元素个数少于128个。
两个条件任何一条不满足,编码机构就用SKIPLIST+HASHTABLE,其中SKIPLIST也是底层数据结构,是本节才出现的新伙伴。
SKIPLIST是一种可以快速查找的多级链表结构,通过SKIPLIST可以快速定位到数据所在。它的排名操作、范围查询性能都很高,在前面的章节,我们已经介绍过SKIPLIST,如果有所遗忘的同学,可以回过头去看一下。
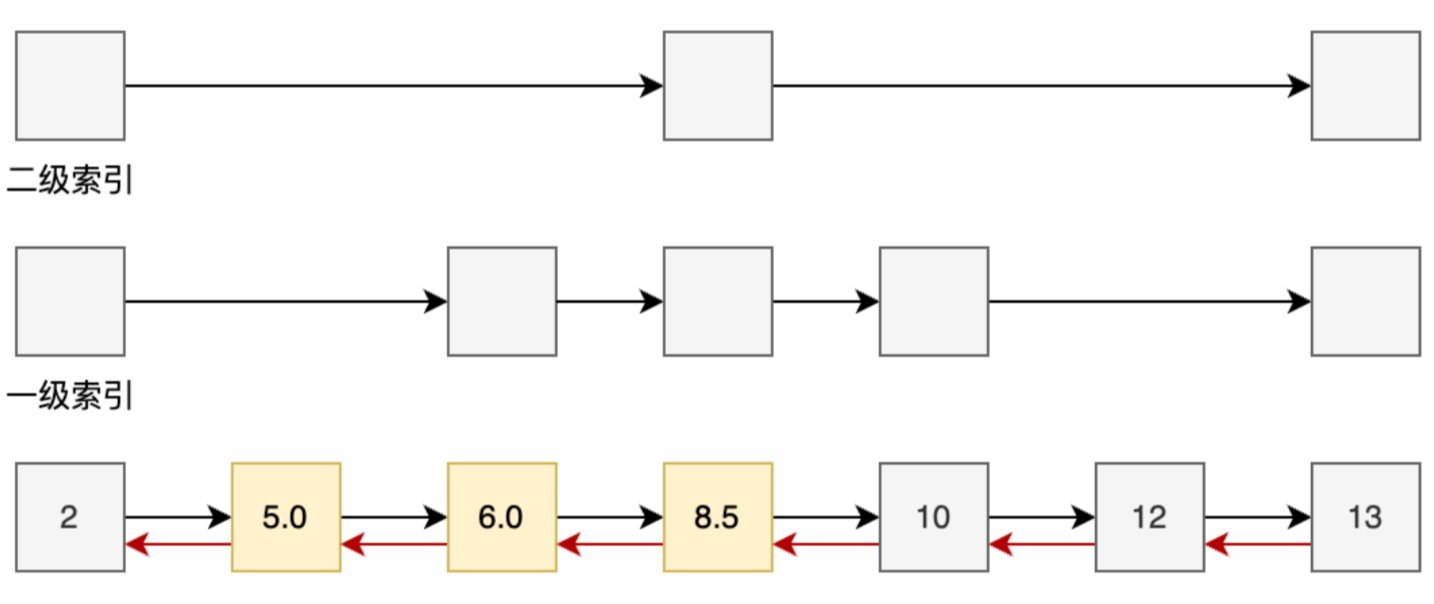
除了SKIPLIST,Redis还使用了HASHTABLE来配合查询,这样可以在O(1)时间复杂度查到成员的分数值。
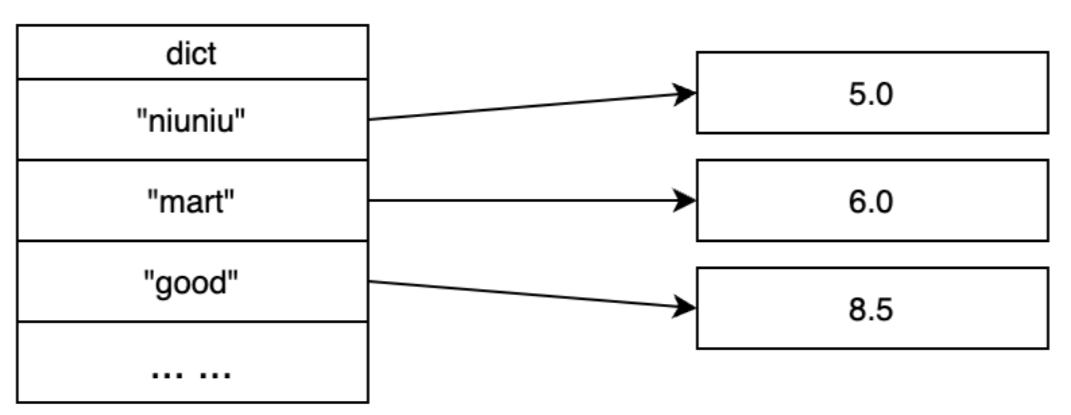
所以你知道的,接下来我们必须详细地介绍一下跳表。
跳表
跳表是什么
跳表本质上还是链表,普通链表结构如下:
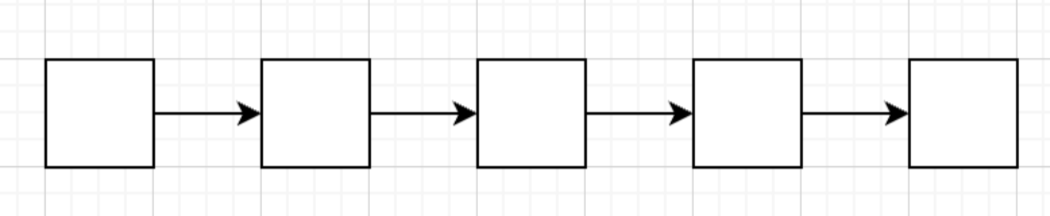
这种结构虽然简单清晰,但是查询某个节点的效率比较低,而在有序集合场景,无论是查找还是添加删除元素,我们是需要能快速通过score定位到具体位置,如果用链表那时间复杂度其实就是O(N),N是节点个数。
为了提升查找的性能,Redis就引入了跳表,跳表在链表的基础上,给链表增加了多级的索引,通过索引可以一次实现多个节点的跳跃,提高性能。
跳表的结构
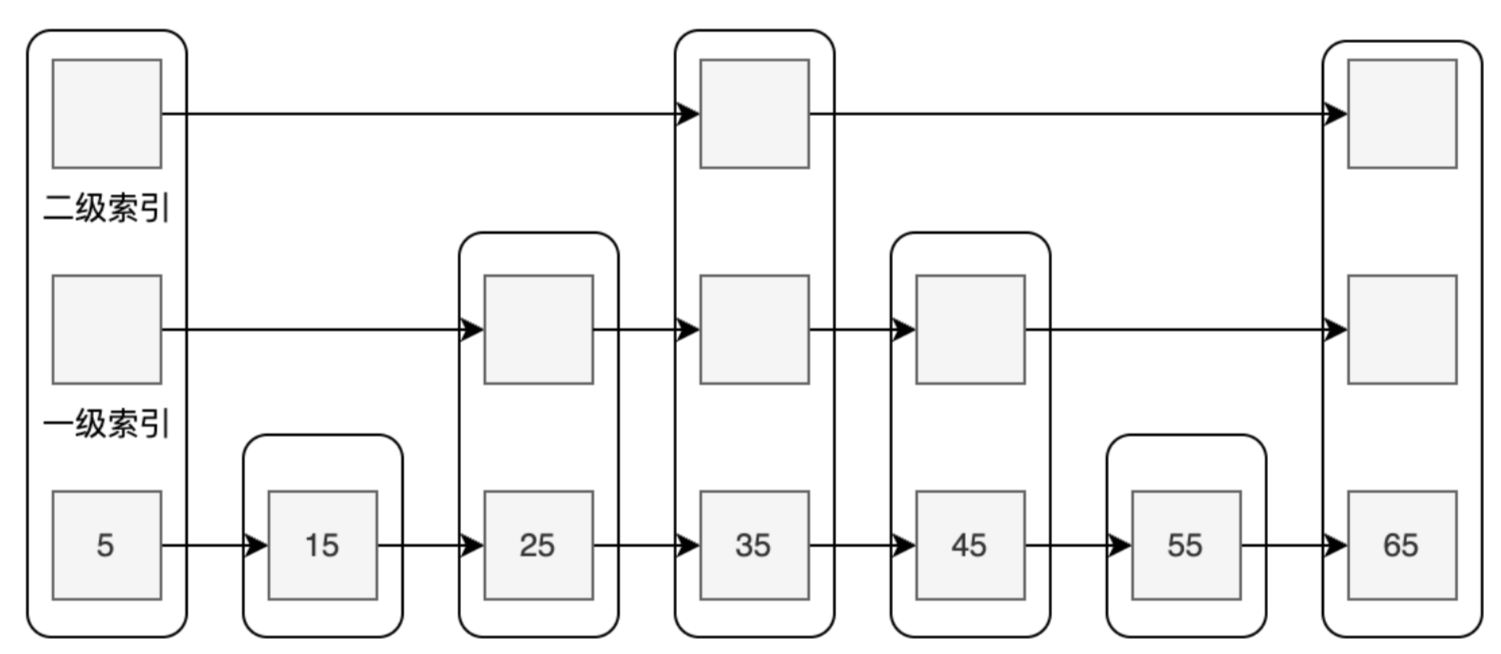
我们分几个场景来分析。
- 场景一:查找分数为45的数据
如果只有原始的链表,那需要走4步,如果有图中的二级索引,只用走2步;
其实就是从第1个节点出发,通过二级索引走到35,再查看到下一个节点是65,已经超过了,所以降低到下方的索引,也就是一级索引,往后走一次就可以找到45。
- 场景二:插入一条score为36的数据
首先,定位到第一个比score大的位置,这里是45,定位方式和查询类似,不再赘述。
然后,构造一个新的节点(这里我们假设节点层高随机到3,具体随机算法我们后面会介绍,目前不用太关注)。
最后,将各层链表补齐,其实就是在每一层进行链接,效果如图:
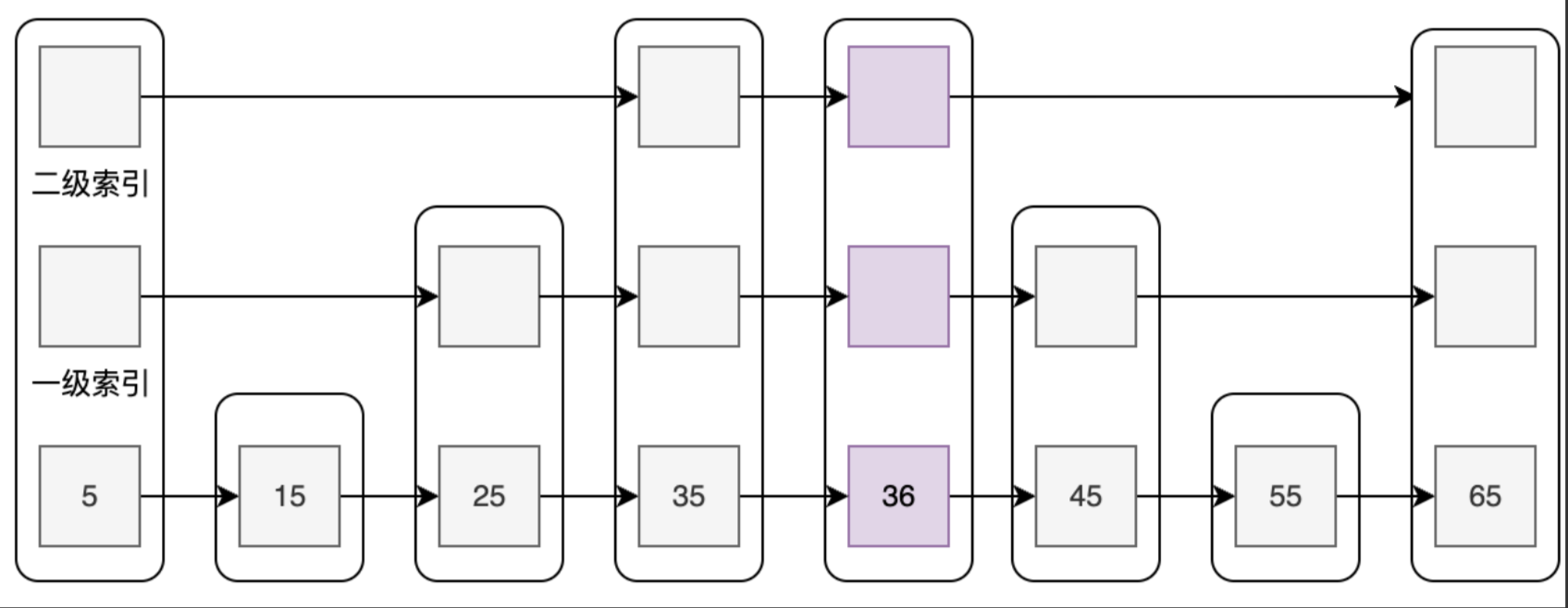
Redis跳表实现与源码解析
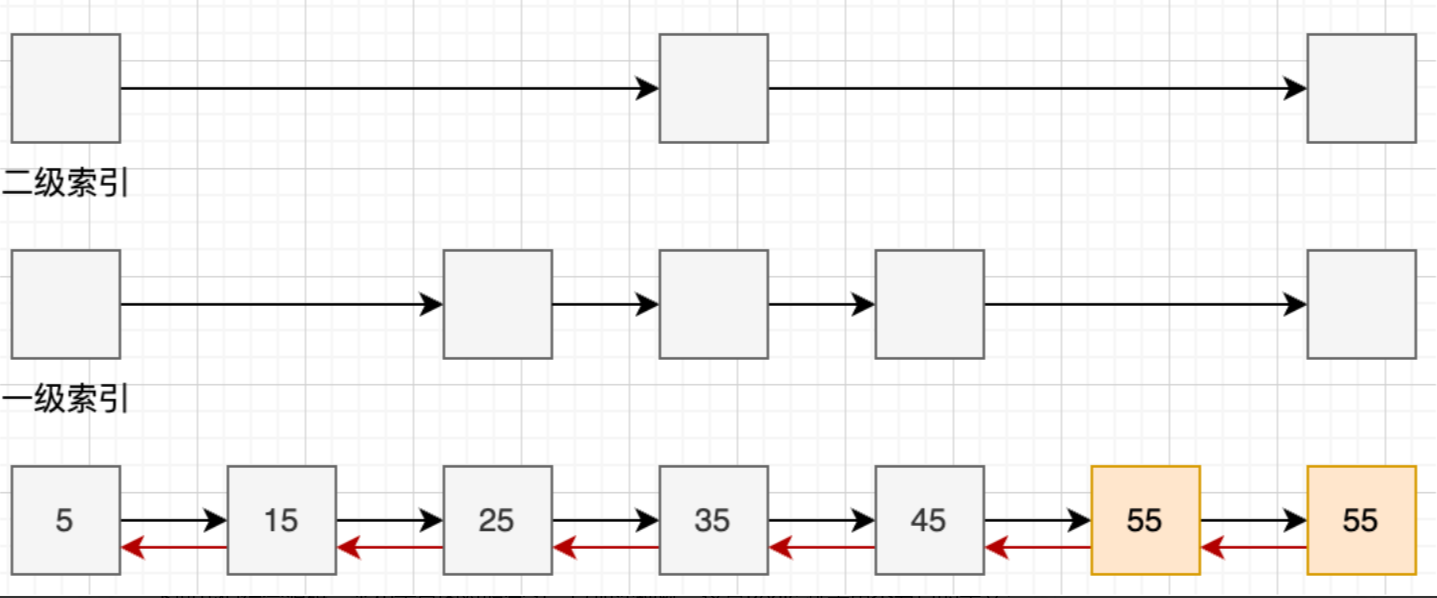
标准的跳表中,score分数值是不可以重复的,并且只有向前指针没有回退指针。Redis对以上两点做了改进,这使得其能够很方便地完成一些业务上的功能,比如排行榜中相同分数的用户以及倒序遍历等等。
这是Redis 跳表单个节点的定义:
1 | // from Redis 7.0.8 |
我们来看看字段的含义:
- ele:很熟悉的SDS结构,用来存储数据。
- score:节点的分数,浮点型数据
- backward:指向上一个节点的回退指针,支持从表尾向表头遍历,也就是ZREVRANGE这个命令
- level:是个zskiplistLevel结构体数组,zskiplistLevel这个结构体包含了两个字段,一个是forward,指向该层下个能跳到的节点,span记录了距离下个节点的步数,数组结构就表示每个节点都可能是个多层结构。
结合这张图能够更好地理解:
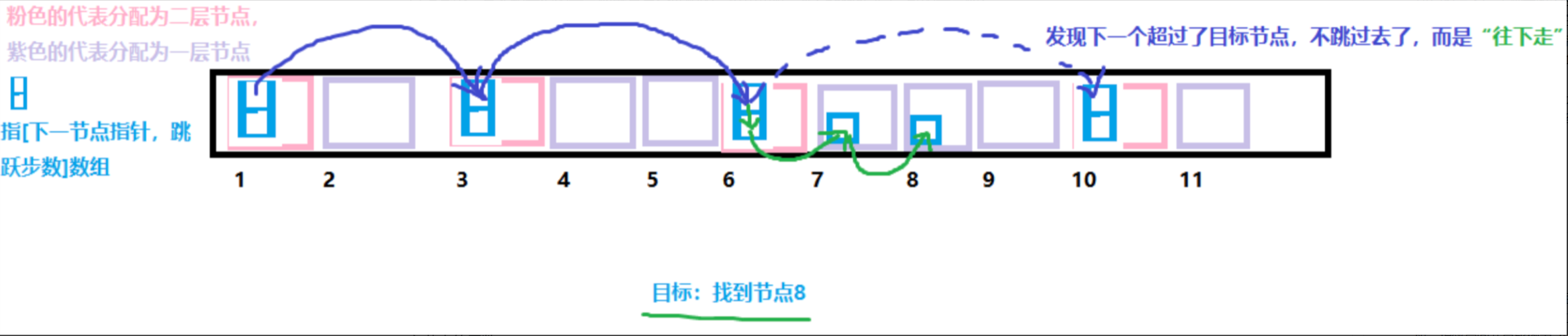
总而言之,就是从高级索引往后查找,如果下个节点的数值比目标节点小,则继续找,否则不跳过去,而是用下级索引往下找。
还有几个关键的问题:
Redis跳表单个节点有几层?
层次的决定,需要比较随机,才能在各个场景表现出较为平均的性能,这里Redis使用概率均衡的思路来确定新插入节点的层数:
Redis 跳表决定每一个节点,是否能增加一层的概率为25%,而最大层数限制在Redis 5.0是64层,在Redis 7.0是32层。
Redis跳表的性能优化了多少?
这个其实可以很容易想到,跳表的查找过程,其实是走高层,行得通跳过去,行不通走相对下层,很像二叉树的另种表现形式,实际上他们性能也是差不多的,平均时间复杂度都是O(logn),区别是二叉树最坏情况下也是O(logn)比较稳定,而跳表的最坏时间复杂度是O(N)。当然,实际的生产过程中,体现出来的基本都是跳表的平均时间复杂度。
前面也提到,有序集合无论是査找、还是增加删除元素,都是需要先定位到数据位置,所以跳表将这三个操作的时间复杂度,都从O(N)降低到了Iog(N)。
个人理解:ZSCORE这种单值查询可以用HASHTABLE,ZRANK这种范围查询可以用跳表。
总结
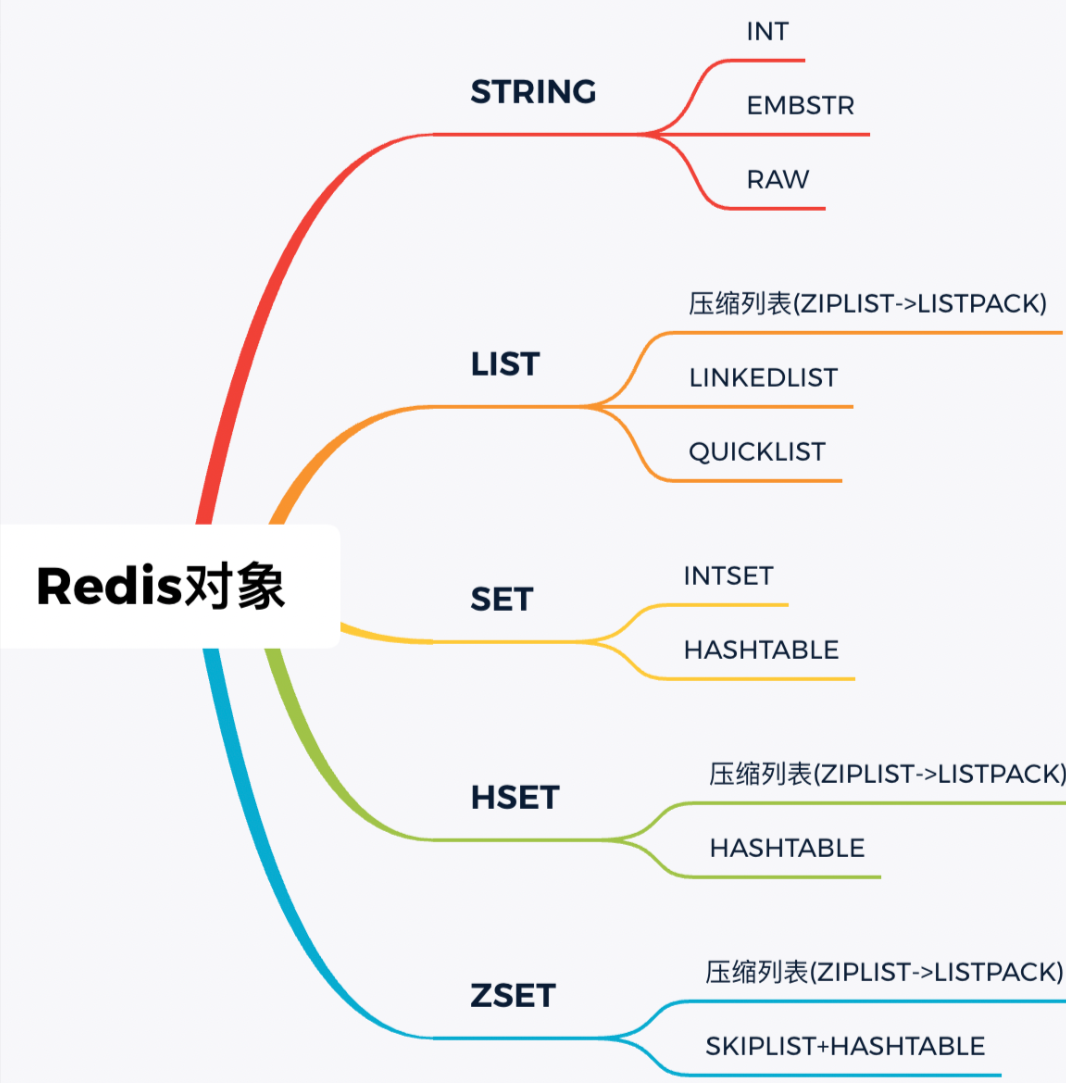
Redis五种基本数据类型各有其特点和适用场景:
- String:适用于缓存简单数据、计数器、分布式锁等
- List:适用于消息队列、最新消息列表等
- Set:适用于去重、交集运算(共同好友)等
- Hash:适用于存储对象、用户信息等
- ZSet:适用于排行榜、优先级队列等
理解这些数据类型的底层实现有助于我们更高效地使用Redis,根据实际场景选择最合适的数据结构。Redis的优秀性能很大程度上得益于其精心设计的数据结构和算法。
 微信
微信 支付寶
支付寶



