MysqlTutorial08
主从复制与读写分离
过程
总共有三步:
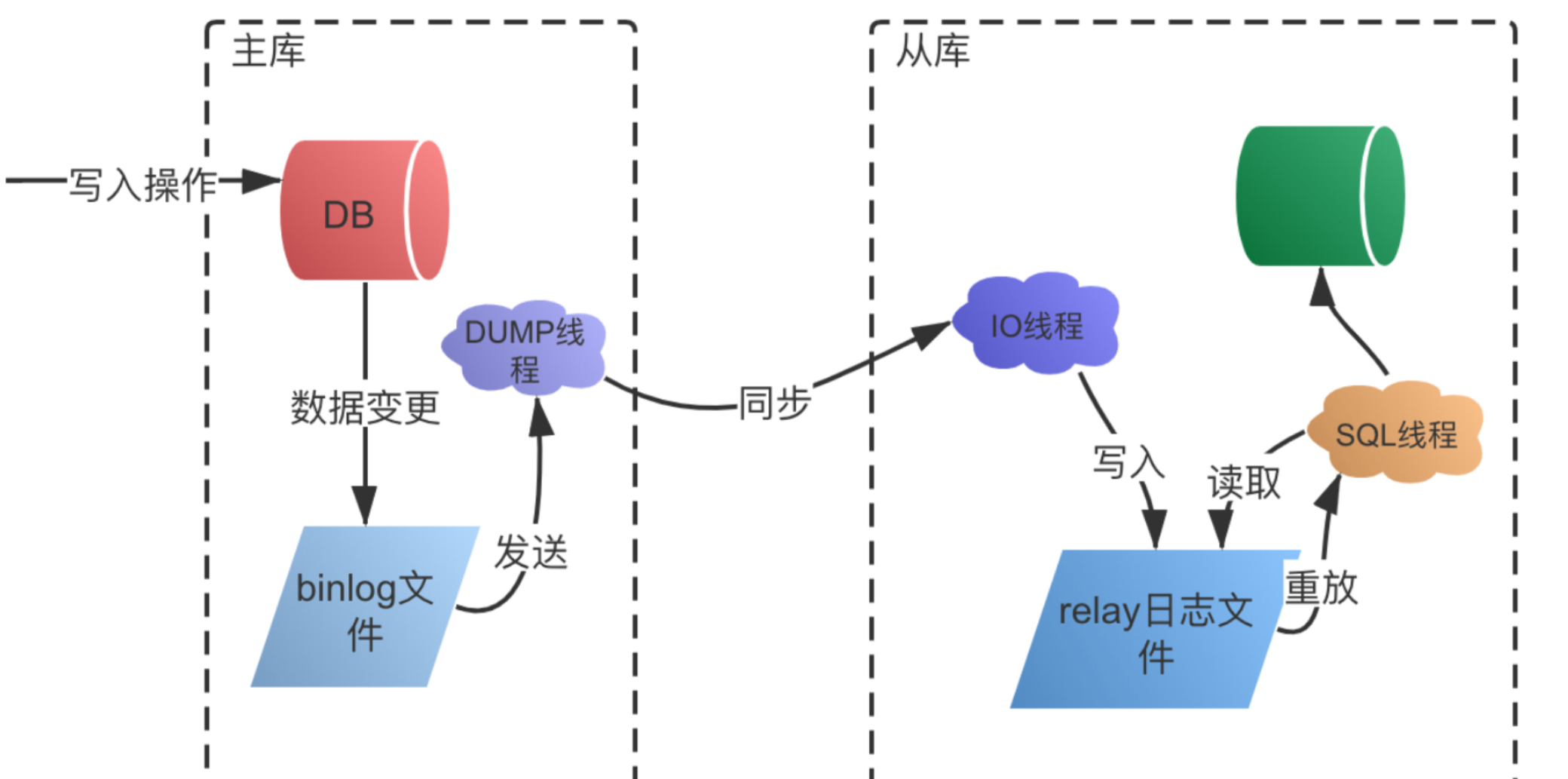
- 写入binlog: 当主库上发生数据变更时,这些变更会被记录到二进制日志(binlog)中。这是一个事务日志,记录了所有修改数据库的操作。
- 同步binlog: 从库上的IO线程会连接到主库,并请求获取主库上的binlog。主库会通过dump线程发送binlog内容给从库,从库将接收到的binlog信息写入到自己的中继日志(relay log)中。
- 回放binlog: 从库上的SQL线程会读取relay log中的内容,并在从库上执行这些SQL操作,使从库的数据与主库保持一致。
那么这就不得不提出一个问题:为什么要通过relay日志文件做缓冲呢,从库为什么不能直接请求获取主库的binlog日志并读取呢?
首先要考虑到数据完整性风险。从库的 IO线程从主库读取二进制日志(binlog)时,如果没有 relaylog,一旦从库发生故障,已读取但未执行的 binlog 内容可能丢失,导致数据不一致。
还有就是复制效率问题:IO 线程和SQL线程的工作节奏不同步。没有 relay log 作为缓冲,SQL线程可能需要等待 IO 线程从主库获取数据,这会使从库的复制速度受网络和主库负载影响,即加大主库的负载又降低复制效率。
因此,relay log作为数据缓冲、故障恢复和减轻主库负担的日志是不可缺少的。
分类
全同步复制
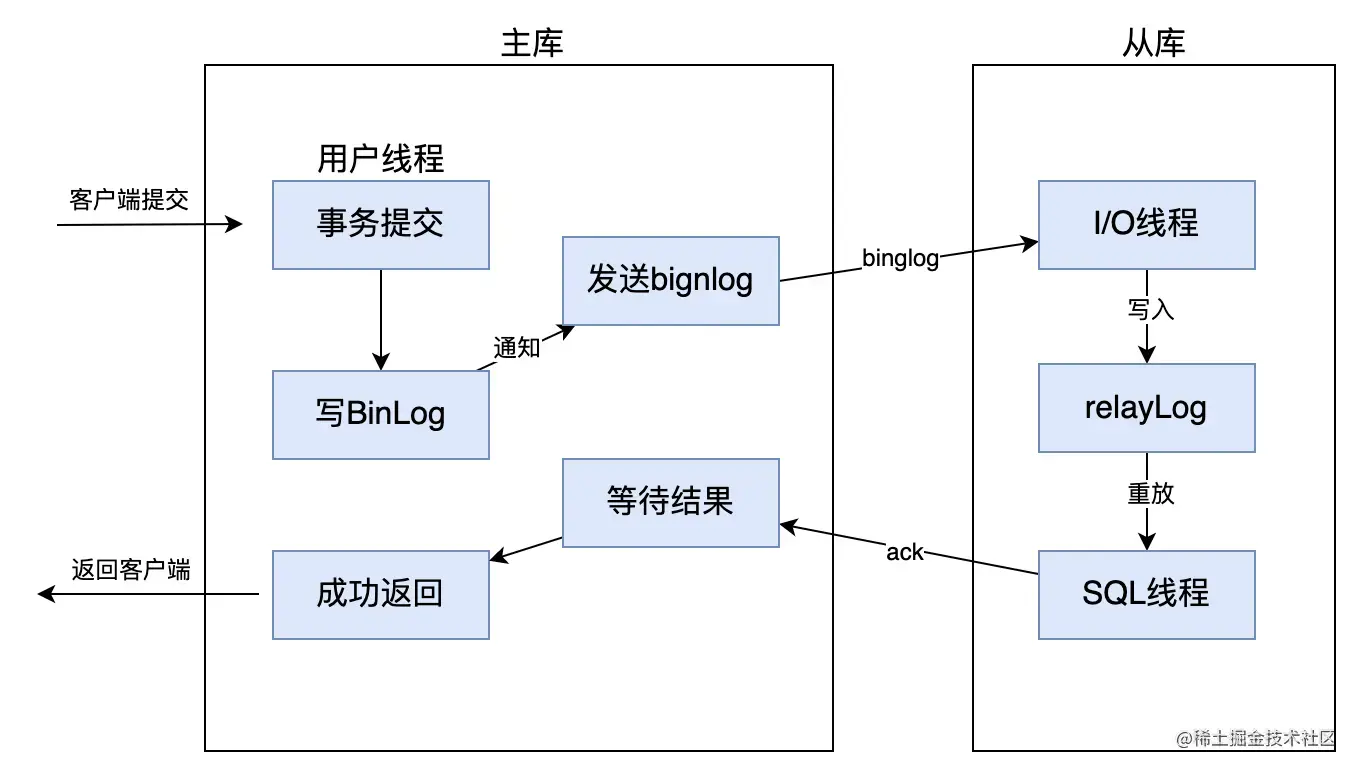
全同步复制,就是当主库执行完一个事务之后,要求所有的从库也都必须执行完该事务,才可以返回处理结果给客户端。因此,虽然全同步复制数据一致性得到保证了,但是主库完成一个事务需要等待所有从库也完成,性能会比较低。
异步复制
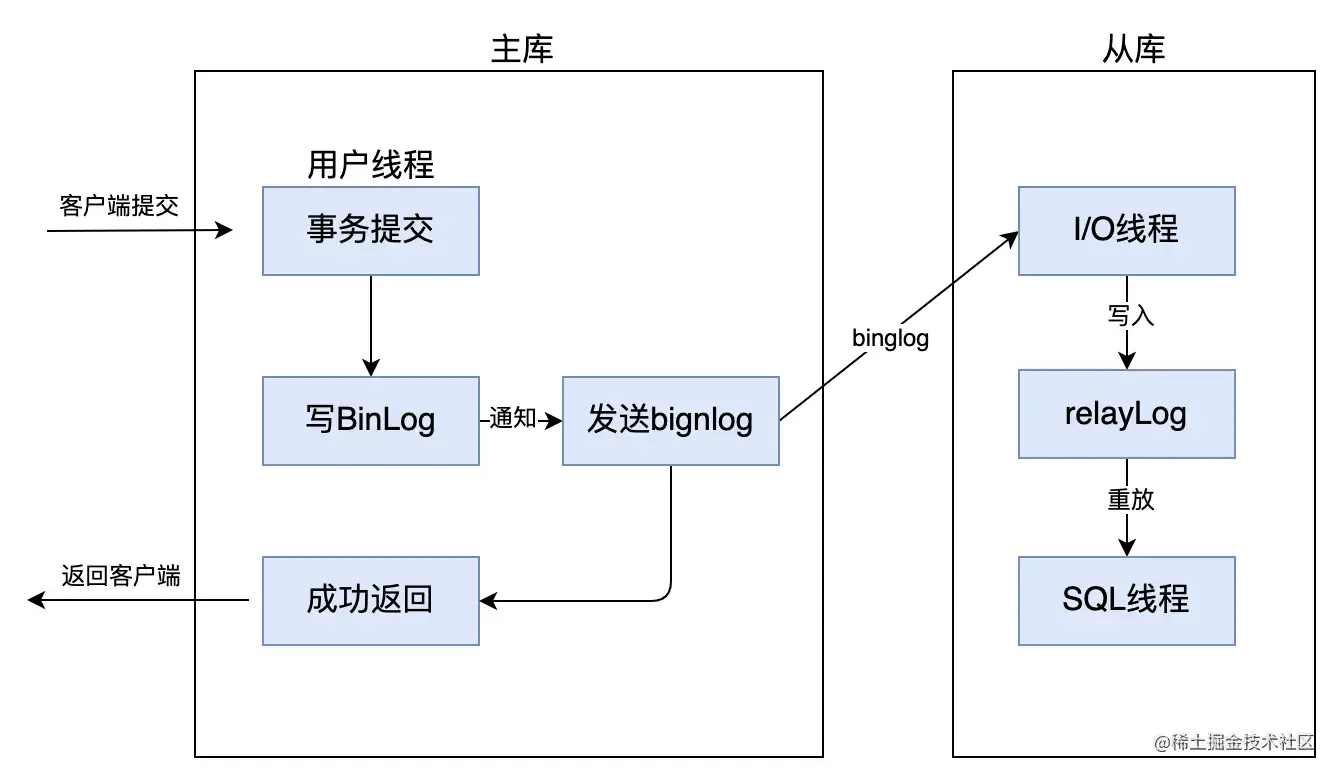
异步复制,就是当主库提交事务后,会通知 binlog dump 线程发送 binlog 日志给从库,一旦 binlog dump 线程将 binlog 日志发送给从库之后,不需要等到从库也同步完成事务,主库就会将处理结果返回给客户端。
因为主库只管自己执行完事务,就可以将处理结果返回给客户端,而不用关心从库是否执行完事务,这就可能导致短暂的主从数据不一致的问题了,比如刚在主库插入的新数据,如果马上在从库查询,就可能查询不到。
而且,当主库提交事物后,如果宕机挂掉了,此时可能 binlog 还没来得及同步给从库,这时候如果为了恢复故障切换主从节点的话,就会出现数据丢失的问题,所以异步复制虽然性能高,但数据一致性上是最弱的。
MySQL 主从复制,默认采用的复制策略就是异步复制。
半同步复制
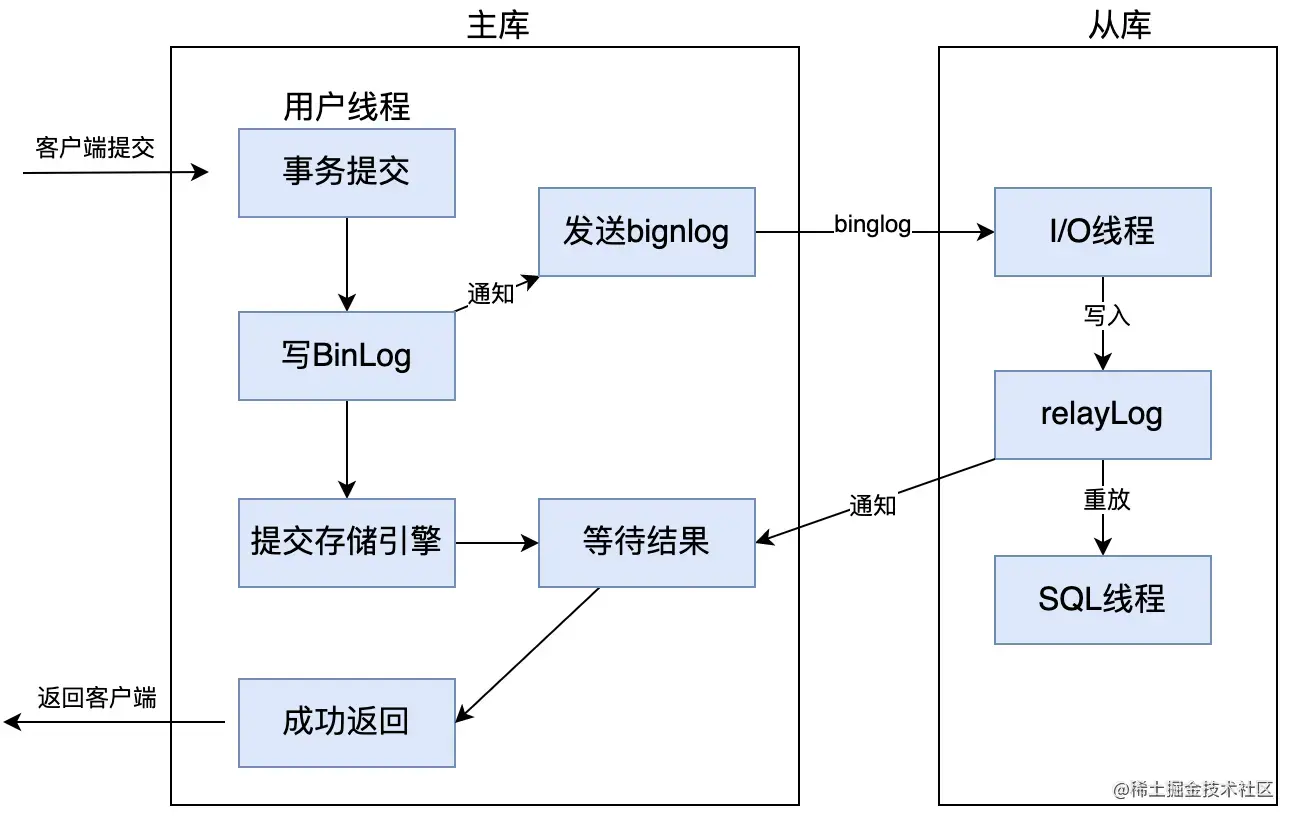
MySQL 5.5版本之后开始支持半同步复制的方式。原理是在客户端提交事务之后不直接将结果返回给客户端,而是等待至少有一个从库收到了 Binlog,并且写入到中继日志中,再返回给客户端。这样做的好处就是提高了数据的一致性,当然相比于异步复制来说,至少多增加了一个网络连接的延迟,降低了主库写的效率。
延迟解决
由于主库和从库是两个不同的数据源,主从复制过程会存在一个延时,当主库有数据写入之后,同时写入 binlog日志文件中,然后从库通过 binlog 文件同步数据,由于需要额外执行日志同步和写入操作,这期间会有一定时间的延迟。特别是在高并发场景下,刚写入主库的数据是不能马上在从库读取的,要等待几十毫秒或者上百毫秒以后才可以。
在某些对一致性要求较高的业务场景中,这种主从导致的延迟会引起一些业务问题,比如订单支付,付款已经完成,主库数据更新了,从库还没有,这时候去从库读数据,会出现订单未支付的情况,在业务中是不能接受的。
为了解决主从同步延迟的问题,通常有以下几个方法。
- 使用缓存解决:可以在写入数据主库的同时,把数据写到 Redis 缓存里,这样其他线程再获取数据时会优先查询缓存,也可以保证数据的一致性。不过这种方式会带来缓存和数据库的一致性问题。
由于写入缓存的速度比写入从库快,所以对于从库想要同步数据的话也直接从缓存读取。相当于用读缓存代替读写分离的主从库。
- 直接査询主库:对于数据延迟敏感的业务,可以强制读主库。但是我们要提前明确查询的数据量不大,不然会出现主库写请求锁行,影响读请求的执行,最终对主库造成比较大的压力。
读写分离落地
- 一种简单的做法是:提前把所有数据源配置在工程中,每个数据源对应一个主库或者从库,然后改造代码,在代码逻辑中进行判断,将 SQL 语句发送给某一个指定的数据源来处理。这个方案简单易实现,但 SQL 路由规则侵入代码逻辑,在复杂的工程中不利于代码维护。
如果要实现查询语句连接从库,增删改语句连接主库,这种实现主从分离的方式的话,需要改造原本的代码逻辑,呢当然对代码有侵入性啊~
- 另一个做法是:独立部署的代理中间件,如 MyCat,这一类中间件部署在独立的服务器上,一般使用标准的MVSOL通信协议,可以代理多个数据库。该方案的优点是隔离底层数据库与上层应用的访问复杂度,比较适合有独立运维团队的公司选型;缺陷是所有的 SQL 语句都要跨两次网络传输,有一定的性能损耗,再就是运维中间件是一个专业且复杂的工作,需要一定的技术沉淀。
所以说一般使用独立部署的代理中间件 MyCat 来实现读写分离,但主要有三个缺点:
1.单点性能/故障问题(可以用集群+负载均衡+限流+故障转移来规避)
2.网络链路多一跳带来的延迟问题
3.运维成本
宕机?
MySQL 没有像 Redis 集群有哨兵模式,可以自动将从库升级为主库。
MySQL 的“发现主服务器宕机”“处理故障转移逻辑“要由数据库高可用套件完成,常用的是 MHA(Master High Availability),它是一款开源的MySQL 高可用程序,它由两大组件所组成,MHA Manger和 MHA Node。
- MHA Manager 通常部署在一台服务器上,用来判断多个 MySQL 高可用组是否可用。当发现有主服务器发生宕机,就发起 failover 操作。MHA Manger 可以看作是 failover 的总控服务器。
- 而 MHA Node 部署在每台 MySQL 服务器上,MHA Manager 通过执行 Node 节点的脚本完成 failover 切换操作。
MYSQL 的高可用套件用于负责数据库的 Failover 操作,也就是当数据库发生宕机时,MYSQL 可以剔除原有主机,选出新的主机,然后对外提供服务,保证业务的连续性。
总结:
MySQL 主从复制没有实现发现主服务器宕机和处理故障迁移的功能,要实现自动主从故障迁移的话,可以使用开源的 MYSQL 高可用套件 MHA,MHA 可以在主数据库发生宕机时,可以剔除原有主机,选出新的主机,然后对外提供服务,保证业务的连续性。
主库挂了的处理办法如上,那么从库挂了怎么办?很简单,此时如果主库没挂,重新 reset,重新进行主从复制,就能恢复从节点的数据就行啦!
分库分表
分库分表的意思把原本存储于单个数据库上的数据拆分到多个数据库,把原来存储在单张数据表的数据拆分到多张数据表中,实现数据切分。
分库分表使用的场景不一样:
- 分表是因为数据量比较大,导致事务执行缓慢;
- 分库是因为单库的性能无法满足要求。
当单张数据表的数据量太大的时候,经验值是 500W以上的数据量,就会影响了事务的执行效率,这时候就要考虑分表了,通过减少每次查询数据总量来解决数据查询缓慢的问题。
500w 是阿里巴巴开发手册的建议值,但是并不是每个业务碰到500w 就要分了,其实关键看这个数据量的场景下,查询的速度业务是否能接受,如果 能接受甚至 2000w 数量级也能接受那也没必要分表,而且之前也有案例说表数据量都达到1亿了也没分表,因为这个业务查询是低频的,而且也能接受查询的延时。
当单台 MySQL 扛不住高并发流量的时候,就要考虑分库了,把并发请求分散到多台 MySQL 实例中。
当然,分库分表也会产生许多的问题,以下是问题及其解决方式:
- 分布式事务问题:对业务进行分库之后,同一个操作会分散到多个数据库中,涉及跨库执行SQL语句,也就出现了分布式事务问题。解决方式,如果对一致性要求比较高的业务,比如金融类的业务,可以使用分布式事务中间件,实现 TCC 事务模型:互联网的业务通常对一致性要求低,会使用基于本地消息表来实现分布式事务达到最终一致性的效果,这个分布式事务的方案性能会好一些。
TCC模型:每次操作分为三个阶段:
1.Try:预留资源或锁定资源
2.Confirm:确认操作,解锁资源
3.Cancel:取消操作,释放资源
大致流程:
1.各个服务提前预留一部分资源出来,用于完成事务(在事务确认提交之前,这部分资源对于其他操作是不可见的)
2.各个服务执行操作,并把结果告知协调器服务
3.协调器服务根据是否有服务失败,来判断应该确认事务解锁资源,还是取消事务释放资源。
- 全局 ID 唯一性问题:在单库单表时,业务 ID 可以依赖数据库的自增主键实现,进行分库分表之后,如果还是用数据库的自增主键,可能会导致主键重复。我们可以通过雪花算法或者美团leaf算法生成唯一主键ID。
- 跨库跨表关联查询问题:分库分表后,跨库和跨表的查询操作实现起来会比较复杂,我们可以通过剩余额外字段避免跨库关联,或者交给数据库分库分表中间件来实现,也可以将数据全量存储到ES中去,通过ES进行查询。
- 跨库跨表的排序问题:分库分表以后,数据分散存储到不同的数据库和表中,如果需要对数据列表进行排序时,就变得异常复杂,我们可以通过业务代码或者数据库分库分表中间件分别查询每个子表中的数据,然后汇总进行排序,也可以将数据全量存储到ES中去,通过ES进行查询。
- 跨库跨表 COUNT 查询的问题:分库分表以后,数据分散存储到不同的数据库和表中,如果需要对表进行COUNT 查询就会很复杂,我们可以将计数的数据单独存储在一张表里,或者将聚合查询的数据同步到 ES 中,交给ES进行查询。
 微信
微信 支付寶
支付寶



