FeatureEngineering01
特征工程入门
在本课程中,您将学习构建优秀机器学习模型过程中最重要的步骤之一:特征工程。您将学习如何:
- 通过 mutual information(互信息)确定哪些特征最重要
- 创建新特征
- 使用 target encoding(目标编码)编码高基数类别变量
- 使用 k-means clustering(k均值聚类)创建分割特征
- 使用 principal component analysis(主成分分析)将数据集的变异分解为特征
实践练习将逐步引导您完成一个完整的 notebook,应用所有这些技术参加 House Prices Getting Started 比赛。完成本课程后,您将获得多种可用于进一步提高模型性能的思路。
准备好了吗?让我们开始吧!
特征工程的目标
特征工程的目标很简单:使您的数据更适合所面临的问题。
考虑“表面温度”测量,则你会将热指数和风寒指数作为特征。这些量试图根据空气温度、湿度和风速来测量人类感知的温度,这些都是我们可以直接测量的。你可以把表面温度看作是一种特征工程的结果,它试图使观察到的数据与我们真正关心的东西更相关:外面的实际感觉如何!
您可能执行特征工程的目的:
- 提高模型的预测性能
- 减少计算或数据需求
- 提高结果的可解释性
特征工程的指导原则
要使特征有用,它必须与您的模型能够学习的目标有关系。例如,线性模型只能学习线性关系。因此,在使用线性模型时,您的目标是转换特征,使其与目标的关系成为线性的。
这里的关键思想是,您应用于特征的转换本质上成为了模型本身的一部分。假设您试图根据一边的 Length(长度)预测土地方块的 Price(价格)。直接对 Length 拟合线性模型会得到较差的结果:这种关系不是线性的。

然而,如果我们将长度特征平方得到“面积”,我们就创造了一个线性关系。向特征集添加Area意味着这个线性模型现在可以拟合抛物线。换句话说,对特征进行平方,使线性模型具有拟合平方特征的能力。

这向您展示了为什么在特征工程上投入的时间可以获得如此高的回报。无论您的模型无法确认什么特征关系,您都可以通过转换提供给自己。在开发特征集合时,请考虑您的模型可以使用哪些信息来实现最佳性能。
示例 - 混凝土配方
为了说明这些概念,我们将看到如何通过向数据集添加几个合成特征来提高随机森林模型的预测性能。
Concrete数据集包含各种混凝土配方及其产品的 compressive strength(抗压强度),这是衡量该类混凝土能承受多大负荷的指标。该数据集的任务是根据混凝土的配方预测其抗压强度。
1 | import pandas as pd |
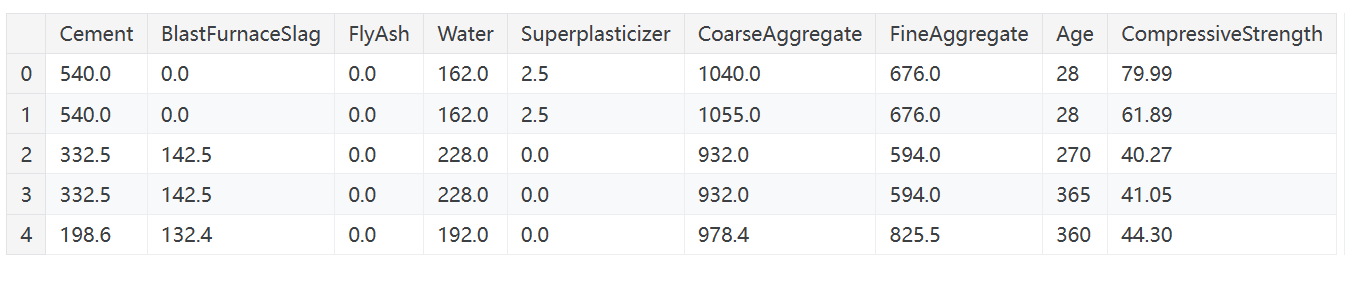
您可以在这里看到进入每种混凝土的各种成分。我们将很快看到,添加一些从这些成分派生的额外合成特征如何帮助模型学习它们之间的重要关系。
我们首先通过在未增强的数据集上训练模型来建立基准。这将帮助我们确定我们的新特征是否真正有用。
在特征工程过程开始时建立这样的基准是一种很好的做法。基准分数可以帮助您决定是否值得保留新特征,或者是否应该放弃它们并尝试其他方法。
1 | X = df.copy() |
1 | MAE Baseline Score: 8.232 |
如果您在家里做饭,您可能知道配方中成分的 ratio(比例)通常比它们的绝对数量更能预测菜肴的最终效果。因此,我们可以推断上述特征的比例可能是预测 CompressiveStrength 的良好指标。
下面的代码单元向数据集添加了三个新的比例特征。
1 | X = df.copy() |
1 | MAE Score with Ratio Features: 7.948 |
果然,性能提高了!这表明,这些新的比率特征向模型暴露了以前没有检测到的重要信息。
互信息(Mutual Information)
初次接触新数据集有时会让人感到不知所措。您可能会面对数百或数千个特征,甚至没有描述可以参考。该从哪里开始呢?
一个很好的第一步是构建一个使用特征效用度量(feature utility metric)的排名,这是一个衡量特征与目标之间关联的函数。然后,您可以选择一组较小的最有用特征进行初步开发,并有更大的信心确保您的时间得到充分利用。
我们将使用的度量称为”互信息”(mutual information)。互信息类似于相关性,因为它衡量两个量之间的关系。互信息的优势在于它可以检测任何类型的关系,而相关性只能检测线性关系。
互信息是一种很好的通用度量,特别适用于特征开发的早期阶段,当您可能还不知道要使用哪种模型。它具有以下特点:
- 易于使用和解释
- 计算效率高
- 理论基础扎实
- 抗过拟合
- 能够检测任何类型的关系
互信息及其测量内容
互信息通过不确定性(uncertainty)描述关系。两个量之间的互信息(MI)是衡量了解一个量在多大程度上减少了对另一个量的不确定性。如果您知道某个特征的值,您对目标的确信程度会提高多少?
这里有一个来自Ames Housing数据的例子。图表显示了房屋外观质量与售价之间的关系。每个点代表一所房屋。

从图中可以看出,了解ExterQual的值应该会让您对相应的SalePrice更加确定——每个ExterQual类别往往将SalePrice集中在一定范围内。ExterQual与SalePrice之间的互信息是SalePrice的不确定性平均减少量,这个减少量是在ExterQual的四个值上取的。例如,因为Fair出现的频率低于Typical,所以Fair在MI评分中的权重较小。
(说明:我们所说的不确定性是用信息论中一个称为”熵”的量来衡量的。一个变量的熵大致意味着:”平均而言,需要多少个是非问题才能描述该变量的一次出现。”您需要问的问题越多,对变量的不确定性就越大。互信息是指您期望特征能够回答关于目标的问题数量。)
解读互信息分数
特征与目标量之间可能的最小互信息是0.0。当MI为零时,这些量是独立的:它们之间互相无法提供任何信息。相反,理论上MI没有上限。但在实践中,超过2.0左右的值并不常见。(互信息是一个对数量,所以它增长得非常缓慢。)
下图将让您了解MI值如何对应于特征与目标之间的关联类型和程度。
。")
应用互信息时需要记住的几点:
- MI可以帮助您了解单独考虑时特征作为目标预测因子的相对潜力。
- 一个特征在与其他特征交互时可能非常有信息,但单独时可能不那么有信息。MI无法检测特征之间的交互。它是一个单变量度量。
- 特征的实际有用性取决于您使用的模型。特征只有在其与目标的关系是您的模型可以学习的关系时才有用。仅仅因为一个特征具有高MI分数并不意味着您的模型将能够利用这些信息。您可能需要先转换特征以揭示关联。
示例 - 1985年汽车数据
Automobile数据集包含193辆1985年款汽车。该数据集的目标是从汽车的23个特征(如 make(制造商)、body_style(车身样式)和 horsepower(马力))来预测汽车的 price(价格,即目标变量)。在本示例中,我们将使用互信息对特征进行排名,并通过数据可视化研究结果。
这个隐藏的代码单元导入了一些库并加载了数据集。
数据预览

特征类型处理
scikit-learn算法对离散特征和连续特征的MI计算方式不同。因此,您需要告诉它哪些分别是哪类特征。根据经验,任何必须具有 float 数据类型的都不是离散的。类别型变量(object 或 categorical 数据类型)可以通过标签编码来处理为离散型。
1 | X = df.copy() |
for colname in X.select_dtypes("object")::这是一个循环,它会遍历所有”object”类型的列名。
X[colname].factorize():对于每一个”object”类型的列,这行代码调用pandas的factorize()方法。这个方法将分类(如”audi”、”bmw”等汽车制造商)转换为数字编码(如0、1、2等),并返回一个元组,其中包含:(1)编码后的值数组,(2)原始唯一值的索引。
X[colname], _ = X[colname].factorize():这行代码将factorize()返回的编码数组赋值给原始列,同时使用_丢弃不需要的唯一值索引。
scikit-learn在其 feature_selection 模块中有两个互信息度量:一个用于实值目标(mutual_info_regression)和一个用于分类目标(mutual_info_classif)。我们的目标 price 是实值的。下一个单元计算我们特征的MI分数并将它们包装在一个漂亮的数据框中。
1 | from sklearn.feature_selection import mutual_info_regression |
1 | curb_weight 1.540126 |
可视化互信息得分
画一个条形图,使比较更容易:
1 | def plot_mi_scores(scores): |
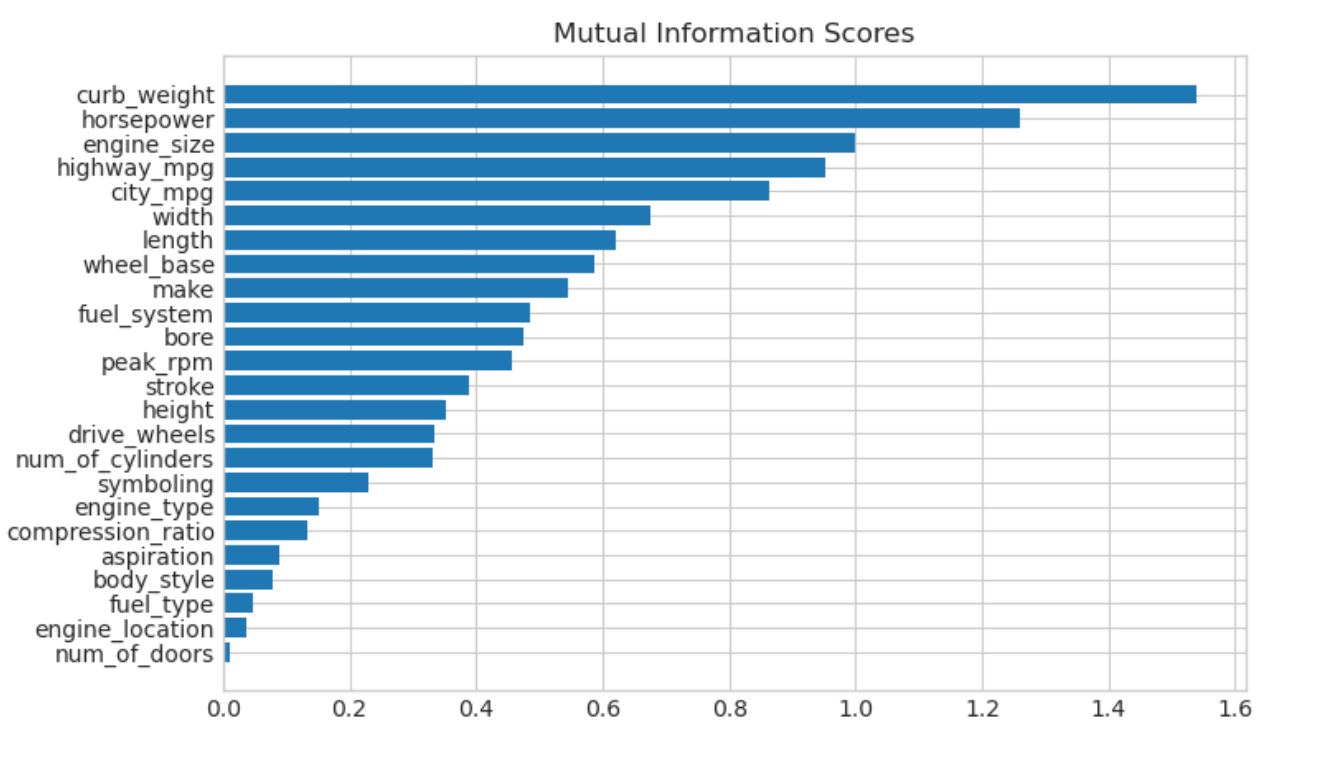
数据可视化是效用排名的一个很好的后续。让我们仔细看看其中的几个。
正如我们所期望的那样,高分的curb_weight特征与目标价格表现出很强的关系。
1 | sns.relplot(x="curb_weight", y="price", data=df); |
fuel_type特性的MI得分相当低,但是从图中可以看出,它在horsepower特性中清楚地区分了两个具有不同趋势的价格群体。这表明fuel_type有助于产生交互影响,并且可能并非不重要。在根据MI分数决定一个功能是否不重要之前,最好先调查一下任何可能的交互影响——相关领域知识可以在这里提供很多指导。
1 | sns.lmplot(x="horsepower", y="price", hue="fuel_type", data=df); |
x="horsepower" - 指定x轴使用数据集中的”horsepower”(马力)列
y="price" - 指定y轴使用数据集中的”price”(价格)列
hue="fuel_type" - 指定按”fuel_type”(燃料类型)列的值对数据点进行着色分组。这会为每个燃料类型创建不同颜色的点和回归线。
这段代码会创建一个散点图,其中每个点代表一辆汽车。对于每种燃料类型,会自动拟合一条单独的回归线。默认情况下,lmplot还会在回归线周围添加置信区间的阴影(图中的浅色区域);回归线使用的是普通最小二乘法(OLS)来拟合。
得出的结论是:马力与价格的关系因燃料类型而异。
这是特征工程中探索变量之间潜在交互效应的典型方法。
总结
互信息(MI)的作用
MI处理方法
MI可视化
潜在特征交互查找
 微信
微信 支付寶
支付寶



