RedisTutorial03
Redis数据持久化
持久化介绍
持久化是什么
Redis是跑在内存里的,当程序重启或者服务崩溃,数据就会丢失,如果业务场景希望重启之后数据还在,就需要持久化,即把数据保存到可永久保存的存储设备中。
持久化方式
Redis提供两种方式来持久化:
1.RDB(Redis Database Backup),记录Redis某个时刻的全部数据,这种方式本质就是数据快照,直接保存二进制数据到磁盘,后续通过加载RDB文件恢复数据。
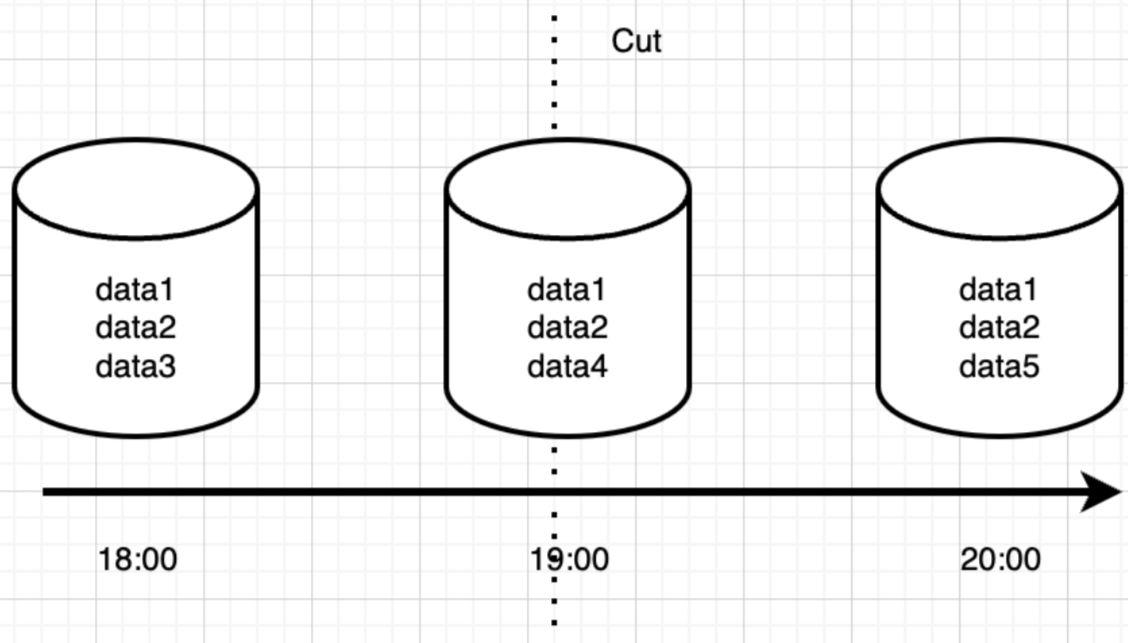
2.AOF(Append Only File),记录执行的每条写命令,重启之后通过重放命令来恢复数据,AOF本质是记录操作日志,后续通过日志重放恢复数据。

RDB是快照恢复,AOF是日志恢复,这是两者本质区别,我们甚至都不用去学习他们具体的实现,也能推测出他们如有下差别:
- 体积方面:相同数据量下,RDB体积更小,因为RDB是记录的二进制紧凑型数据
- 恢复速度:RDB是数据快照,可以直接加载,而AOF文件恢复,相当于重放情况,RDB显然会更快
- 数据完整性:AOF记录了每条日志,RDB是间隔一段时间记录一次,用AOF恢复数据通常会更为完整。
等我们在后面两节进一步学习RDB、AOF之后,我们还会分析出更多优点缺点。
如果业务本身只是缓存数据且并不是一个海量访问,可以不用开持久化。如果对数据非常重视,可以同时开启RDB和AOF,同时开启的情况下RDB只是个备份,实际用的是AOF来进行加载,这里用AOF而不用 RDB 去恢复数据的原因是:你开启 了AOF,表明要强一点的一致性,那就不会用RDB来加载,因为可能 RDB 会少更多的数据。RDB只是在AOF文件出现损坏时作为备份使用。
如果可以接受丢几分钟级别的数据,那么建议只开RDB。单独开AOF,Redis官方不建议,因为如果决定要走数据备份,那么镜像保存始终是数据库领域非常行之有效的解决方案,所以在配置中RDB是默认打开的,而AOF不是。
这里也说下为什么RDB是几分钟才做一次持久化:虽然可以通过fork出的子进程来做全量快照,但是如果每一秒一次,会导致很大的性能开销,可能这一秒的快照都没完成,下一秒又fork出一个子进程来做快照,所以RDB的快照触发间隔是比较难确定的,原则上就是不能太短,一般都是几分钟以上。
RDB
持久化配置
在Redis的配置文件中(windows系统里是redis.windows.conf),通过搜索很容易就能找到如下内容:

这就是Redis的RDB持久化策略。这里的配置语法是save interval num,表示每间隔interval秒,至少有num条写数据操作,写数据操作指增加、删除及更新,就会激活RDB持久化。
上面有3条save配置,他们的意思分别是:
- 每900s,有1条写数据操作;
- 每300s,有10条写数据操作;
- 每60s,有10000写数据操作。
他们之间是并集关系,即只要满足其中一个条件,就达到了RDB持久化的条件。
这里一旦满足条件,就会在后台触发background save(bgsave,这里注意和主动触发的bgsave命令区分),redis会fork出一个进程对数据库备份,防止阻塞。
下面的参数决定了文件会存到哪里:

RDB文件最终会长这个样子,是二进制文件,没有可读性,但是要注意到前面有个REDIS字符串作为标记,这个后面讲混合持久化时也会用到。

触发时机
一共是四种:
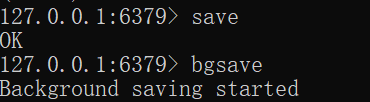
1.主动执行命令save
执行了 save 命令,就会在主线程生成 RDB 文件,由于和执行操作命令在同一个线程,所以如果写入 RDB 文件的时间太长,会阻塞主线程,这个命令慎用。
2.主动执行命令bgsave
和save不同,bgsave会创建一个子进程来生成 RDB 文件,这样可以避免主线程的阻塞。
3.达到持久化配置阈值
上面有提到,Redis可以配置持久化策略,达到策略就会触发持久化,这里的持久化使用的方式是bgsave,从这可以看到Redis比较推荐的方式也是后台执行持久化,尽可能减少对主流程影响。达到阈值之后,是由周期函数触发持久化。
也就是说,serverCron 这个周期函数,默认每 100ms执行一次,检查 save 设置的条件是否有满足,满足的话就触发 bgsave。如果修改次数以及事件都超过了,触发 bgsave
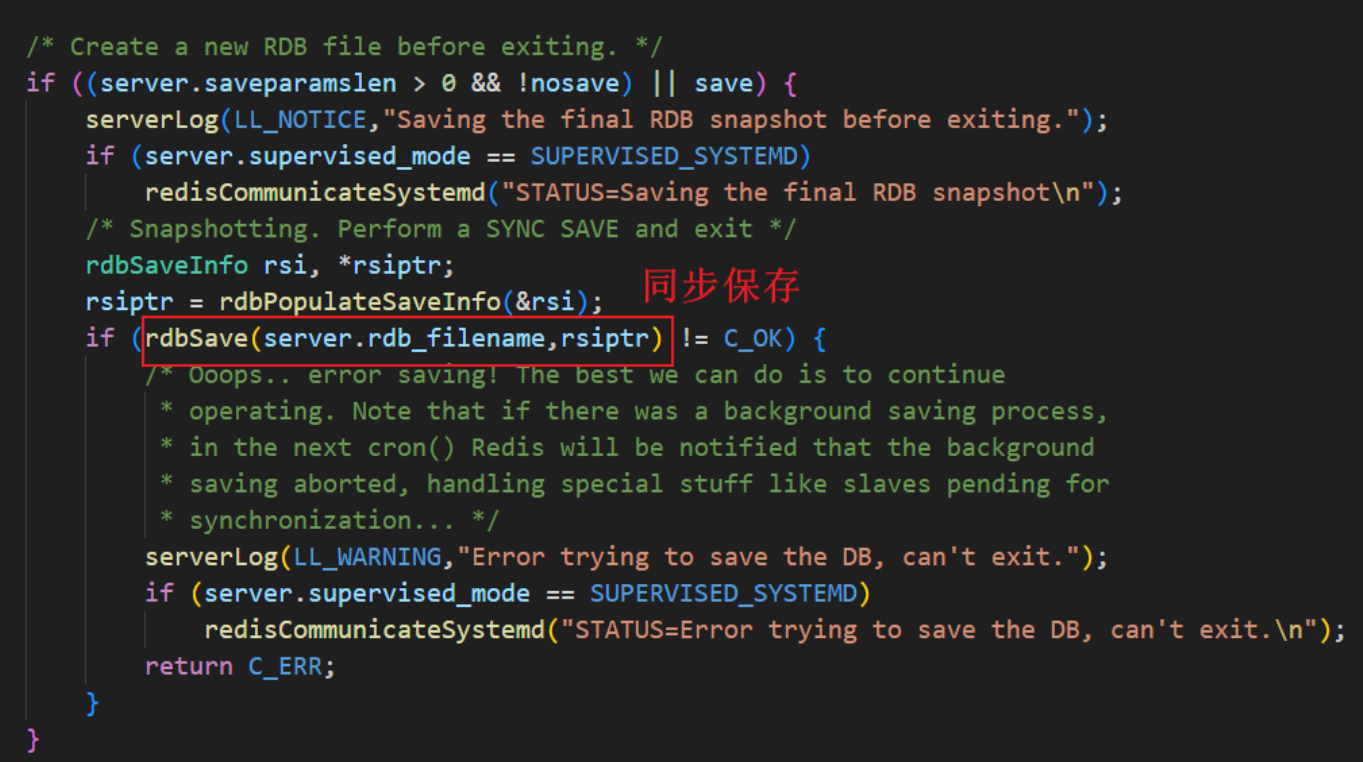
4.在程序正常关闭的时候执行
在关闭时,Redis会启动一次阻塞式持久化(触发save),以记录更全的数据。
备份方法
官网上的原文是这样的:
How it works
Whenever Redis needs to dump the dataset to disk, this is what happens:
1.Redis forks. We now have a child and a parent process.
2.The child starts to write the dataset to a temporary RDB file.
3.When the child is done writing the new RDB file, it replaces the old one.This method allows Redis to benefit from copy-on-write semantics.
从整体上,是做了以下事项
1.Fork出一个子进程来专门做RDB持久化
2.子进程写数据到临时的RDB文件
3.写完之后,用新RDB文件替换日的RDB文件
整体流程如下:
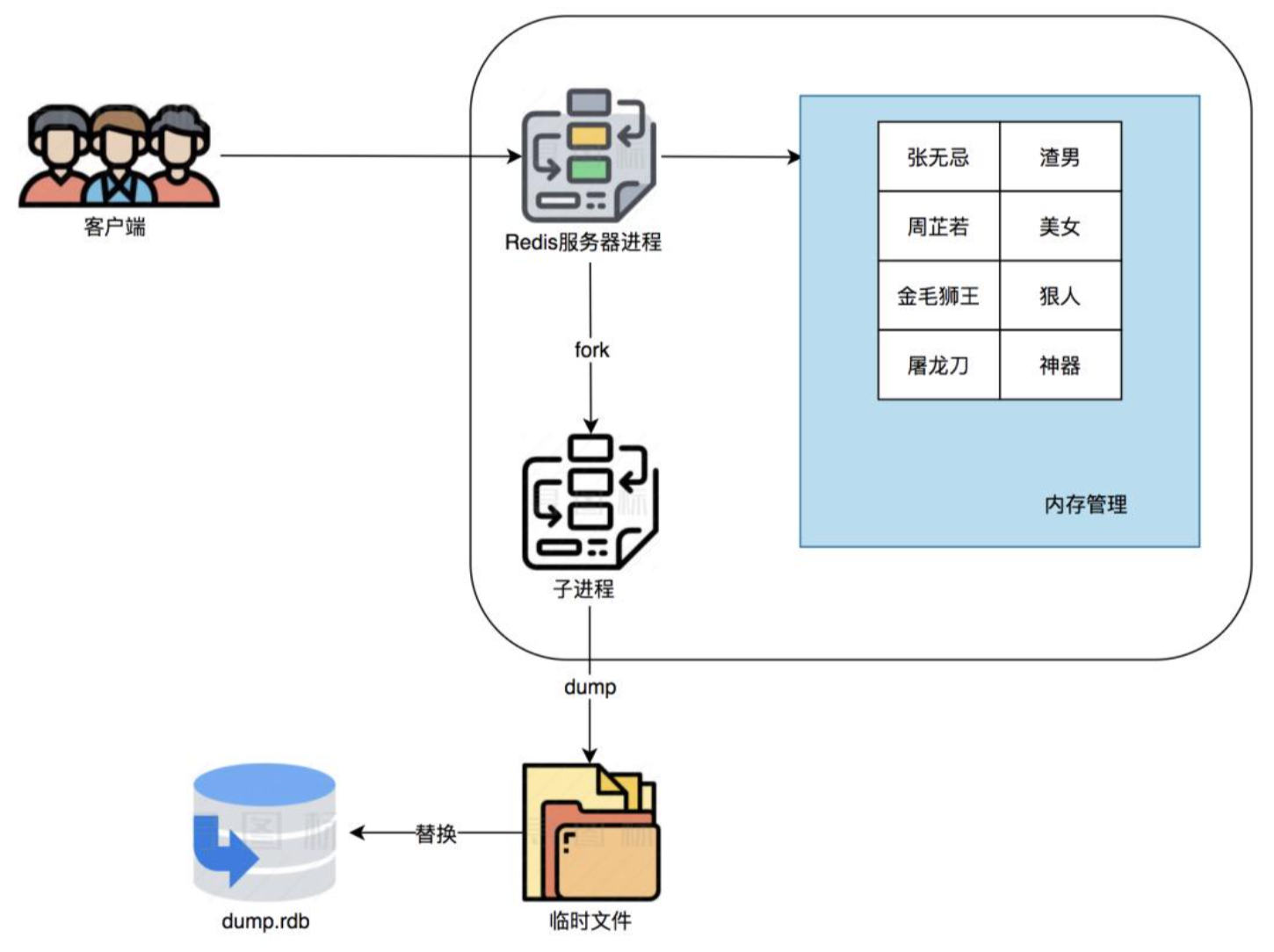
具体而言:fork创建子进程之后,通过写时复制技术,子进程和父进程是共享同一片内存数据的,因为创建子进程的时候,会复制父进程的页表,但是页表指向的物理内存还是一个。

下面还有一句:This method allows Redis to benefit from copy-on-write semantics.就是说这种方式让Redis从写时复制技术受益,Redis官方文档基本没废话,这句话看似无关轻重,实际上说明了:执行 RDB持久化过程中,Redis 依然可以继续处理操作命令的,也就是数据是能被修改的,这就是通过写时复制技术实现的。
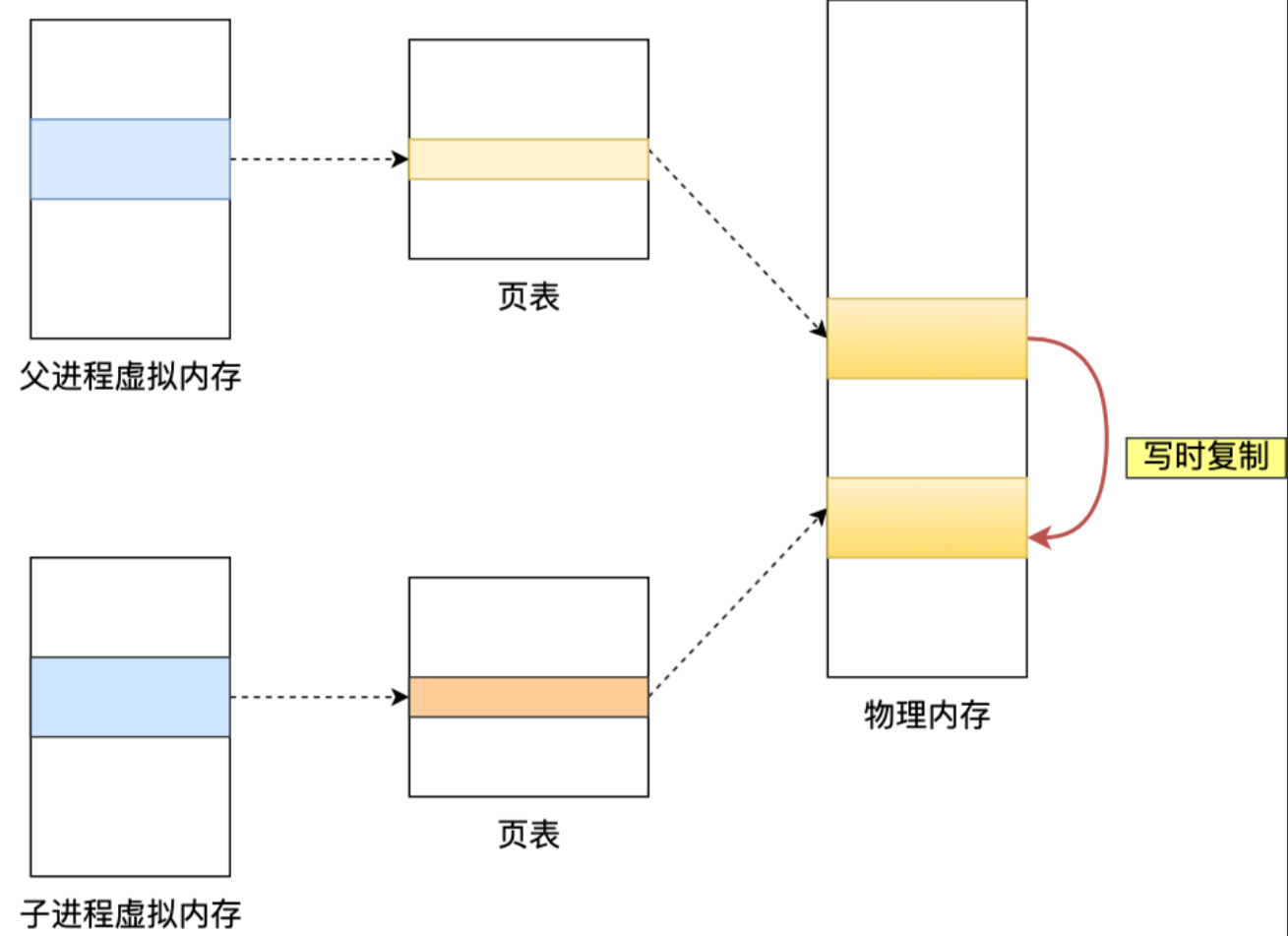
写时复制具体发生的场景:
- 当Redis主进程执行写入操作(如SET、HSET、LPUSH等命令)修改某个内存页中的数据时
- 此时系统检测到这个内存页是与子进程共享的
- 系统会复制一份内存页的副本,主进程在副本上进行修改
- 子进程继续使用原来的内存页创建快照
因此,只有在发生修改内存数据的情况时物理内存才会被复制一份。这就是为什么在进行RDB过程中,Redis的内存使用会临时增加 - 当主进程频繁修改数据时,会触发大量的写时复制操作,导致内存使用量显著上升。
Redis 主进程 fork 创建 重写子进程时,内核需要创建用于管理子进程的相关数据结构,这些数据结构在操作系统中通常叫作进程控制块(PCB);内核要把主线程的 PCB 内容拷贝给子进程。这个创建和拷贝过程由内核执行,是会阻塞主线程的。而且在拷贝过程中,子进程要拷贝父进程的页表,这个过程的耗时和Redis 的内存大小有关。如果Redis 内存大,页表就会大:fork 执行时间就会长,这就会给主线程带来阻塞风险。
AOF
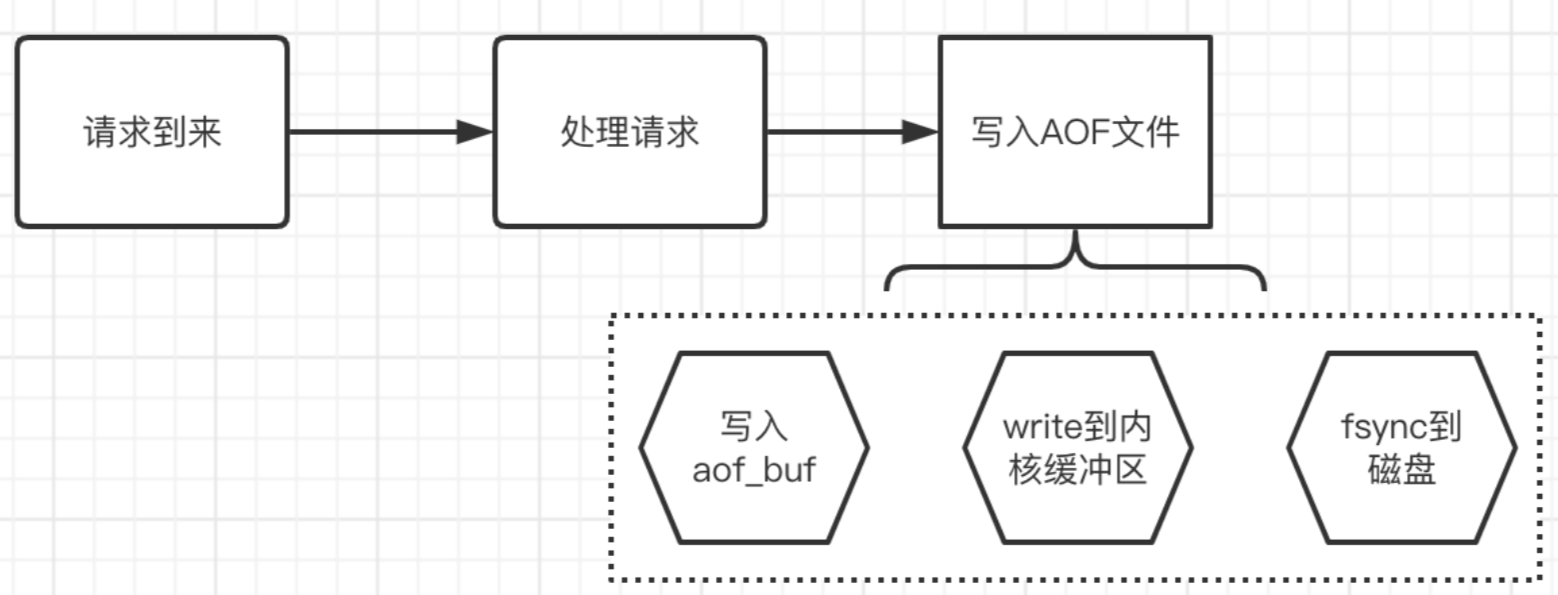
先上一张宏观的aof流程处理图:
持久化配置
同样在在Redis的配置文件中找到如下内容:

将appendonly设置为yes即可开启aof。
扩展参数选择(触发时机)
从上面的描述,我们可以看出,执行请求时,每条日志都会写入到AOF。这不免会让人担心,是否会影响Redis的执行性能,答案是肯定的,多了一步操作,或多或少都会带来些损耗,但是Redis实际是提供了不同的策略来选择不同程度的损耗。这里我们先从比较的宏观视角,介绍Redis提供的3种刷盘策略,以便根据需要进行不同的选择。
- appendfsync always,每次请求都刷入AOF,用官方的话说,非常慢,非常安全
- appendfsync everysec,每秒刷一次盘,用官方的话来说就是足够快了,但是在崩溃场景下你可能会丢失1秒的数据。
- appendfsync no,不主动刷盘,让操作系统自己刷,一般情况Linux会每30秒刷一次盘,这种策略下,可以说对性能的影响最小,但是如果发生崩溃,可能会丢失相对比较多的数据。
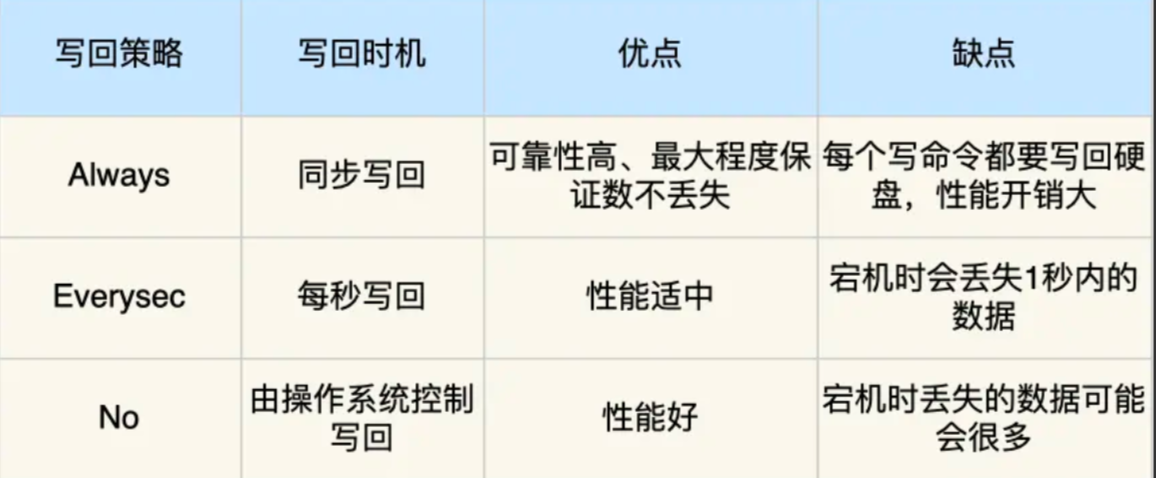
Redis建议是方案二,也就是每秒刷一次盘,这种方式下速度也足够快了,同时崩溃时损失的数据只有1s,这在大多数场景都是可以接受的。
当然了,我们要根据实际业务来选择,比如就是做简单的缓存,并且不存在什么超级热点缓存,那么丢失30秒也不是什么大事,这时候如果追求性能的机制,可以选择方案3。
方案一说实话倒是很少有场景会使用,因为Redis本身是无法做到完全不丢数据,Redis的定位就不是完全可靠,通常也就没必要损耗大量性能去追求立刻刷盘。
备份方法
写入aof一共分为3步:
其实是将数据写入AOF缓存中,这个缓存名字是aof buf,其实就是一个sds数据
1
2/*AOF buffer, written before entering the event loop */
sds aof buf;aof_buf 对应数据刷入磁盘缓冲区,什么时候做这个事情呢? 事实上,Redis源码中一共有4个时机,会调用一个flushAppendOnlyFile的函数,这个函数会使用write函数来将数据写入操作系统缓冲区:
- 处理完事件处理后,等待下一次事件到来之前,也就是beforeSleep中。
- 周期函数serverCron中,这也是我们打过很多次交道的老朋友了
- 服务器退出之前的准备工作时
- 通过配置指令关闭AOF功能时
刷盘,即调用系统的flush函数,刷盘其实还是在fushAppendOnlyFile函数中,是在write之后,但是不一定调用了fiushAppendOnlyFile,flush就一定会被调用,这里其实是支持一个刷盘时机的配置,这一步受刷盘策略影响是最深的,如下面代码所示,如果是appendfsync always策略,那么就立刻调用redis fsync刷盘,如果是AOF FSYNC EVERYSEC策略,满足条件后会用aof background fsync使用后台线程异步刷盘。
1 | /* Perform the fsync if needed. */ |
这段代码的工作逻辑是:
- 如果配置为
AOF_FSYNC_ALWAYS(每次写入后立即同步):- 开始监控延迟
- 调用
redis_fsync函数立即将数据刷新到磁盘 - 结束延迟监控并记录延迟样本
- 更新最后同步时间
- 如果配置为
AOF_FSYNC_EVERYSEC(每秒同步一次)且当前时间已超过上次同步时间:- 检查是否已有同步进行中,如果没有则调用
aof_background_fsync在后台线程中执行同步 - 更新最后同步时间
- 检查是否已有同步进行中,如果没有则调用
写入AOF(Append Only File)的过程不是原子性操作。
如果Redis在写入过程中崩溃:
- 如果崩溃发生在命令被添加到aof_buf之后但还未刷新到操作系统缓冲区,则这部分数据会丢失
- 如果崩溃发生在数据被刷新到操作系统缓冲区之后但还未写入磁盘,则根据操作系统的行为可能会丢失数据
当Redis重启时,它会检查AOF文件是否完整。如果文件结尾有不完整的命令(由于崩溃导致),Redis会尝试加载文件直到遇到第一个错误,然后停止并报告错误。
Redis提供了几种不同的AOF持久化策略来平衡性能和数据安全; 即使Redis崩溃,现有的AOF文件仍会保留,Redis会在重启时尝试使用它恢复数据。如果文件部分损坏,Redis还提供了
redis-check-aof工具来修复AOF文件。
AOF重写
AOF是不断写入的,这很容易带来一个疑问,如此下去AOF不是会不断膨胀吗?
针对这个问题,Redis采用了重写的方式来解决:Redis可以在AOF文件体积变得过大时,自动地在后台Fork一个子进程,专门对AOF进行重写。说白了,就是针对相同Key的操作,进行合并,比如同一个Key的set操作,那就是后面覆盖前面。这里重写的过程依旧是采取的写时复制方法。
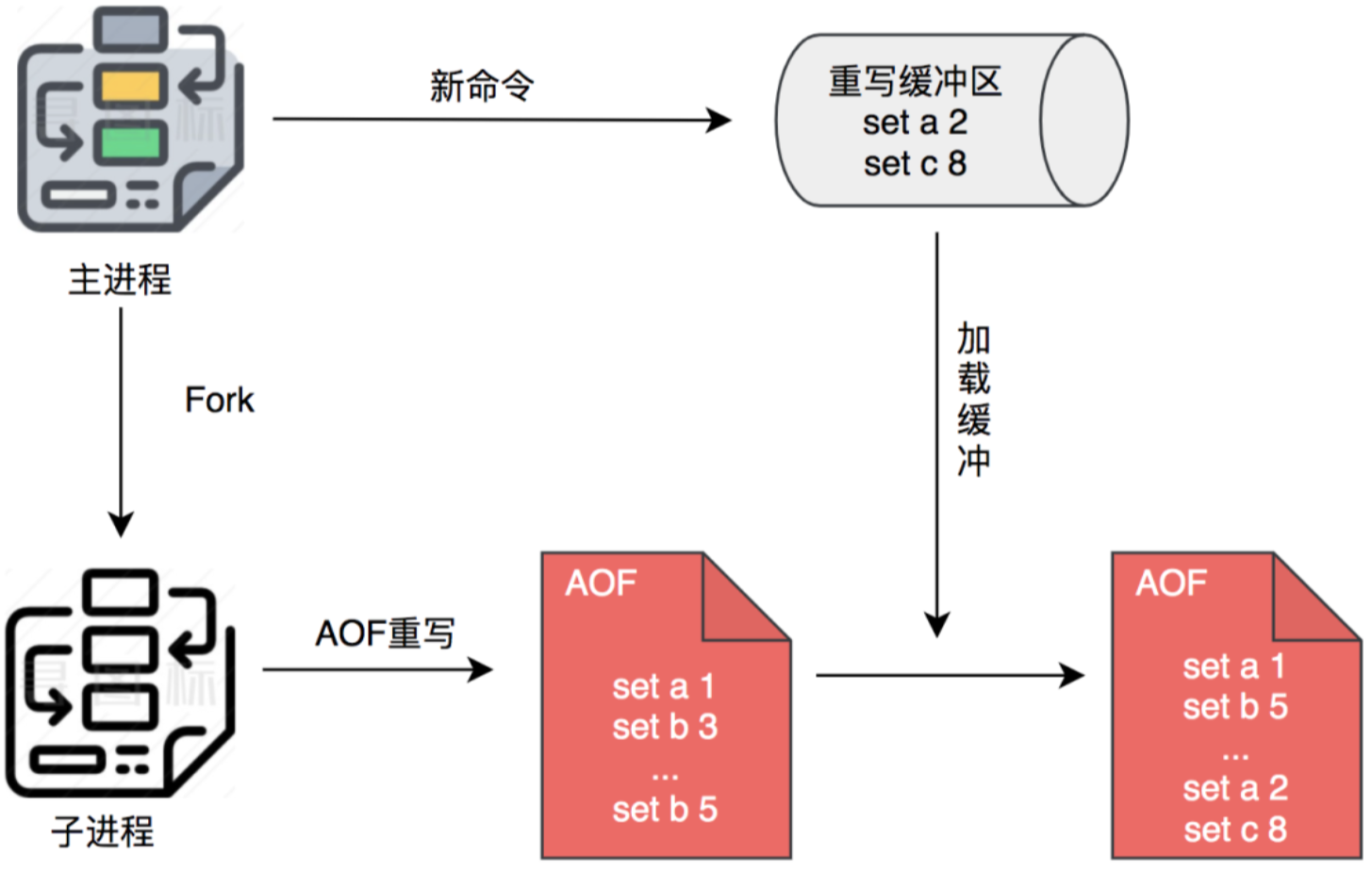
当发生重写时,Redis不仅会把新的操作数据村在原有aof的缓冲区aof_buf中,还会记录在开辟的一块新内存作为重写缓冲区。一旦新AOF文件创建完毕,Redis 就会将重写缓冲区内容,追加到新的AOF文件,再用新AOF文件替换原来的AOF文件。(相当于重写缓冲区的部分没有被优化)
这里可能会问,AOF达到多大会重写,实际上,这也是配置决定,默认如下,同时满足这两个条件则重写。
1 | #相比上次重写时候数据增长100% |
也就是说,超过64M的情况下,相比上次重写时的数据大一倍,则触发重写,很明显,最后实际上还是在周期函数来检查和触发的,和rdb的第三种持久化策略、aof写入的持久化策略相同。
混合持久化(AOF优化)
开启方式:
打开redis配置文件,mac下是在/usr/local/etc/redis.conf
aof-use-rdb-preamble
5.0之后默认是打开的,所以5.0之后只要AOF配置开启,默认就是混合持久化。
混合持久化的逻辑和aof重写差不多,但实际上,混合部署发生在AOF重写阶段,将当前状态保存为RDB二进制内容,写入新的AOF文件,再将重写缓冲区的内容追加到新的AOF文件,最后替代原有的AOF文件。区别就在于重写之后的文件格式,这里是rdb格式,追加的格式都是aof形式的,最后还是会变成可读性低的二进制数据文件(虽然还是aof后缀)。
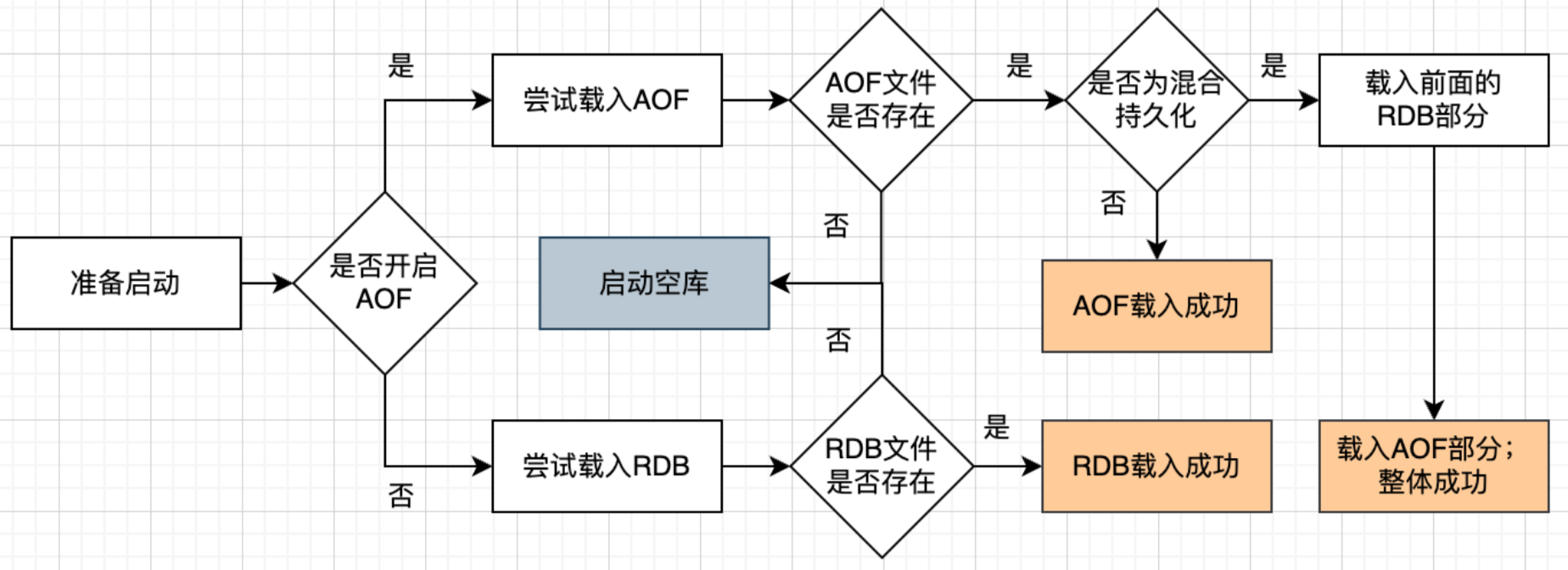
可以看到,混合持久化的优先级还是很高的。
混合持久化是对AOF重写的优化,这种方式可以大大降低AOF重写的性能损耗,以及降低AOF文件的存储空间,付出的代价则是降低AOF文件的可读性。但是实际生产中,很少有真正需要去人肉读AOF数据的情况,这点从5.0之后默认打开AOF混合持久化模式也能看出。
 微信
微信 支付寶
支付寶



