RedisTutorial04
缓存
Redis由于性能高效,通常可以做数据库存储的缓存,比如给MySQL当缓存就是常见的玩法,具体而言,就是将MYSQL的热点数据存储在Redis中,通常业务都满足二八原则,80%的流量在20%的热点数据之上,所以缓存是可以很大程度提升系统的吞吐量。
一般而言,缓存分为服务器端缓存,和客户端缓存。
- 服务器端缓存即服务端将数据存入Redis,可以在访问DB之后,将从DB得到数据的缓存起来;
- 客户端缓存就是对服务端远程调用之后,将结果存储在客户端,这样下次请求相同数据时就能直接拿到结果,不会再远程调用,提高性能节省网络带宽。
那么,用服务端还是客户端呢?
其实是需要分析具体瓶颈在哪里,当然,如果按通常的经验,从服务角度来看,在目前的微服务架构下,每个服务其实都应该缓存一些热点数据,以减轻热点数据频繁请求给自己带来的压力,毕竟微服务也要有一定的互不信任原则。
至于客户端缓存,这个就更看场景了,频繁请求的数据,就有必要做缓存。
下面我们以服务端缓存的视角,来进行缓存分析。
剧透:在分析计算机界的框架时,透明往往意味着不可见,而不是我们日常说的单向透明的那种透明,甚至可以说是反义词。所以说,所谓读穿透、写穿透的名字的意味其实是很深的。
缓存模式及其选择
Cache-Aside 旁路缓存
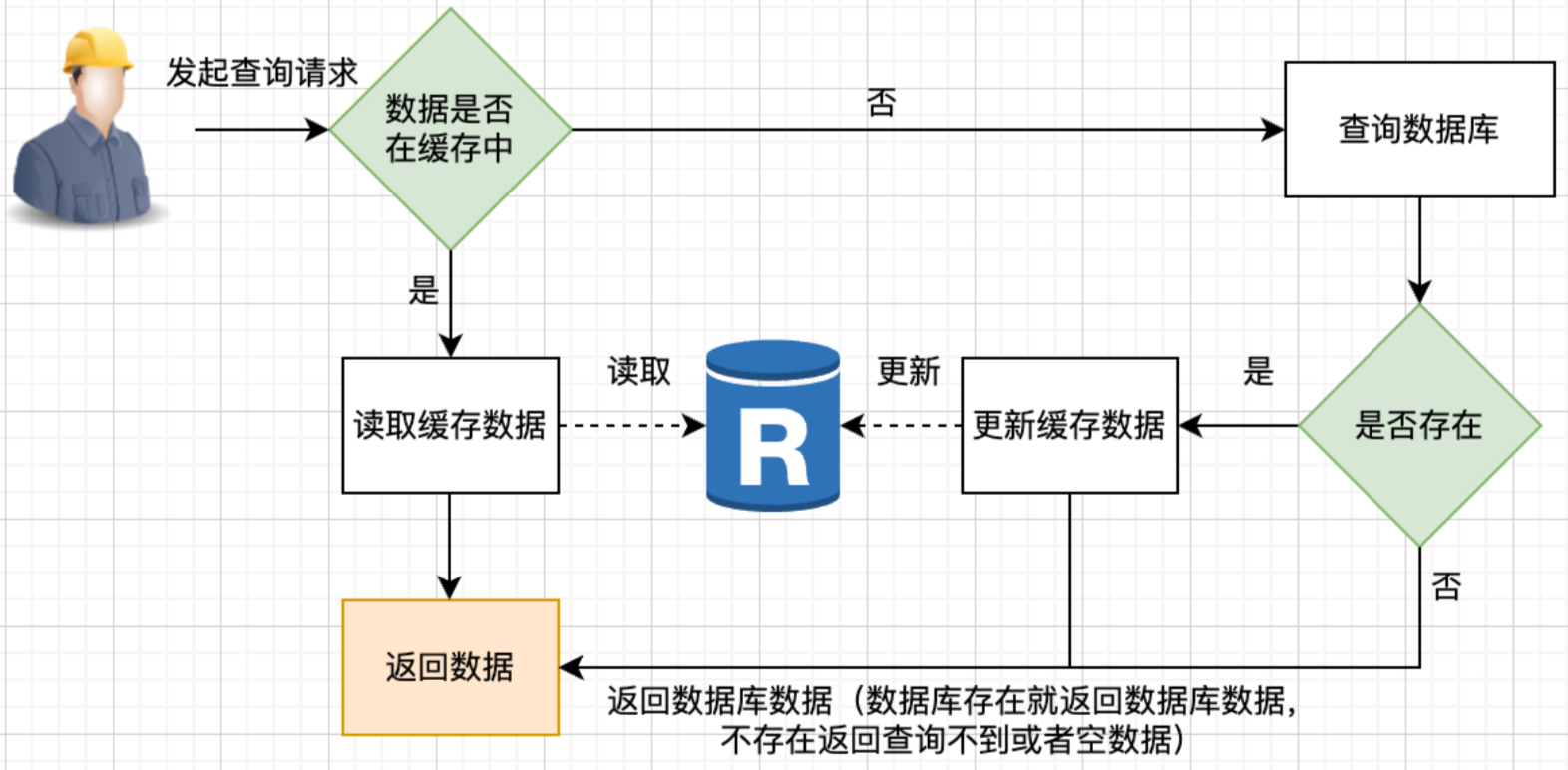
Cache Aside,即旁路缓存模式,是最常见的模式,应用服务把缓存当作数据库的旁路,直接和缓存进行交互。读操作的流程如下:
- 应用服务收到查询请求后,先查询数据是否在缓存上,如果在,就用缓存数据直接打包返回;
- 如果不存在,就去访问数据库,从数据库查询,并放到缓存中。
关于加载,除了查库后加载这种模式,如果业务有需要,还可以预加载数据到缓存。
说完读操作,我们再看看写操作的流程:
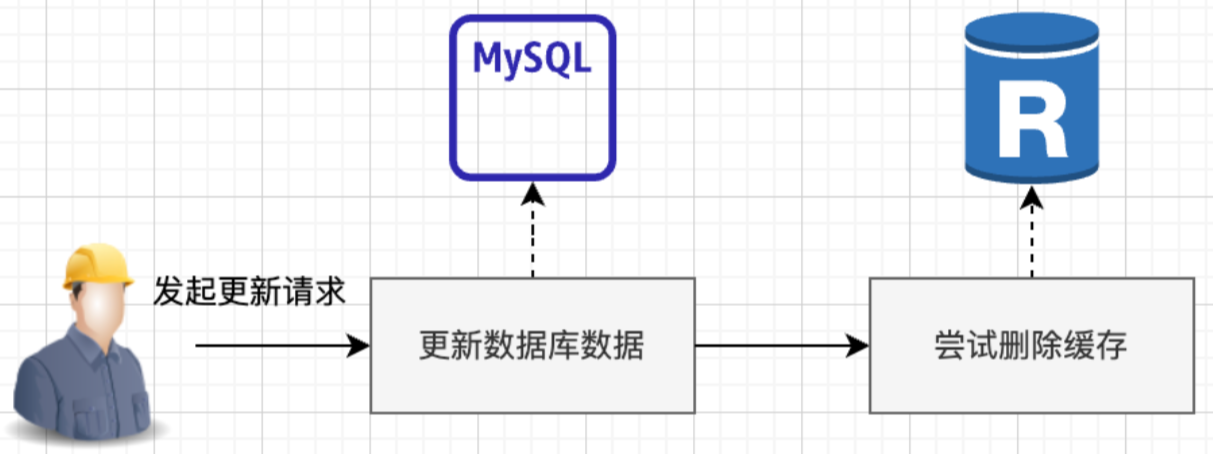
在更新操作的时候,Cache Aside 模式是一般是先更新数据库,然后直接删除缓存,为什么不直接更新呢?
因为更新相比删除会更容易造成时序性问题,举个例子:thread1更新mysql为5 ->thread2更新mysql为3 ->thread2更新缓存为3 ->thread1更新缓存为5,最终正确的数据因为时序性被覆盖了。
Cache Aside适用于读多写少的场景,比如用户信息、新闻报道等,一旦写入缓存,几乎不会进行修改。该模式的缺点是可能会出现缓存和数据库不一致的情况,比如更新完数据库还没更新缓存时redis进程挂掉的情况。
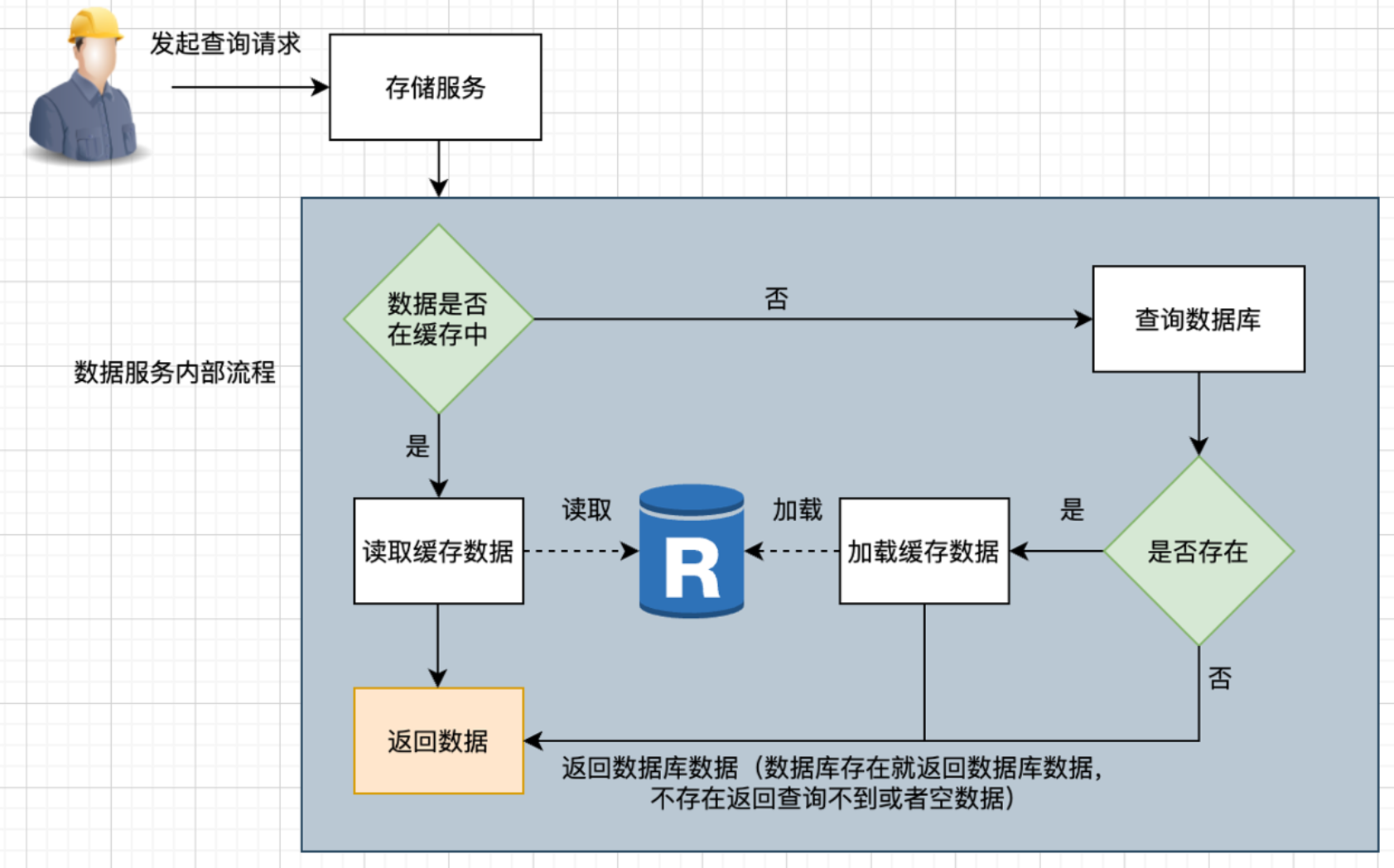
Read Through 读穿透
Read-Through,读穿透模式,和 Cache Aside 模式的区别主要在于应用服务不再和缓存直接交互,而是直接访问数据服务,这个数据服务可以理解为一个代理,即单独起这么一个服务,由它来访问数据库和缓存,作为使用者来看,不知道里面到底有没有缓存,数据服务会自己来根据情况查询缓存或者数据库。查询的时候,和Cache Aside一样,也是缓存中有,就用从缓存中获得的数据,没有就查DB,只不过这些由数据服务托管保存,而对应用服务是透明的(透明==不可见)。
相比 Cache Aside,Read Through 的优势是缓存对业务透明,业务代码更简洁。缺点是缓存命中时性能不如CacheAside,相比直接访问缓存,还会多一次服务间调用。
Write Through 写穿透
在Cache Aside中,应用程序需要维护两个数据存储:一个缓存,一个数据库。这对于应用程序来说,更新操作比较麻烦,还要先更新数据库,再去删除缓存。
WriteThrough模式相当于做了一层封装(实际上就是啥也没改):
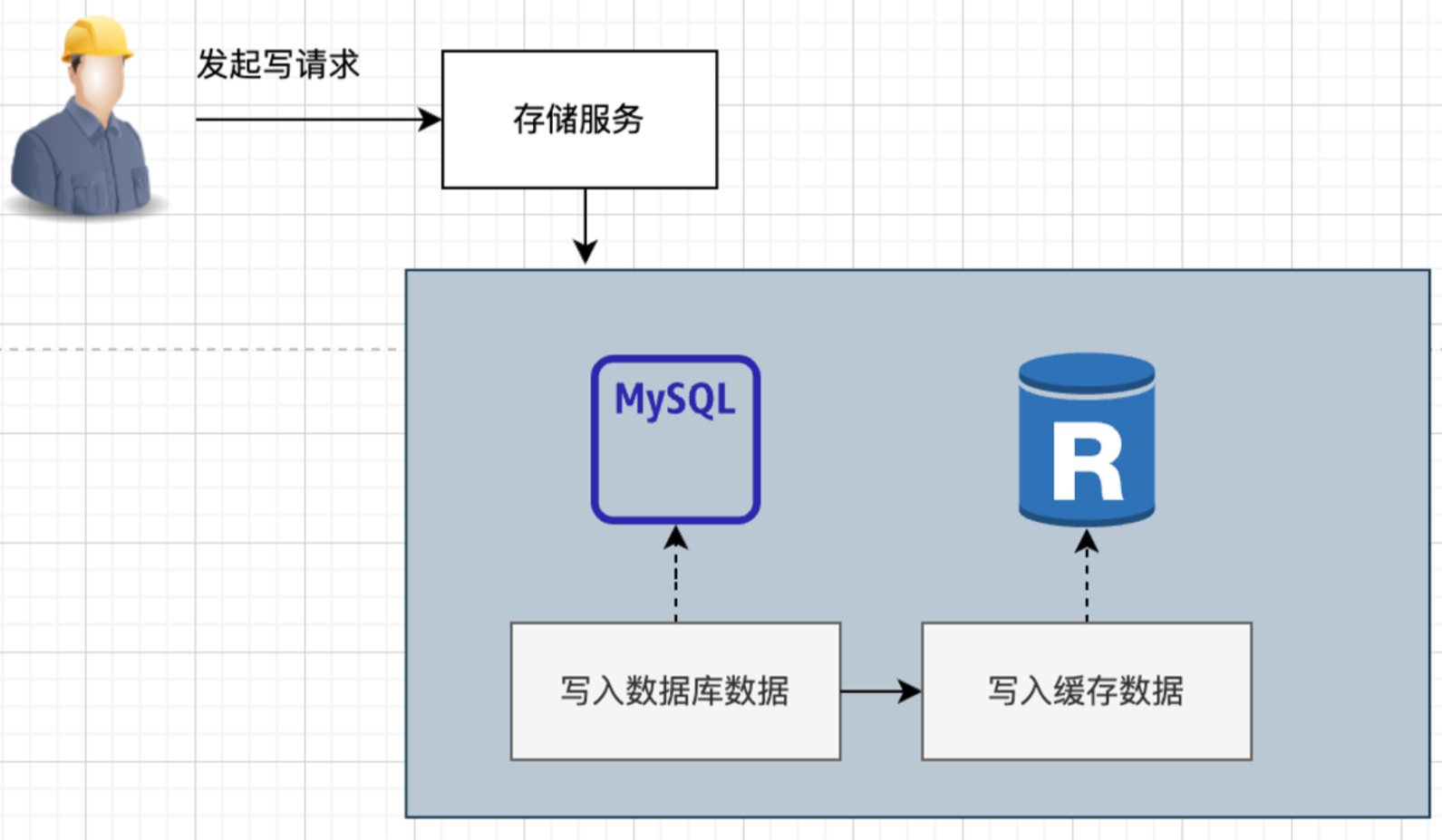
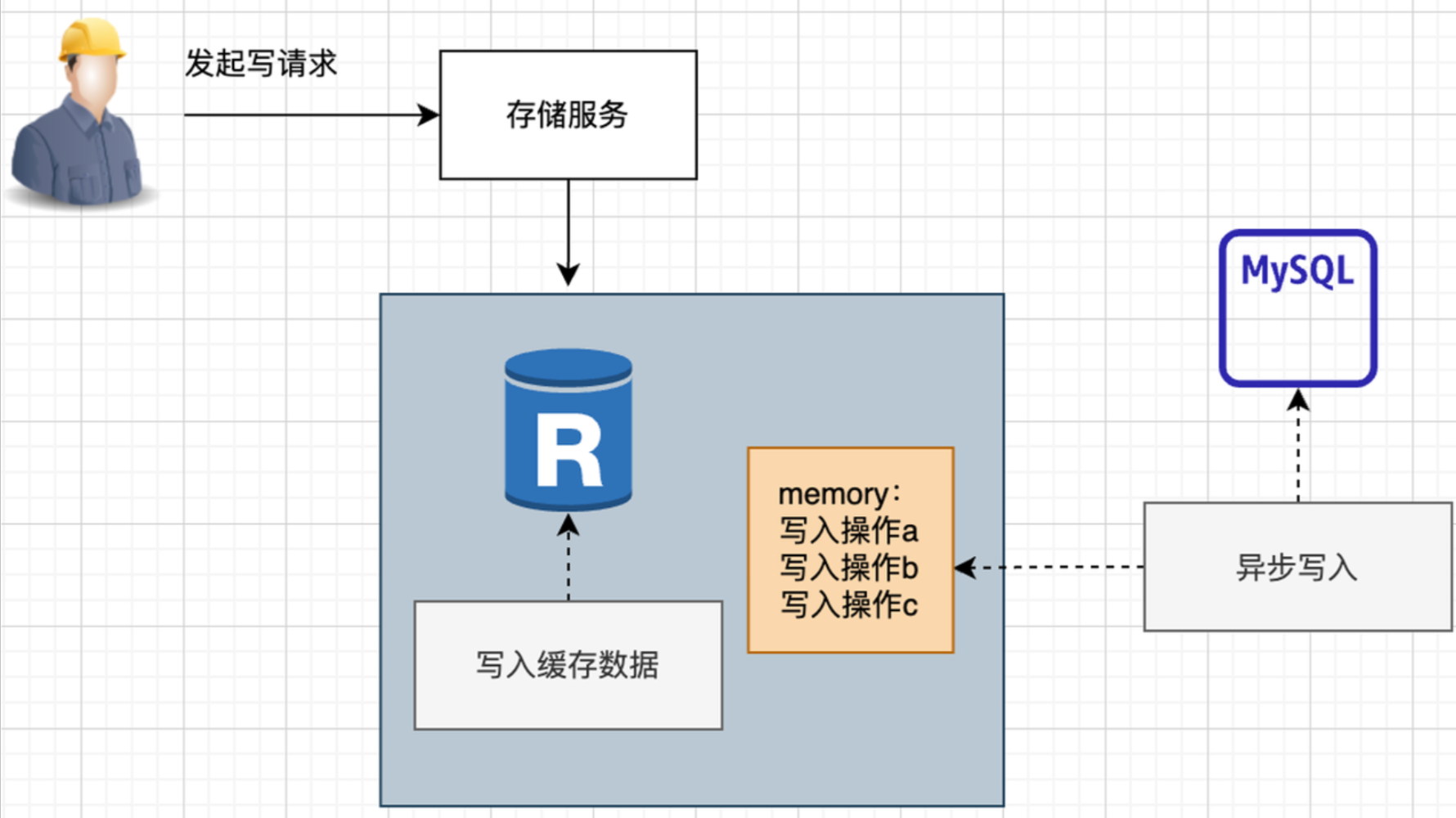
- 由这个存储服务先写入MySQL,再同步写入Redis,这样及时加载或更新了缓存数据。
- 可以理解为,应用程序只有一个单独的访问源,而存储服务自己维护访问逻辑。
在使用Write-Through时要特别注意的是缓存的有效性管理,否则会导致大量的缓存占用内存资源,因为这种模式下只要写入数据就加载了缓存。这里注意区分:Cache Aside是直接删去缓存,而写穿透是写入缓存。
Write-Behind 异步缓存写入
Write-Behind 和 Write-Through 相同点都是写入时候会更新数据库、也会更新缓存。不同点在于 Write-Through 会把数据立即写入数据库中,然后写缓存,安全性很高。而 Write-Behind 是先写缓存,然后异步把数据一起写入数据库,这个异步写操作是 Write-Behind 的最大特点。
数据库写操作可以用不同的方式完成:
- 一种是时间上的灵活性,其中一个方式就是收集写操作并在某一时间点(比如数据库负载低的时候)慢慢写入。
- 另一种方式就是合并几个写操作成为一个批量操作,一起批量写入。
两者是可以根据业务情况结合的。
异步写操作极大地降低了请求延迟并减轻了数据库的负担,但是代价是安全性不够,比如先写入了Redis,更新操作先放在存储服务内存中,但是还没异步写入MySQL之前,存储服务崩溃了,那么数据也就丢失了。
方案选型
各有优势,但是Cache-Aside Pattern,旁路缓存模式是最常见,最易用的,在业务开发中,其他模式很少会用到。
缓存异常
以下介绍三种缓存异常场景:缓存穿透、缓存击穿和缓存雪崩。
缓存穿透
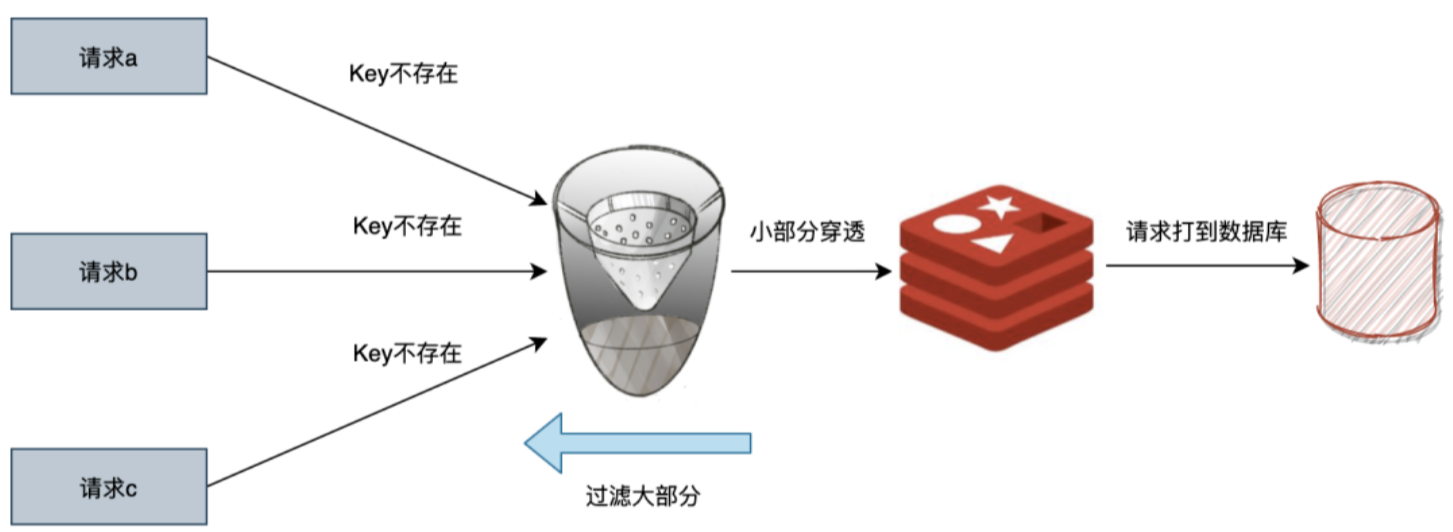
缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求。由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
在流量大时,可能DB就挂掉了,要是有人利用不存在的key频繁攻击我们的应用,这就是漏洞。

如发起为id为”-1”的数据或id为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大。
解决方案:
- 接口层增加校验,如用户鉴权校验,id做基础校验,id<=0的直接拦截;
- 从缓存取不到的数据,在数据库中也没有取到,这时也可以将key-value对写为key-null,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用同一个id暴力攻击。
- 布隆过滤器。bloom filter 就类似于一个hash set,用于快速判某个元素是否存在于集合中,其典型的应用场景.是快速判断一个key是否存在于某容器,不存在就直接返回。布隆过滤器的关键就在于hash算法和容器大小,可以用布降过滤器来应对,布降过滤器是一种比较巧妙的概率型数据结构,特点是高效地插入和查询,可以用来告诉我们“某样东西一定不存在或者可能存在”。虽然在有假阳性的问题存在,但是在这种场景下仍然能发生巨大作用。
缓存击穿
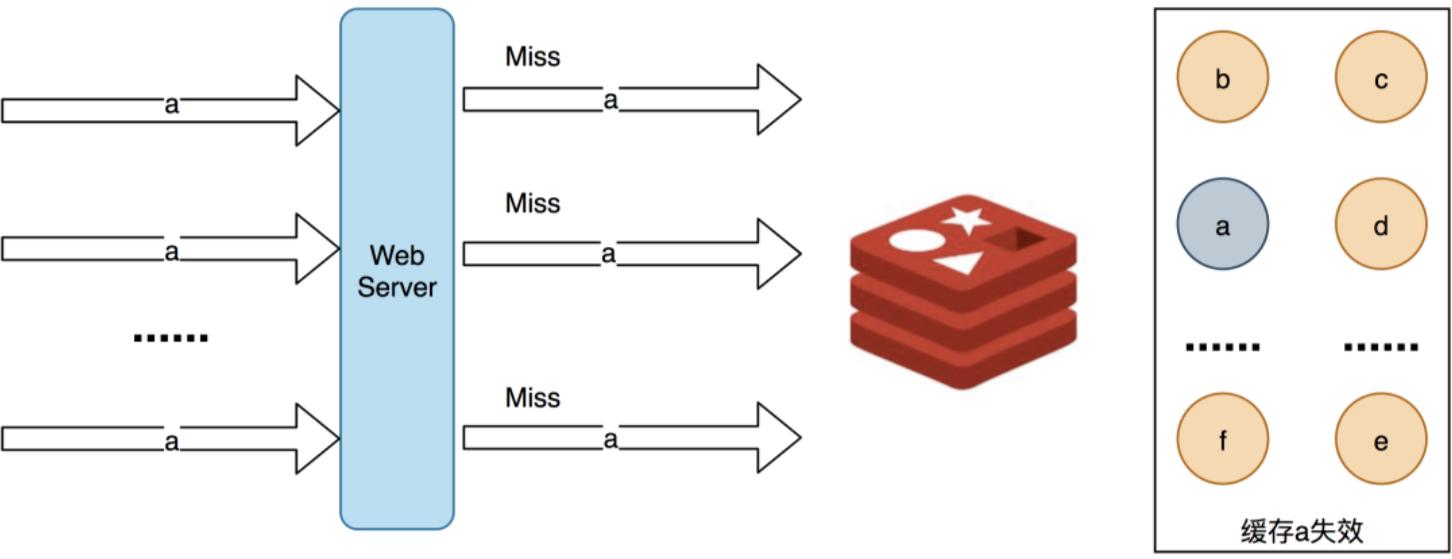
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力。
缓存击穿,一般指是指热键在过期失效的一瞬间,还没来得及重新产生,就有海量数据直达数据库
解决方案:
热点数据支持续期,持续访问的数据可以不断续期,避免因为过期失效而被击穿(可以设置只要有请求来访问,就增加过期时间)
发现缓存失效,重建缓存加互斥锁,当线程查询缓存发现缓存不存在就会尝试加锁,线程争抢锁,拿到锁的线程就会进行查询数据库,然后重建缓存。那么这时缓存里就有了数据,其他争抢锁失败的线程拿到锁,发现缓存已经有数据之后,就不会在查询数据库,而是直接查询缓存。
更加具体而言:
可以利用redssion 分布式锁。当线程拿到缓存发现过期了就会尝试加锁,线程争抢锁,拿到锁的线程就会进行查询数据库,然后重建缓存,争抢锁失败的线程,你可以加一个睡眠然后循环重试(redission 直接实现了可重试和可重入还保证了原子性);
如果担心线程资源会占用很大,还有一个解决方案就是用逻辑过期来解决缓存击穿,就是给缓存加上过期时间戳而不设置 tl,判断这个逻辑时间是否过期然后加锁重建缓存,注意这里争抢锁失败的线程就不再争抢了,而是直接返回已过期数据,具体解决方案还是得根据应用场景来使用。
缓存雪崩
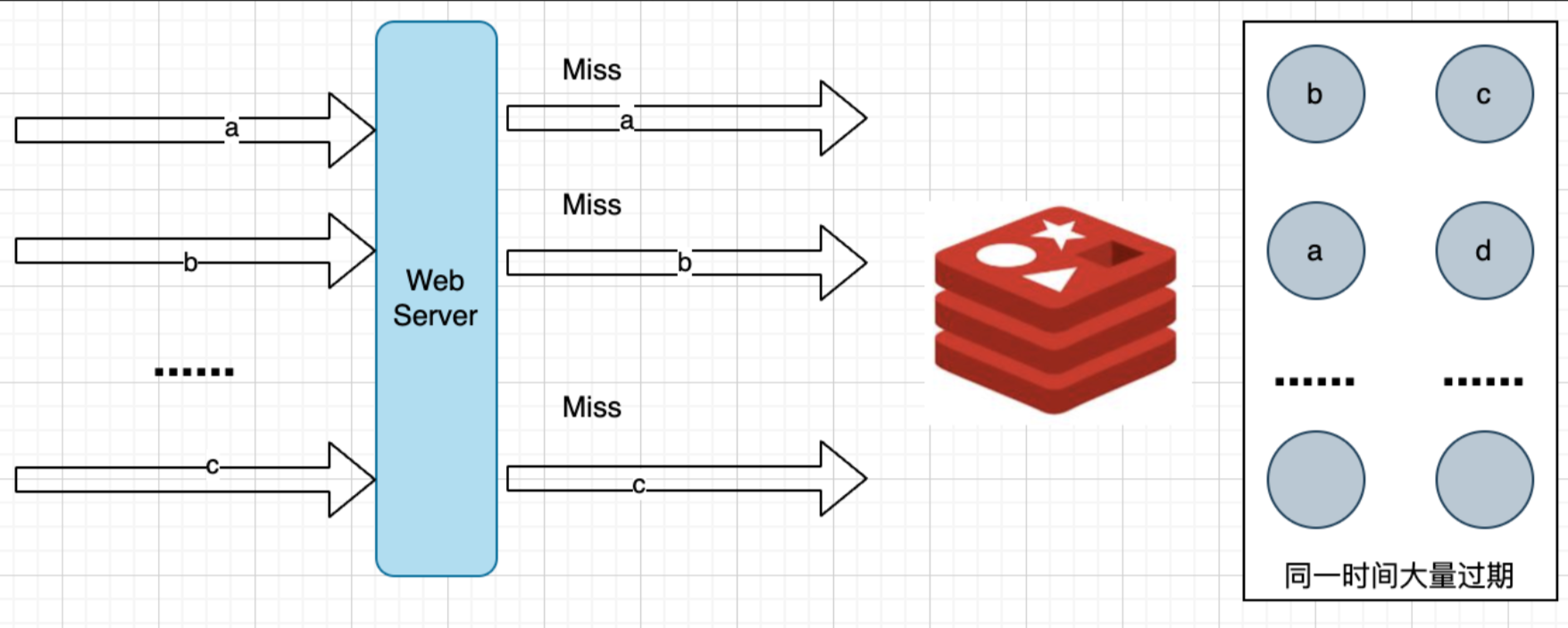
缓存雪崩顾名思义,是指大量的应用请求因为异常无法在Redis缓存中进行处理,像雪崩一样,直接打到数据库。
这里异常的原因,也可以说雪崩的原因,主要是由于缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至宕机。
解决方案:
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生。
- 和上面一样,重建缓存加互斥锁,当线程拿到缓存发现缓存不存在就会尝试加锁;线程争抢锁,拿到锁的线程就会进行查询
数据库,然后重建缓存,争抢锁失败的线程,就让其睡眠然后循环重试。
一致性保证
缓存,都知道是持久化数据的冗余存储,但如果缓存加载了数据源的数据,但对应数据要发生变化,怎么办呢?
前面介绍了几种缓存模式,这里我们以常见、最实用的旁路缓存模式为基础,来进行分析。
大的方向有三:
更新MySQL即可,不管Redis,完全以过期时间兜底
更新MySQL之后,操作Redis,当然要考虑到Redis更新操作可能会因为网络、进程重启等各种原因失败,所以过期时间兜底还是少不了。
异步将MySQL的更新刷入到Redis,比如先更新mysql,通过订阅mysql的binlog记录来异步执行更新redis的操作
方向一
使用redis的过期时间,mysql更新时,redis不做处理,等待缓存过期失效,再从mysql拉取缓存。这种方式实现简单,但不一致的时间会比较明显,具体由业务来配置。如果读请求非常频繁,且过期时间设置较长,则会产生很多脏数据,就看业务是否能接受了。
优点:
- redis原生接口,开发成本低,易于实现:
- 管理成本低,出问题的概率会比较小。
不足:
- 完全依赖过期时间,时间太短容易造成缓存频繁失效,太长容易有较长时间不一致,对编程者的业务能力有一定要求。
方向二
不光通过key的过期时间兜底,还需要在更新mysql时,同时尝试操作redis,这里的操作分两种方式,1是更新,直接将结果写入Redis,但实际上很少用更新,而是用删除,等待下次访问再加载回来,为什么呢?因为更新缓存容易带来时序性问题。
相比于数据延迟而言,在MySQL中产生脏读或者不可重复读会更让人不能接受,所以一般都选择删除。
上面有提到,这里是尝试删除,这样说是这一步操作是可能失败了,失败就我们可以忽略,也就是不能让删除成为一个关键路径,影响核心流程。
因为我们有key本身的过期时间作为保障,所以最终一致性是一定达成的,主动删除redis数据只是为了减少不一致的时间。
优点:
- 相对方案一,达成最终一致性的延迟更小;
- 实现成本较低,只是在方案一的基础上,增加了删除逻辑。
不足:
- 如果更新mysql成功,删除redis却失败,就退化到了方案一;
- 在更新时候需要额外操作Redis,带来了损耗。
方向三
这种方法的核心思想是利用数据库的变更日志(binlog)来保持Redis缓存与数据库的一致性。
下面图片中描述具体方案是:
- 将消费服务作为MySQL的一个slave(从库)
- 订阅MySQL的binlog日志,解析日志内容
- 将解析结果更新到Redis中
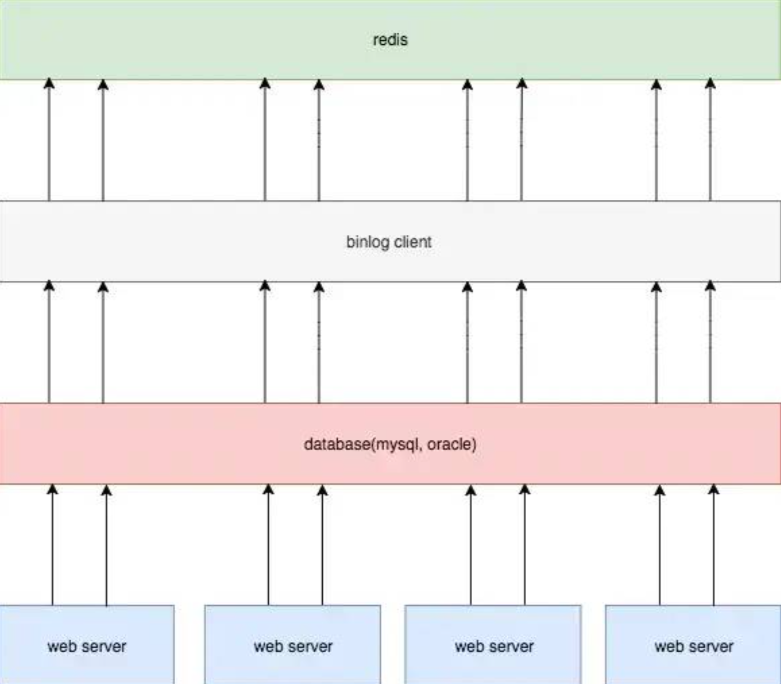
简单来说,这种方法就像是给你的数据库安装了一个”监视器”,当数据库有任何变动时,这个监视器会自动将相同的变动应用到Redis缓存中,从而保持两者的数据一致性。这就是所谓的”Canal组件”(阿里巴巴开源的)的工作方式。
优点:
- 和业务完全解耦,在更新mysql时,不需要做额外操作;
- 无时序性问题,可靠性强。
缺点:
- 引入了消息队列这种算比较重的组件,还要单独搭建一个同步服务,维护他们是非常大的额外成本;
- 同步服务如果压力比较大,或者崩溃了,那么在较长时间内,redis中都是老旧数据。
方案选型
- 首先确认产品上对延迟性的要求,如果要求极高,且数据有可能变化,别用缓存,因为用了缓存就意味着你必须能接受一定程序的延迟。
- 通常来说,过期时间兜底是行之有效的办法,也是应用最普遍的方式,如果希望能一定程度减少缓存不一致的时间,可以考虑增加个删除逻辑,提升一致性。
- 从解耦层面来看,可以使用订阅binlog的模式来更新,缺点就是重,比较适合的场景是数据不过期场景(省去系统资源开销)
“数据不过期场景”指的是Redis中的数据需要长期保存,与数据库保持高度一致的场景:
- 数据变更频率不高,但一致性要求高
- 数据需要长期在缓存中存在,不设置TTL(过期时间)
- 缓存数据量较大,重建成本高
比如说电商平台中,商品信息就是适用数据不过期的,但是用户的购物车信息就不适用。
所谓的“重”其实也体现在很多方面,比如:
需要额外维护Canal等组件
需要处理binlog解析和转换的逻辑
对系统资源(CPU、内存、网络)有额外消耗
整个链路相对复杂,出问题时排查难度更大
…….
 微信
微信 支付寶
支付寶



