FeatureEngineering02
创建特征
引言
一旦你确定了一组具有潜力的特征,就该开始开发它们了。在本课中,你将学习一些可以完全在Pandas中进行的常见转换。如果你感到生疏,我们有一个很棒的Pandas课程.
我们将在本课中使用四个具有不同特征类型的数据集:[美国交通事故]、[1985年汽车]、[混凝土配方]和[客户终身价值]。
发现新特征的技巧
- 理解特征。参考你的数据集的数据文档(如果有)。
- 研究问题领域以获取领域知识。如果你的问题是预测房价,请对房地产进行一些研究。维基百科是一个很好的起点,但书籍和期刊文章通常会有最好的信息。
- 研究以往的工作。来自过去Kaggle比赛的解决方案是很好的资源。
- 使用数据可视化。可视化可以揭示特征分布中的问题或可以简化的复杂关系。确保在特征工程过程中可视化你的数据集。
数学变换
数值特征之间的关系通常通过数学公式表达,这些公式你会在领域研究中经常遇到。在Pandas中,你可以像对待普通数字一样对列进行算术运算。
在汽车数据集中有描述汽车引擎的特征。研究产生了各种创建潜在有用新特征的公式。例如,”冲程比”是衡量引擎效率与性能的指标:
1 | autos["stroke_ratio"] = autos.stroke / autos.bore |
组合越复杂,模型学习就越困难,比如这个计算引擎”排量”(功率指标)的公式:
1 | autos["displacement"] = ( |
数据可视化可以提示转换,通常是通过幂或对数”重塑”特征。例如,美国事故数据集中的WindSpeed分布高度偏斜,在这种情况下对数变换能有效地使其正常化:
1 | # 如果特征有0.0值,使用np.log1p (log(1+x))代替np.log |
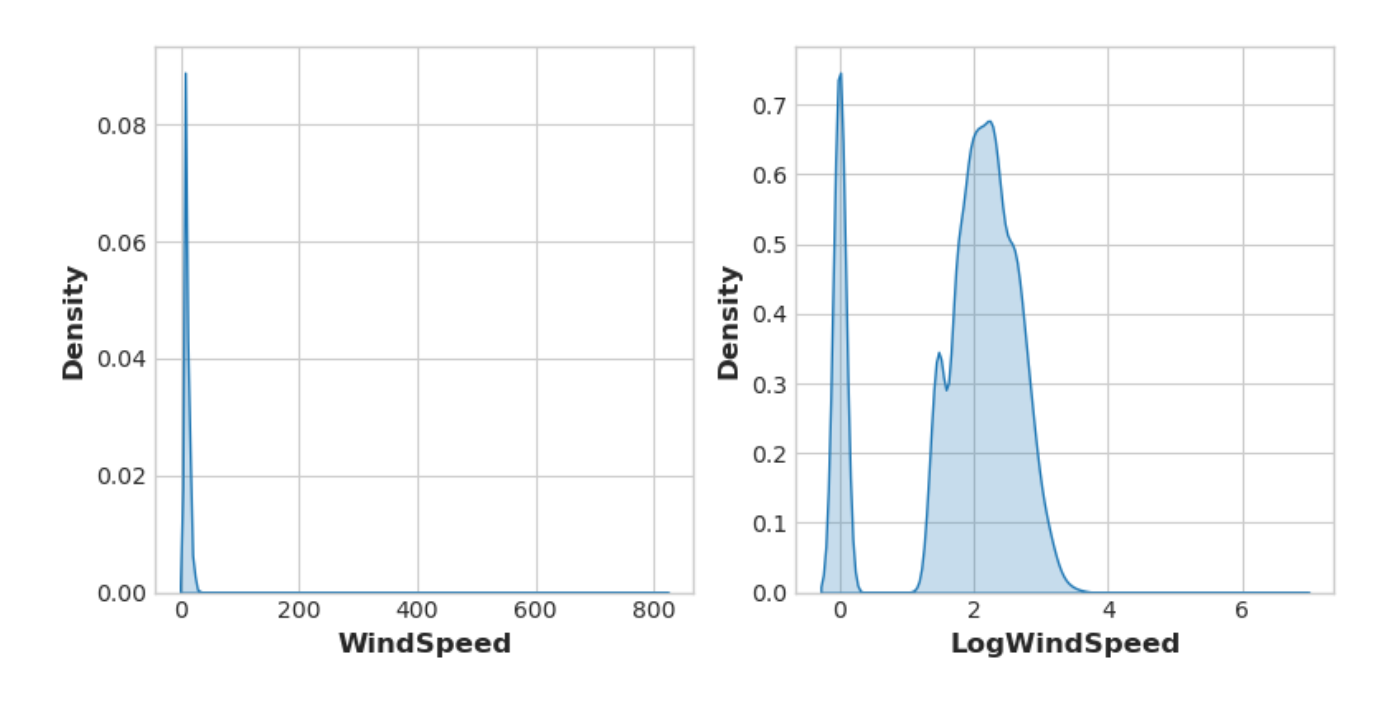
查看我们的Data Cleaning课程,你还将学习Box-Cox变换,这是一种非常通用的规范化器。
计数(Counts)
描述某物存在或不存在的特征通常成组出现,例如疾病的风险因素集合。你可以通过创建计数来聚合此类特征。
这些特征将是二元的(1表示存在,0表示不存在)或布尔型(True或False)。在Python中,布尔值可以像整数一样相加。
交通事故数据集中有几个特征表明某些道路物体是否在事故附近。这将创建一个使用sum方法计算附近道路特征总数的计数:
1 | # “便利设施”“凸起”“十字路口”“让行”“交叉路口”“无出口”“铁路”“环形交叉路口”“车站”“停车”“交通减速”“交通信号灯” |
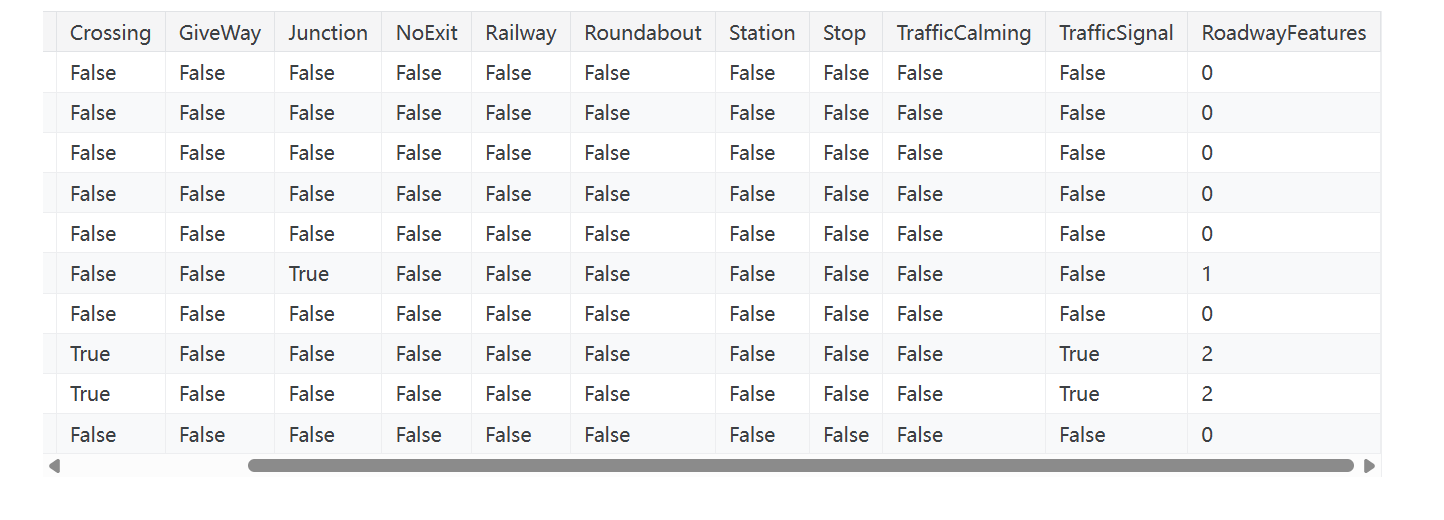
译者注:这里的计数可以反映道路环境的复杂性。比如值为0表示附近没有任何道路特征,而较高的值意味着该区域道路基础设施较为复杂。从表格数据来看,你可以观察到大多数样本的”RoadwayFeatures”值为0,表示附近没有特殊道路设施,而少数样本有1个或2个特征。这种模式可能是事故预测的重要信号。
你也可以使用数据框的内置方法来创建布尔值。在混凝土数据集中有混凝土配方的成分含量。许多配方缺少一种或多种成分(即,该成分的值为0)。下面将计算一个配方中包含的成分数量,使用数据框的内置大于(gt)方法:
1 | components = ["Cement", "BlastFurnaceSlag", "FlyAsh", "Water", |
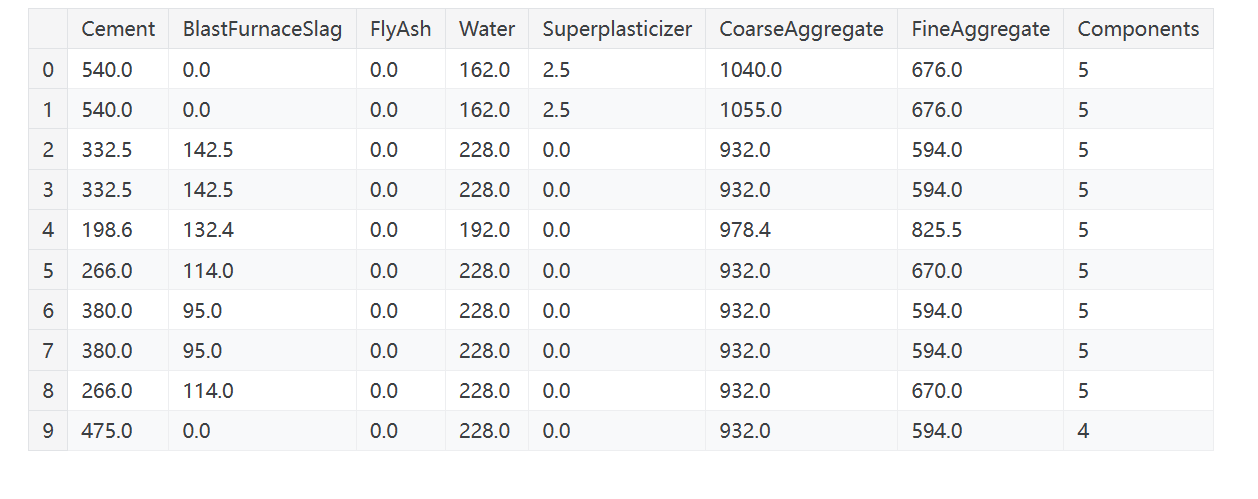
组合和分解特征
通常你会遇到可以有效分解为更简单部分的复杂字符串。一些常见的例子:
- ID号码:’123-45-6789’
- 电话号码:’(999) 555-0123’
- 街道地址:’8241 Kaggle Ln., Goose City, NV’
- 互联网地址:’http://www.kaggle.com‘
- 产品代码:’0 36000 29145 2’
- 日期和时间:’Mon Sep 30 07:06:05 2013’
这类特征通常有某种结构可以利用。例如,美国电话号码有一个区号部分(‘(999)’),它告诉你来电者的位置。一如既往,一些研究可能会有所帮助。
str访问器允许你直接对列应用字符串方法,如split。客户终身价值数据集包含描述保险公司客户的特征。从Policy特征中,我们可以分离出Type和Level覆盖类型:
1 | customer[["Type", "Level"]] = ( # 创建两个新特征 |
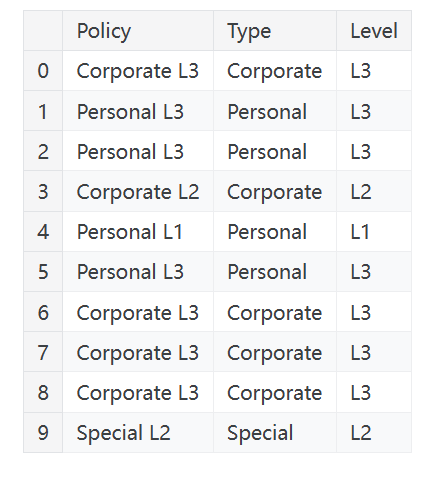
如果你有理由相信某些特征组合存在交互,你也可以将简单特征组合成一个复合特征:
1 | autos["make_and_style"] = autos["make"] + "_" + autos["body_style"] |

译者注:原始特征可能与目标变量有直接关系,而复合特征可能捕捉到额外的交互效应。因此,一般建议创建复合特征的同时也保留原始特征。
分组转换(Group Transforms)
最后是分组转换,它能汇总多个按某种类别分组的行的信息。通过分组转换,您可以创建诸如“某人居住州的平均收入”或“按类型划分的工作日上映电影的比例”之类的特征。如果您发现了类别交互作用,针对该类别的分组转换可能是值得研究的。
使用聚合函数,分组转换会结合两个特征:一个用于分组的分类特征以及另一个您希望对其值进行聚合的特征。对于“按州划分的平均收入”,您会将“州”选为分组特征,将“平均值”选为聚合函数,将“收入”选为聚合特征。在 Pandas 中计算此值时,我们使用 groupby 和 transform 方法:
1 | customer["AverageIncome"] = ( |
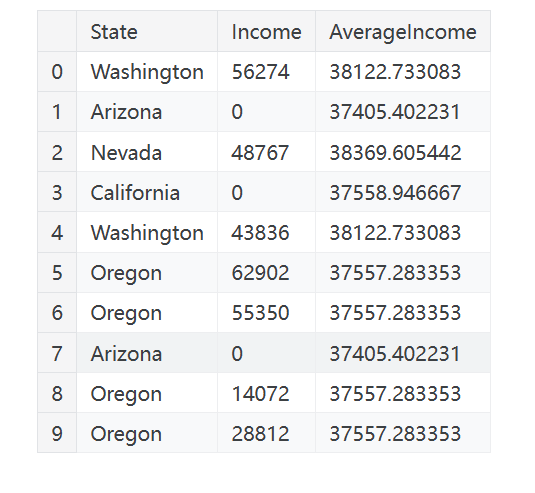
mean函数是一个内置的dataframe方法,这意味着我们可以将其作为字符串去transform。其他有用的方法包括max、min、median、var、std和count。下面是如何计算每个州在数据集中出现的频率:
1 | customer["StateFreq"] = ( |

你可以使用这样的转换为分类特征创建”频率编码(frequency encoding)”。
如果你使用训练和验证数据集分割,为了保持它们的独立性,最好只使用训练集创建分组特征,然后将其合并到验证集中。
1 | # 创建分割 |
创建特征的建议(重要!)
在创建特征时,记住你的模型本身的优势和劣势很重要。以下是一些指导原则:
- 线性模型本身可以学习和与差,但无法学习更复杂的关系。
- 比率似乎对大多数模型来说都很难学习。比率组合通常能带来一些简单的性能提升。
- 线性模型和神经网络通常在标准化特征上表现更好。神经网络特别需要将特征缩放到不太远离0的值。基于树的模型(如随机森林和XGBoost)有时也能从标准化中受益,但通常受益程度要小得多。
- 树模型能学习近似任何特征组合,但当某个组合特别重要时,它们仍然可以从显式创建该组合中受益,尤其是在数据有限的情况下。
- 计数对树模型特别有帮助,因为这些模型没有一种自然的方式来一次性聚合多个特征的信息。
K-Means聚类
本课程和下一课使用的是所谓的无监督学习算法。无监督算法不使用目标变量;相反,它们的目的是学习数据的某些特性,以某种方式表示特征的结构。在预测的特征工程背景下,你可以将无监督算法视为一种”特征发现”技术。
聚类简单来说就是根据数据点之间的相似程度将它们分配到不同组中。当用于特征工程时,我们可以尝试发现共享相似类型的部分变量,例如,共享相似天气模式的地理区域。添加聚类标签特征可以帮助机器学习模型解开空间或接近度的复杂关系。
聚类标签作为特征(Cluster Labels as a Feature)
应用于单个实值特征时,聚类的作用类似于传统的”分箱”或”离散化”转换。在多个特征上,它就像是”多维分箱(multi-dimensional binning)”(有时称为向量量化)。
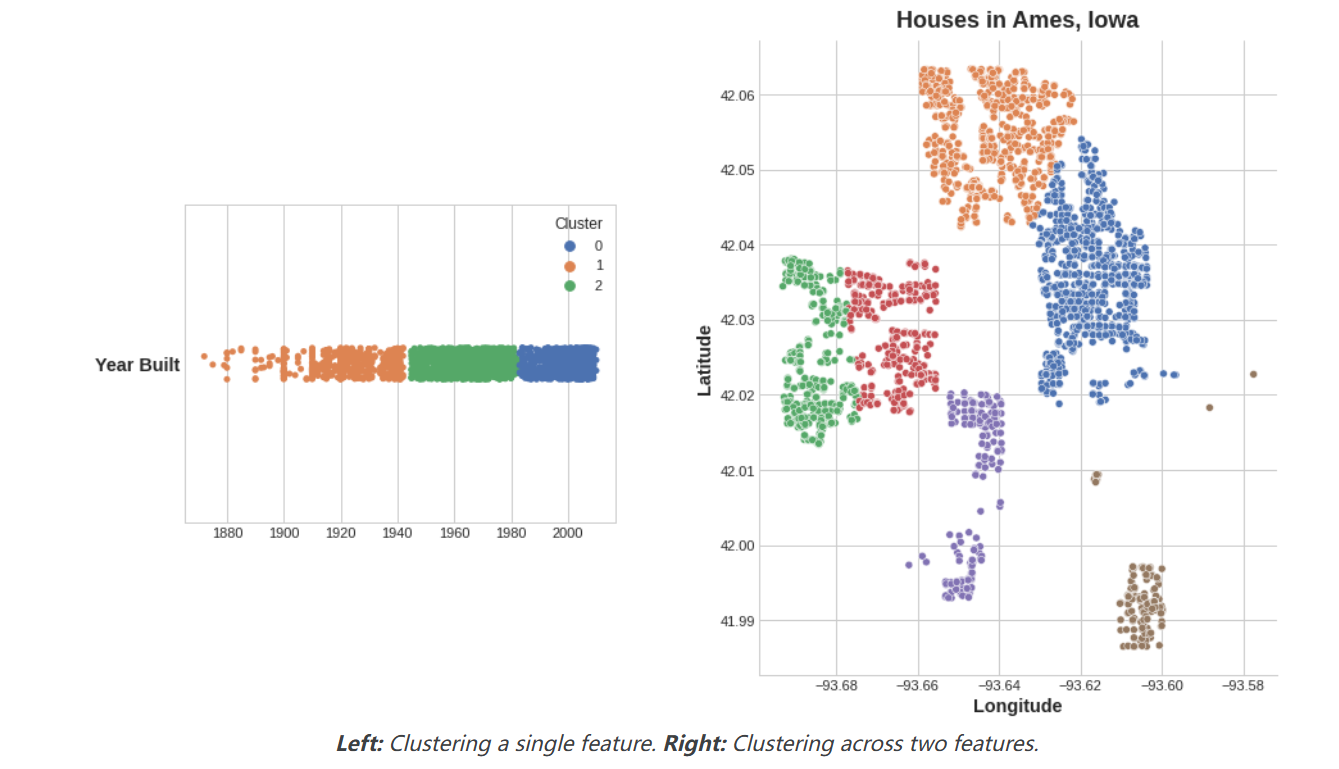
添加到dataframe中,聚类标签特征可能看起来像这样:
| Longitude | Latitude | Cluster |
|---|---|---|
| -93.619 | 42.054 | 3 |
| -93.619 | 42.053 | 3 |
| -93.638 | 42.060 | 1 |
| -93.602 | 41.988 | 0 |
重要的是要记住,这个聚类特征是分类型变量(categorical)。这里,它显示为标签编码(即作为整数序列),这是典型聚类算法产生的结果;根据你的模型,也可能更适合使用独热编码。
添加聚类标签的动机是聚类将把特征之间的复杂关系分解成更简单的块。我们的模型然后可以一个接一个地学习这些更简单的块,而不必同时学习整个复杂的关系。这是一种”分而治之”的策略。
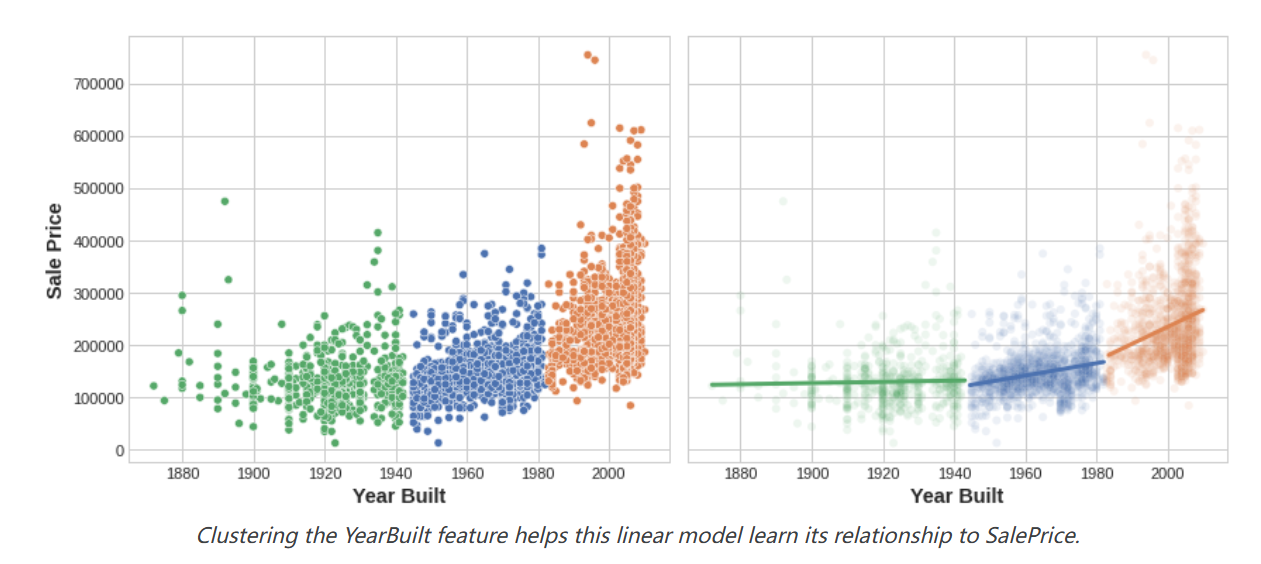
图中显示了聚类如何改进简单的线性模型。建造年份和销售价格之间的曲线关系对这种模型来说太复杂了——它欠拟合。然而,在较小的块上,关系几乎是线性的,模型可以轻松学习。
K-Means聚类
世界上有很多聚类算法。它们主要在如何衡量”相似性”或”接近度”以及适用于哪类特征方面有所不同。我们将使用的k均值算法,在特征工程上下文中直观且易于应用。根据你的应用,另一种算法可能更合适。
K-Means使用普通直线距离(即欧几里得距离)来衡量相似性。它通过在特征空间内放置一些点(称为中心点)来创建聚类。数据集中的每个点都被分配到与其距离最近的中心点的聚类。”k均值”中的”k”表示它创建的中心点(即聚类)数量。你可以自己定义k值。
你可以想象每个中心点通过一系列辐射圆捕获点。当来自竞争中心点的圆集重叠时,它们形成一条线。结果是所谓的Voronoi图案。该图案展示了未来数据将被分配到哪些聚类;该图案本质上是k均值从其训练数据中学到的内容。
上面Ames数据集的聚类是一个k均值聚类。这里显示的是同一张图,但包含了图案和中心点。
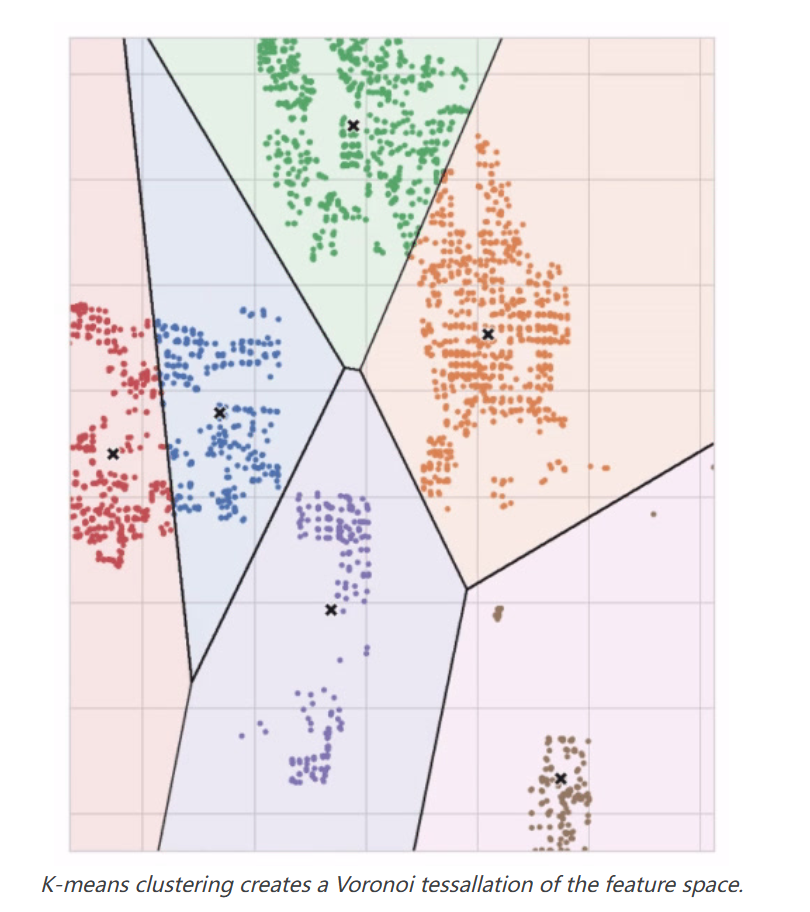
让我们回顾一下k均值算法如何学习聚类以及这对特征工程意味着什么。我们将关注scikit-learn实现中的三个参数:n_clusters、max_iter和n_init。
这是一个简单的两步过程。算法首先随机初始化一些预定义数量(n_clusters)的中心点。然后它对这两个操作进行迭代:
- 将点分配到最近的聚类中心点
- 移动每个中心点以最小化到其点的距离
它会不断迭代这两个步骤,直到中心点不再移动,或者直到达到某个最大迭代次数(max_iter)。
经常发生的情况是,中心点的初始随机位置会导致不良的聚类。因此,算法会重复多次(n_init),并返回点到其中心点总距离最小的聚类,即最优聚类。
下面的动画展示了算法的运行过程。它说明了结果对初始中心点的依赖性以及迭代至收敛的重要性。
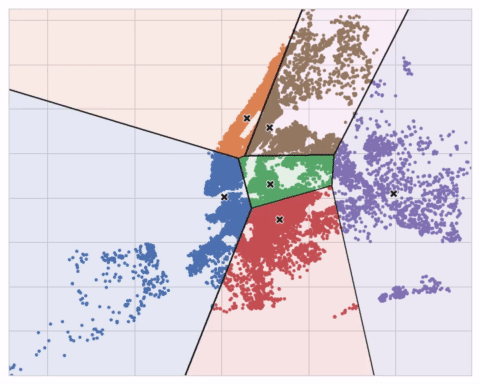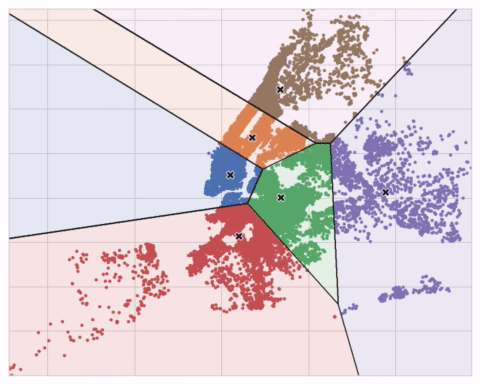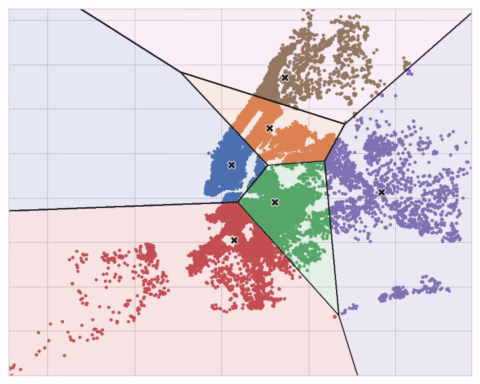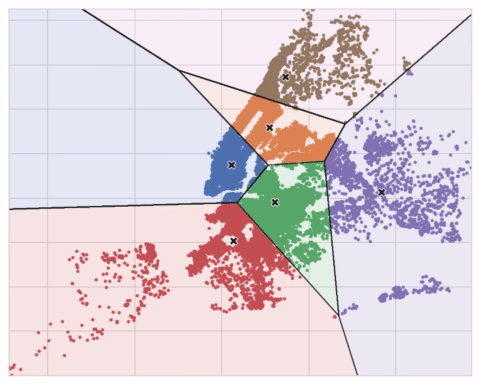
对于大量聚类或复杂数据集,你可能需要增加max_iter或n_init。但通常,你自己需要选择的唯一参数是n_clusters(即k值)。一组特征的最佳划分取决于你使用的模型和你试图预测的内容,所以最好像任何超参数一样调整它(比如通过交叉验证)。
示例 - 加州住房
作为空间特征,加州住房数据集的纬度和经度是k均值聚类的自然候选。在这个例子中,我们将这些特征与中位收入(MedInc)一起聚类,以创建加州不同地区的经济部门。
由于k均值聚类对尺度敏感,对有极值的数据进行重新缩放或标准化是个好主意。我们的特征已经大致在同一尺度上,所以我们将保持原样。
1 | # 创建聚类特征 |
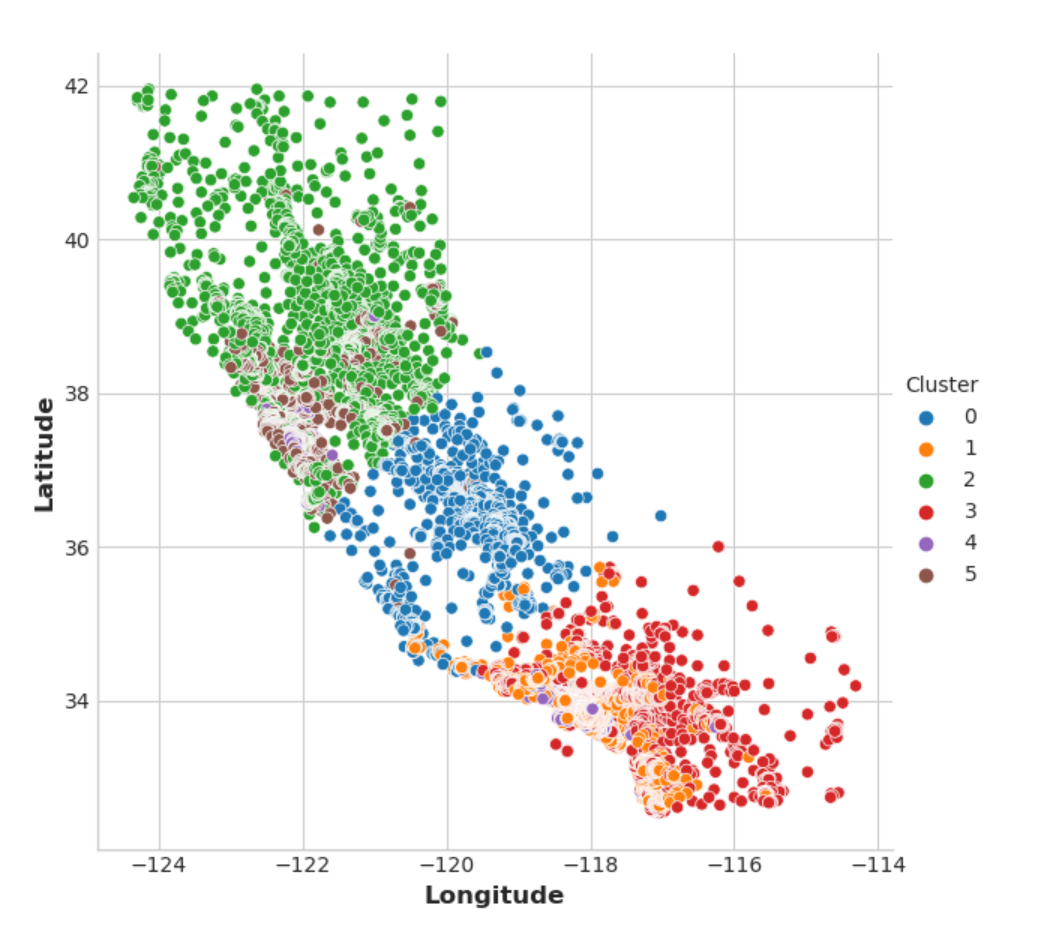
现在让我们看几个图表来看看这有多有效。首先,一个显示聚类地理分布的散点图。看起来算法为沿海地区的高收入区域创建了单独的部分。
1 | sns.relplot( |
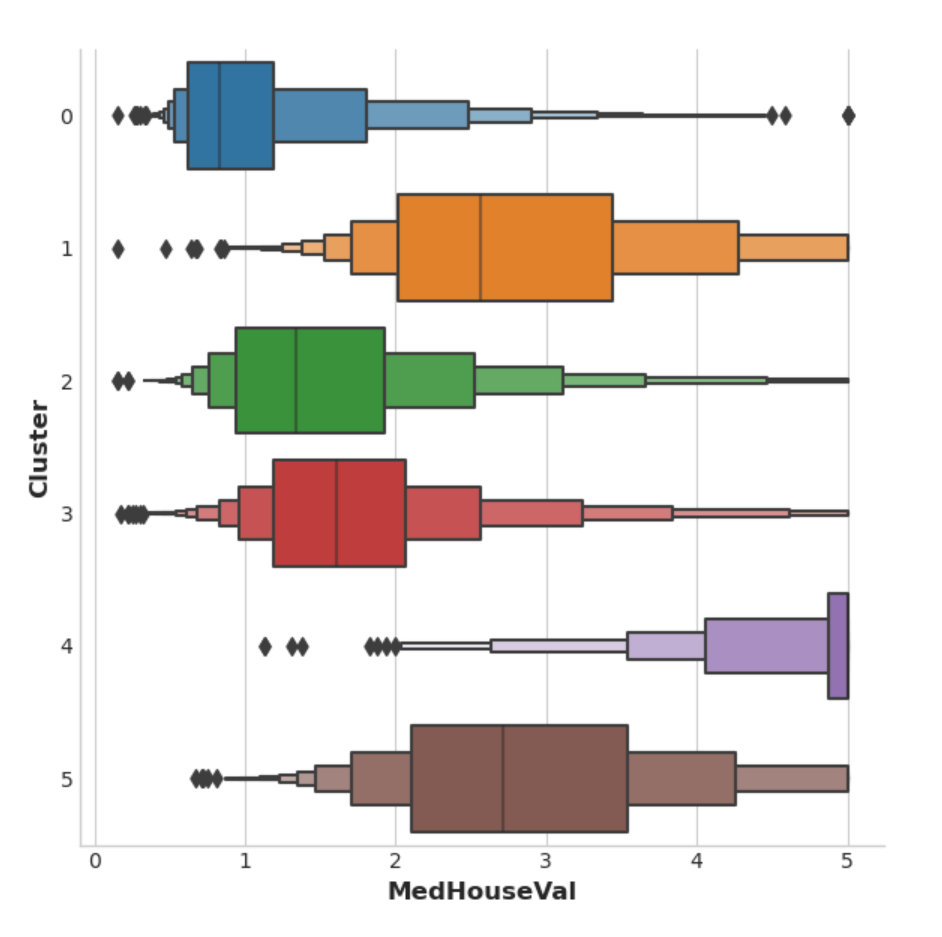
该数据集的目标是MedHouseVal(中位房屋价值)。这些箱线图显示了每个聚类内目标的分布。如果聚类信息丰富,这些分布应该在MedHouseVal上大部分分开,而这正是我们所看到的。
1 | X["MedHouseVal"] = df["MedHouseVal"] |
 微信
微信 支付寶
支付寶



