MysqlTutorial03
图片截取及参考文献:
1.https://xiaolincoding.com/mysql/index/index_lose.html#%E7%B4%A2%E5%BC%95%E5%AD%98%E5%82%A8%E7%BB%93%E6%9E%84%E9%95%BF%E4%BB%80%E4%B9%88%E6%A0%B7
2.https://learn.lianglianglee.com/%E4%B8%93%E6%A0%8F/MySQL%E5%AE%9E%E6%88%98%E5%AE%9D%E5%85%B8/11%20%20%E7%B4%A2%E5%BC%95%E5%87%BA%E9%94%99%EF%BC%9A%E8%AF%B7%E7%90%86%E8%A7%A3%20CBO%20%E7%9A%84%E5%B7%A5%E4%BD%9C%E5%8E%9F%E7%90%86.md
3.https://juejin.cn/post/7149074488649318431#heading-1
索引失效及其场景
要了解索引失效,必须了解索引的存储过程和查询原理,因此请务必看完上篇再继续阅读。
接下来,将介绍索引失效的各个场景:
1.对索引使用左或者左右模糊匹配
like %xx 或者 like %xx% 都会导致索引失效,而 like xx%不会。如图所示:
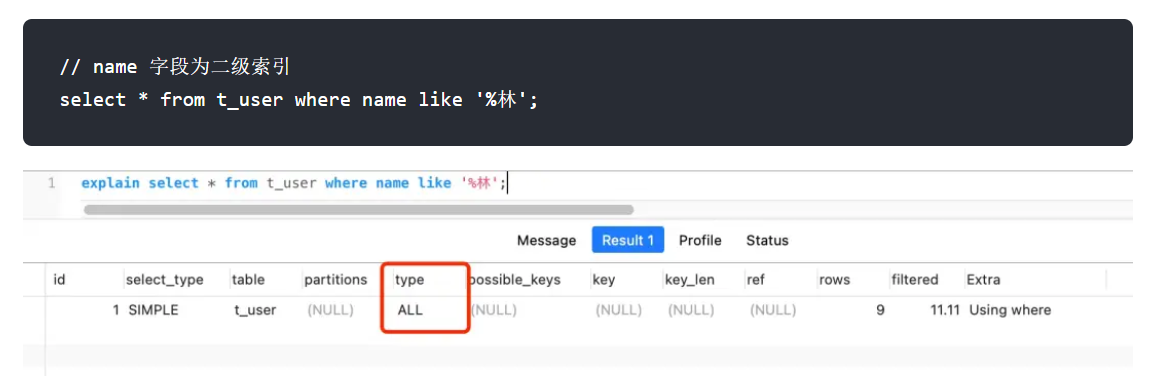
如果是査询 name 前缀为林的用户,那么就会走索引扫描,执行计划中的 type=range 表示走索引扫描key=index_name 看到实际走了 index_name 索引:
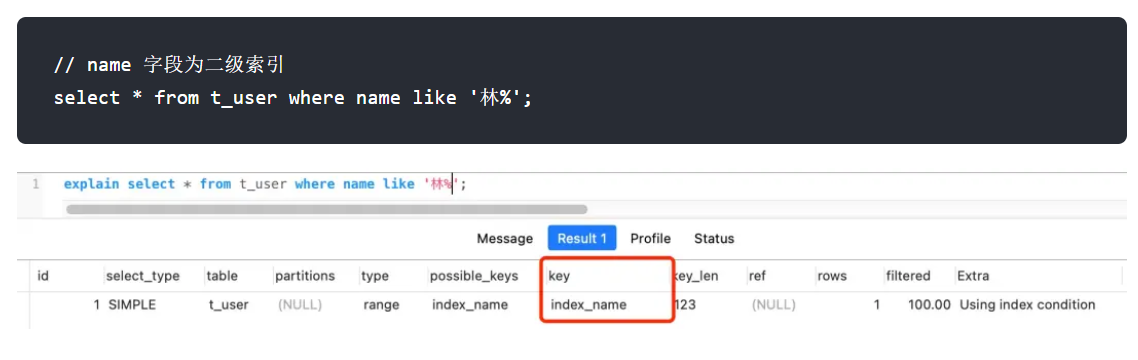
原理:B+树索引的有序特性,无法进行二分查找,因此只能进行全表扫描。
2.对索引使用函数
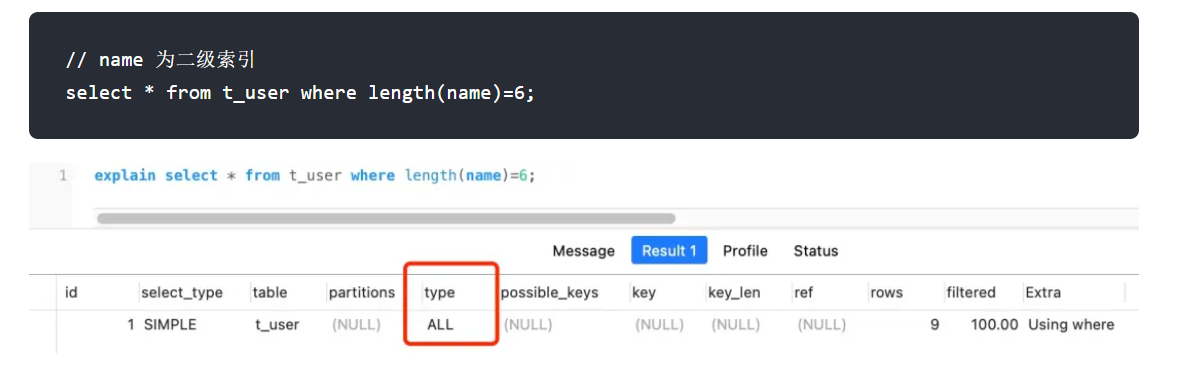
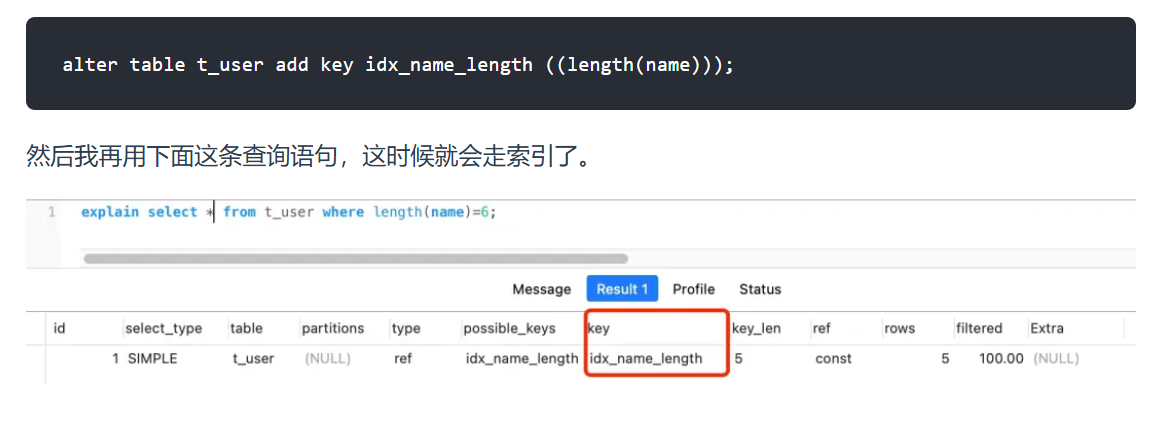
因为索引保存的是索引原始字段的值,不是函数计算后的值,自然没办法使用索引。
不过在mysql8.0版本后,支持对函数建立索引啦!
3.对索引进行表达式计算
在查询条件中对索引进行表达式计算,也是无法走索引的。
比如,下面这条查询语句,执行计划中 type=ALL,说明是通过全表扫描的方式查询数据的:
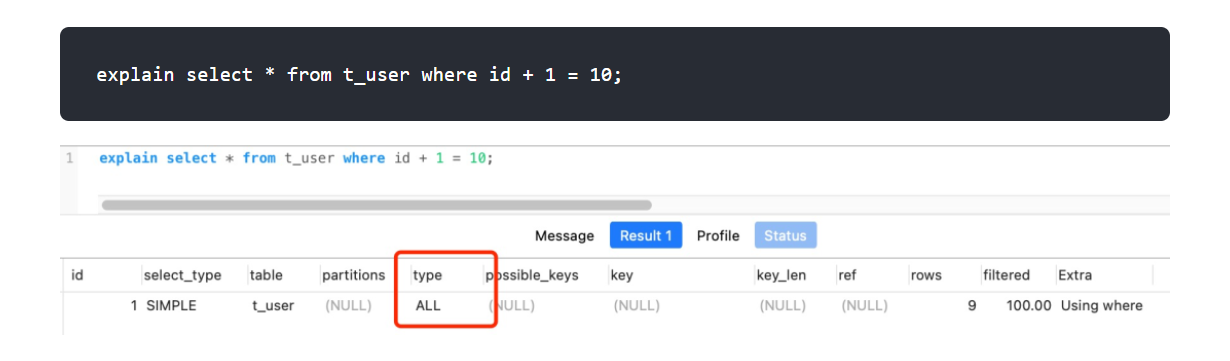
改成where id = 10 -1就可以:
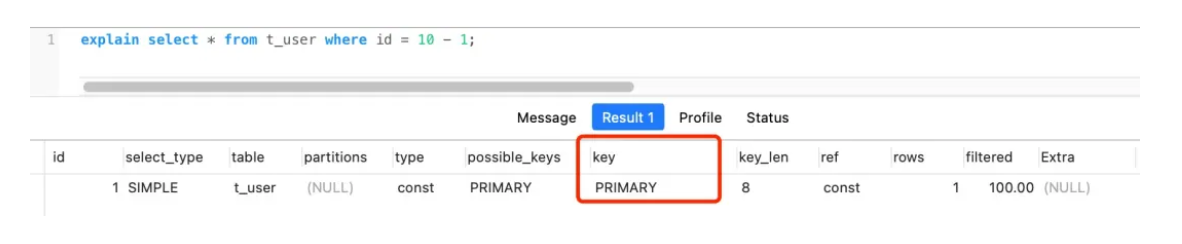
原理和上面的函数部分类似。
4.对索引隐式类型转换
mysql遇到字符串和数字比较时,会把字符串自动转化为数字进行比较。如果在查询过程中对变量发生了类型上的隐式转换,则会发生索引失效。
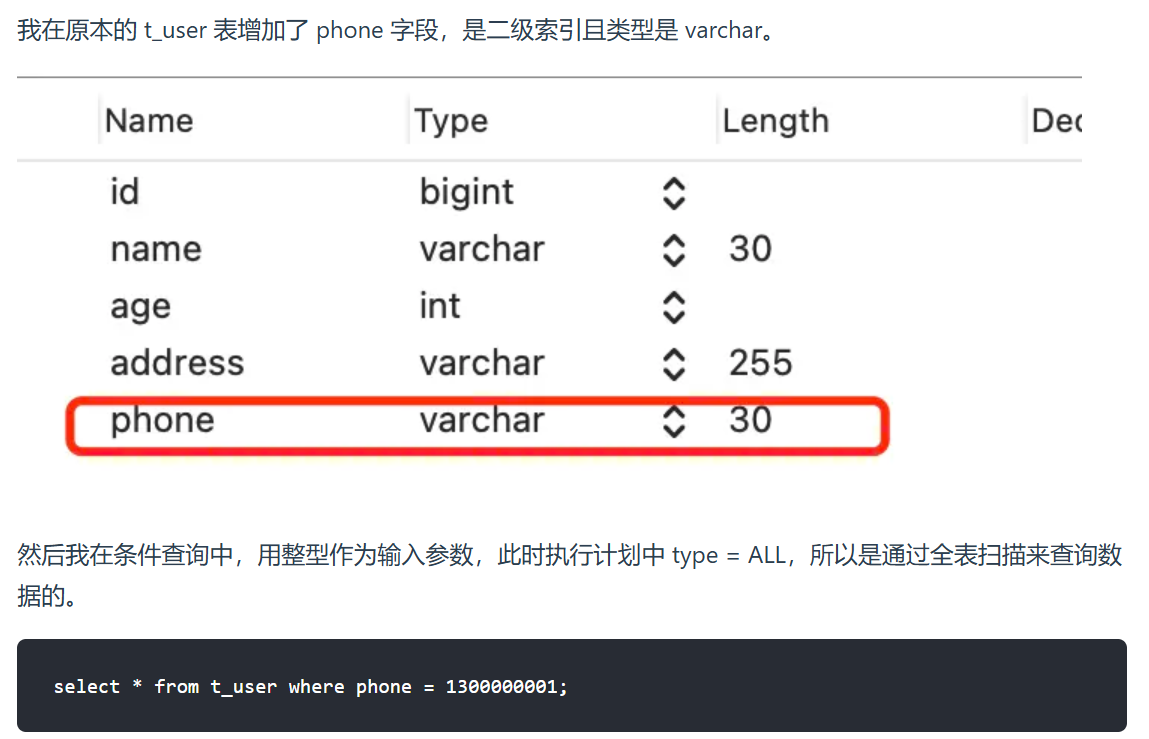
这条语句相当于:
1 | select * from t user where CAST(phone As signed int)= 1300000001; |
因此失效。
反过来,若对变量无影响,则照常走索引:

5.联合索引的非最左匹配
上一篇也有讲到,但是我们这里再着重讲一下索引下推。
比如建立了索引(a,b,c),查询where a = 1 and c = 3,还走索引嘛?符合最左匹配嘛?
MySQL 5.5 的话,前面a会走索引,在联合索引找到主键值后,开始回表,到主键索引读取数据行Server 层从存储引擎层获取到数据行后,然后在 Server 层再比对c字段的值。
从 MvSOL5.6之后,有一个索引下推功能,可以在存储引擎层进行索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,再返还给 Server 层,从而减少回表次数。
索引下推的大概原理是:截断的字段不会在 Server 层进行条件判断,而是会被下推到「存储引擎层」进行条件判断(因为c字段的值是在(a,b,c)联合索引里的),然后过滤出符合条件的数据后再返回给Server 层。由于在引擎层就过滤掉大量的数据,无需再回表读取数据来进行判断,减少回表次数,从而提升了性能。
比如下面这条 where a=1 and c=0语句,我们可以从执行计划中的Extra=Using index condition使用了索引下推功能。

6.WHERE句子中的OR
如果or的两个条件其中有一个不是索引,那就会走全表扫描使得索引失效。
其实也很好理解,or的意思是只要满足一个条件就行,那肯定是以最麻烦的那个为准咯。
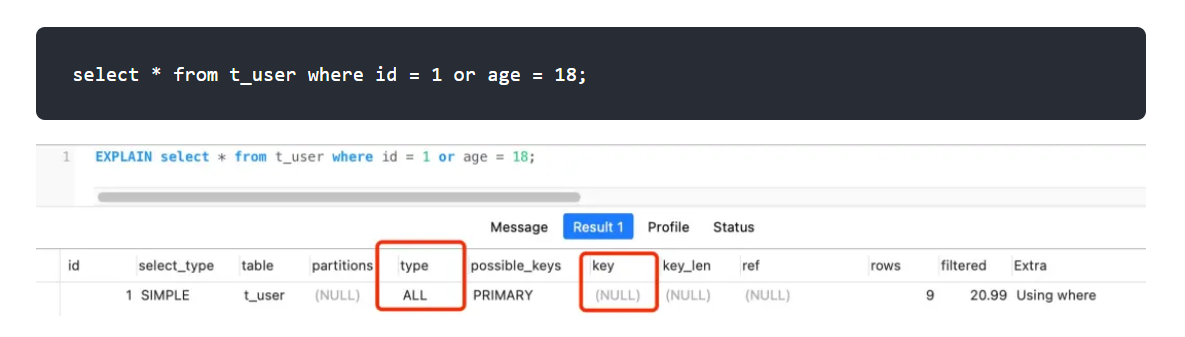
解决方法?将age设置为索引呗。

可以看到 type=index merge, index merge 的意思就是对id 和 age 分别进行了扫描,然后将这两个结果集进行了合并,这样做的好处就是避免了全表扫描。
索引选择及其标准
很显然,涉及到查询路径的问题那就和server层的sql优化器脱不了关系。这里介绍的是:CBO(Cost-based Optimizer,基于成本的优化器)。
在 MySQL中,一条 SQL 的计算成本计算如下所示:
1 | Cost = Server Cost + Engine Cost |
其中,CPU Cost 表示计算的开销,比如索引键值的比较、记录值的比较、结果集的排序……这些操作都在 Server 层完成;
IO Cost 表示引擎层 IO 的开销,MySQL 8.0 可以通过区分一张表的数据是否在内存中,分别计算读取内存 IO 开销以及读取磁盘 IO 的开销。
数据库 mysql 下的表 server_cost、engine_cost 则记录了对于各种成本的计算,如:
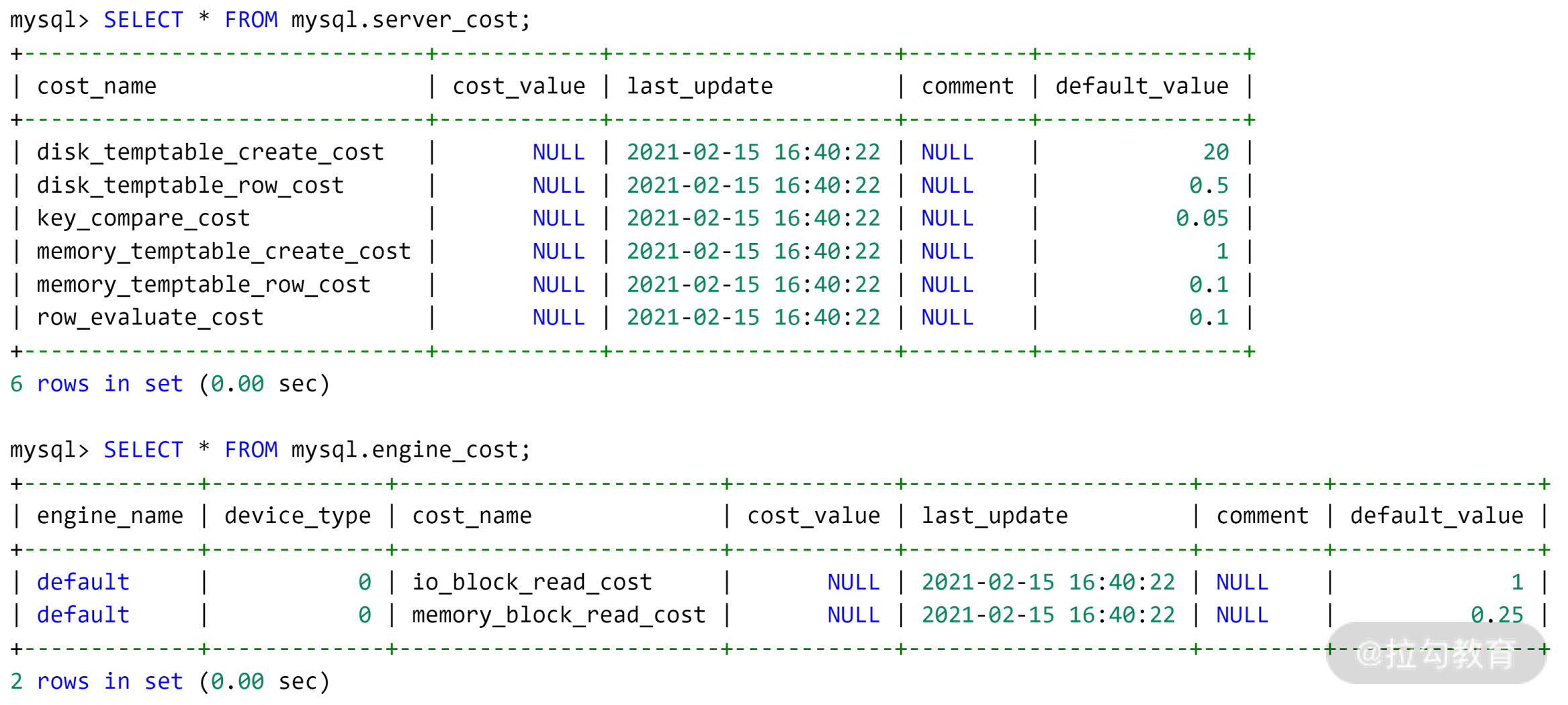
表 server_cost 记录了 Server 层优化器各种操作的成本,这里面包括了所有 CPU Cost,其具体含义如下。
- disk_temptable_create_cost:创建磁盘临时表的成本,默认为20。
- disk_temptable_row_cost:磁盘临时表中每条记录的成本,默认为0.5。
- key_compare_cost:索引键值比较的成本,默认为0.05,成本最小。
- memory_temptable_create_cost:创建内存临时表的成本:默认为1。
- memory_temptable_row_cost:内存临时表中每条记录的成本,默认为0.1。
- row_evaluate_cost:记录间的比较成本,默认为0.1。
可以看到, MySQL 优化器认为如果一条 SQL 需要创建基于磁盘的临时表,则这时的成本是最大的,其成本是基于内存临时表的 20 倍。而索引键值的比较、记录之间的比较,其实开销是非常低的,但如果要比较的记录数非常多,则成本会变得非常大。
而表 engine_cost 记录了存储引擎层各种操作的成本,这里包含了所有的 IO Cost,具体含义如下。
- io_block_read_cost:从磁盘读取一个页的成本,默认值为1。
- memory_block_read_cost:从内存读取一个页的成本,默认值为0.25。
也就是说, MySQL 优化器认为从磁盘读取的开销是内存开销的 4 倍。
在知道 MySQL 索引选择是基于 SQL 执行成本之后,接下来,我们就能分析一些索引出错问题到底是怎么回事了。
1.未能使用创建的索引
MySQL 优化器永远是根据成本,选择出最优的执行计划。哪怕是同一条 SQL 语句,只要范围不同,优化器的选择也可能不同。
如下面这两条 SQL:
1 | SELECT * FROM orders |
上面这两条 SQL 都是通过索引字段 o_orderdate 进行查询,然而第一条 SQL 语句的执行计划并未使用索引 idx_orderdate,而是使用了如下的执行计划:
1 | EXPLAIN SELECT * FROM orders |
从上述执行计划中可以发现,优化器已经通过 possible_keys 识别出可以使用索引 idx_orderdate,但最终却使用全表扫描的方式取出结果。 最为根本的原因在于:优化器认为使用通过主键进行全表扫描的成本比通过二级索引 idx_orderdate 的成本要低,可以通过 FORMAT=tree 观察得到:
1 | EXPLAIN FORMAT=tree |
可以看到,MySQL 认为全表扫描,然后再通过 WHERE 条件过滤的成本为 592267.11,对比强制使用二级索引 idx_orderdate 的成本为 844351.87。
成本上看,全表扫描低于使用二级索引。故,MySQL 优化器没有使用二级索引 idx_orderdate。
为什么全表扫描比二级索引查询快呢? 因为二级索引需要回表,当回表的记录数非常大时,成本就会比直接扫描要慢,因此这取决于回表的记录数。
所以,第二条 SQL 语句,只是时间范围发生了变化,但是 MySQL 优化器就会自动使用二级索引 idx_orderdate了:
1 | EXPLAIN SELECT * FROM orders |
2.数据倾斜造成优化器误判
此时可以创立直方图,对mysql优化器进行矫正。
原文如下:
……由于字段 o_orderstatus 仅有三个值,分别为 ‘O’、’P’、’F’。但 MySQL 并不知道这三个列的分布情况,认为这三个值是平均分布的,但其实是这三个值存在严重倾斜:
1 | SELECT o_orderstatus,count(1) |
因此,优化器会认为订单状态为 P 的订单占用 1⁄3 的数据,使用全表扫描,避免二级索引回表的效率会更高。
然而,由于数据倾斜,订单状态为 P 的数据非常少,根据索引 idx_orderstatus 查询的效率会更高。这种情况下,我们可以利用 MySQL 8.0 的直方图功能,创建一个直方图,让优化器知道数据的分布,从而更好地选择执行计划。直方图的创建命令如下所示:
1 | ANALYZE TABLE orders |
在创建完直方图后,MySQL会收集到字段 o_orderstatus 的数值分布,可以通过下面的命令查询得到:
1 | SELECT |
可以看到,现在 MySQL 知道状态为 P 的订单只占 2.5%,因此再去查询状态为 P 的订单时,就会使用到索引 idx_orderstatus了,如:
1 | EXPLAIN SELECT * FROM orders |
感觉在实际工作中,应用explain和format=tree等命令进行查询命令的优化是非常重要的必修课!
索引应用
引入索引机制后,能够给数据库带来的优势很明显:
- ①整个数据库中,数据表的查询速度直线提升,数据量越大时效果越明显。
- ②通过创建唯一索引,可以确保数据表中的数据唯一性,无需额外建立唯一约束。
- ③在使用分组和排序时,同样可以显著减少
SQL查询的分组和排序的时间。 - ④连表查询时,基于主外键字段上建立索引,可以带来十分明显的性能提升。
- ⑤索引默认是
B+Tree有序结构,基于索引字段做范围查询时,效率会明显提高。 - ⑥从
MySQL整体架构而言,减少了查询SQL的执行时间,提高了数据库整体吞吐量。
感觉索引好处很大啊,对于这点确实毋庸置疑,but at what cost?
建立索引的同时也会带来一系列弊端,如:
- ①建立索引会生成本地磁盘文件,需要额外的空间存储索引数据,磁盘占用率会变高。
- ②写入数据时,需要额外维护索引结构,增、删、改数据时,都需要额外操作索引。
- ③写入数据时维护索引需要额外的时间开销,执行写
SQL时效率会降低,性能会下降。
其实就是说,数据库很小/频繁插入/删除/更新的数据库都是不太适合索引的。当然,但对数据库整体来说,索引带来的优势会大于劣势。不过也正由于索引存在弊端,它不是越多越好,合理建立索引才是最佳选择。
那么怎么样建立合适的索引呢?其实也没有标准,不过有几条经验之谈:
- ①查询
SQL中尽量不要使用OR关键字,可以使用多SQL或子查询代替。 - ②模糊查询尽量不要以
%开头,如果实在要实现这个功能可以建立全文索引。 - ③编写
SQL时一定要注意字段的数据类型,否则MySQL的隐式转换会导致索引失效。 - ④一定不要在编写
SQL时让索引字段执行计算工作,尽量将计算工作放在客户端中完成。 - ⑤对于索引字段尽量不要使用计算类函数,一定要使用时请记得将函数计算放在
=后面。 - ⑥多条件的查询
SQL一定要使用联合索引中的第一个字段,否则会打破最左匹配原则。 - ⑦对于需要对比多个字段的查询业务时,可以拆分为连表查询,使用临时表代替。
- ⑧在
SQL中不要使用反范围性的查询条件,大部分反范围性、不等性查询都会让索引失效。 - ⑨
.......
实际上无非就是根据前面给出的索引失效情况,尽量让自己编写的SQL不会导致索引失效即可,写出来的SQL能走索引查询,那就能在很大程度上提升数据检索的效率。
索引篇,至此结束!
 微信
微信 支付寶
支付寶



