MysqlTutorial01
MySQL数据库基础培训:逻辑架构与InnoDB引擎
1. MySQL基础概念
1.1 什么是MySQL
MySQL是全球最受欢迎的开源关系型数据库管理系统之一,由瑞典MySQL AB公司开发,现在属于Oracle公司。MySQL具有以下特点:
- 开源性:遵循GPL协议,可自由使用和修改
- 跨平台性:支持Windows、Linux、macOS等多种操作系统
- 可靠性:广泛应用于各类网站、应用程序和商业产品
- 性能:针对不同需求可以通过配置进行优化
MySQL广泛应用于网站开发、企业应用、数据仓库等场景,是互联网行业的基础设施之一。
1.2 MySQL的逻辑架构
根据图中所示,MySQL服务器采用了分层的逻辑架构,主要由以下三层组成:
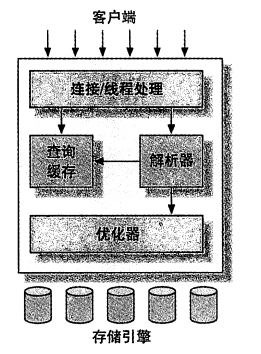
第一层:连接层
位于最顶部,负责处理客户端连接请求。这一层的功能包括:连接处理、线程管理、用户认证、安全等等。
这一层并不是MySQL独有的,而是大多数基于网络的服务器都具有类似架构。
第二层:服务层
这是MySQL的核心层,负责大部分的核心服务功能,包括:
- 查询解析:将SQL语句解析成内部数据结构
- 查询分析:分析语句的语法和语义
- 查询优化:生成最优的执行计划
- 查询执行:按照执行计划执行查询
- 缓存管理:管理查询缓存
- 内置函数:处理内置函数(如日期、时间、数学和加密函数)
在这一层实现了所有与存储引擎无关的功能,存储过程、触发器、视图都是在这一层实现的。
第三层:存储引擎层
第三层包含了存储引擎。存储引擎负责 MySQL中数据的存储和提取。和GNU/Linux下的各种文件系统一样,每个存储引擎都有它的优势和劣势。服务器通过API与存储引擎进行通信。这些接口屏蔽了不同存储引擎之间的差异,使得这些差异对上层的查询过程透明。存储引擎 API包含几十个底层函数,用于执行诸如“开始一个事务”或者“根据主键提取一行记录”等操作。但存储引擎不会去解析SQL生,不同存储引擎之间也不会相互通信,而只是简单地响应上层服务器的请求。
2. SQL查询执行过程

当我们执行一条SQL语句时,MySQL内部会经历以下过程:
1. 连接器(Connection)
- 与客户端进行 TCP 三次握手建立连接;
- 校验客户端的用户名和密码,如果用户名或密码不对,则会报错;
- 如果用户名和密码都对了,会读取该用户的权限,然后后面的权限逻辑判断都基于此时读取到的权限。
使用的代码:
1 | mysql -h主机名 -u用户名 -p密码 |
四个问题:
1.如何查看mysql被多少个客户端连接?——使用show processlist进行查看
2.空闲连接会一直占用嘛?——MySQL定义了空闲连接的最大空闲时长,由wait_timeout参数控制的,默认值是8小时(28880秒),如果空闲连接超过了这个时间,连接器就会自动将它断开。当然,我们自己也可以手动断开空闲的连接,使用的是 kill connection +id 的命令。
3.mysql连接数有限制吗?——有的兄弟,最大连接数由max_connections控制,超过该数则会报错。
4.怎么解决长连接占用内存的问题?——定期断开长连接释放内存,或者在客户端主动重置连接。MySQL5.7版本实现了mysql_reset_connection() 函数的接口,注意这是接口函数不是命令,那么当客户端执行了一个很大的操作后,在代码里调用 mysql_reset_connection 函数来重置连接,达到释放内存的效果。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
2. 查询缓存(Query Cache)
- 命中查询缓存,则返回
- 没有命中,则将查询结果放入缓存中
- 在频繁更新的表中不适用
连接器得工作完成后,客户端就可以向 MySQL 服务发送 SQL语句了,MySQL 服务收到 SQL 语句后,就会解析出 SQL语句的第一个字段,看看是什么类型的语句。
如果 SQL 是查询语句(select 语句),MySQL 就会先去査询缓存(Query Cache)里查找缓存数据,看看之前有没有执行过这一条命令,这个查询缓存是以 key-value 形式保存在内存中的,key 为 SQL 查询语句,value 为 SQL语句查询的结果。
如果查询的语句命中查询缓存,那么就会直接返回 value 给客户端。如果查询的语句没有命中查询缓存中,那么就要往下继续执行,等执行完后,查询的结果就会被存入查询缓存中。
这么看,查询缓存还挺有用,但是其实查询缓存挺鸡肋的。
对于更新比较频繁的表,查询缓存的命中率很低的,因为只要一个表有更新操作,那么这个表的查询缓存就会被清空。如果刚缓存了一个查询结果很大的数据,还没被使用的时候,刚好这个表有更新操作,香询缓冲就被清空了,相当于缓存了个寂寞。
所以,MySQL8.0 版本直接将查询缓存删掉了,也就是说 MySQL8.0 开始,执行一条 SQL 查询语句,不会再走到查询缓存这个阶段了,
对于 MySQL 8.0 之前的版本,如果想关闭査询缓存,我们可以通过将参数 query_cache_type 设置成DEMAND。
3. 解析器(Parser)
- 词法分析:将SQL语句分解成词元
- 语法分析:检查SQL语法是否正确
- 生成解析树
- 主要功能就是检查sql语句的语法
在正式执行 SQL 查询语句之前, MySQL 会先对 SQL 语句做解析,这个工作交由「解析器」来完成。
解析器会做如下两件事情。
第一件事情,词法分析。MySQL 会根据你输入的字符串识别出关键字出来,例如,SQL语句 selectusername from userinfo,在分析之后,会得到4个Token,其中有2个Keyword,分别为select和from:
| 关键字 | 非关键字 | 关键字 | 非关键字 |
|---|---|---|---|
| select | username | from | userinfo |
第二件事情,语法分析。根据词法分析的结果,语法解析器会根据语法规则,判断你输入的这个SQL语句是否满足 MySQL 语法,如果没问题就会构建出 SQL语法树,这样方便后面模块获取 SQL 类型、表名、字段名、 where 条件等等。

如果我们输入的 SQL语句语法不对,就会在解析器这个阶段报错。比如把 from写成了 form,这时 MySQL 解析器就会给报错。
4. 预处理器(Preprocessor)
- 进一步检查解析树
- 检查表和列是否存在
- 将表名和列名补全
我们先来说说预处理阶段做了什么事情。
- 检査 SQL 查询语句中的表或者字段是否存在;
- 将 select*中的 *符号,扩展为表上的所有列;
下面这条查询语句,test 这张表是不存在的,这时 MySQL 就会在执行 SQL 查询语句的 prepare 阶段中报错。
1 | mysql> select * from test. |
这里贴个 MySQL 8.0 源码来证明表或字段是否存在的判断,不是在解析器里做的,而是在 prepare 阶段。

5. 优化器(Optimizer)
- 决定使用哪个索引
- 决定表的连接顺序
- 生成执行计划
经过预处理阶段后,还需要为 SQL查询语句先制定一个执行计划,这个工作交由「优化器」来完成的。优化器主要负责将 SQL 查询语句的执行方案确定下来,比如在表里面有多个索引的时候,优化器会基于查询成本的考虑,来决定选择使用哪个索引。
当然,我们本次的査询语句(select* from product where id = 1)很简单,就是选择使用主键索引。
要想知道优化器选择了哪个索引,我们可以在査询语句最前面加个 explain 命令,这样就会输出这条SQL语句的执行计划,然后执行计划中的 key 就表示执行过程中使用了哪个索引,比如 key 为 PRIMARY 就是使用了主键索引。如果查询语句的执行计划里的 key 为 null 说明没有使用索引,那就会全表扫描(type=ALL),这种查询扫描的方式是效率最低档次的,如下图:
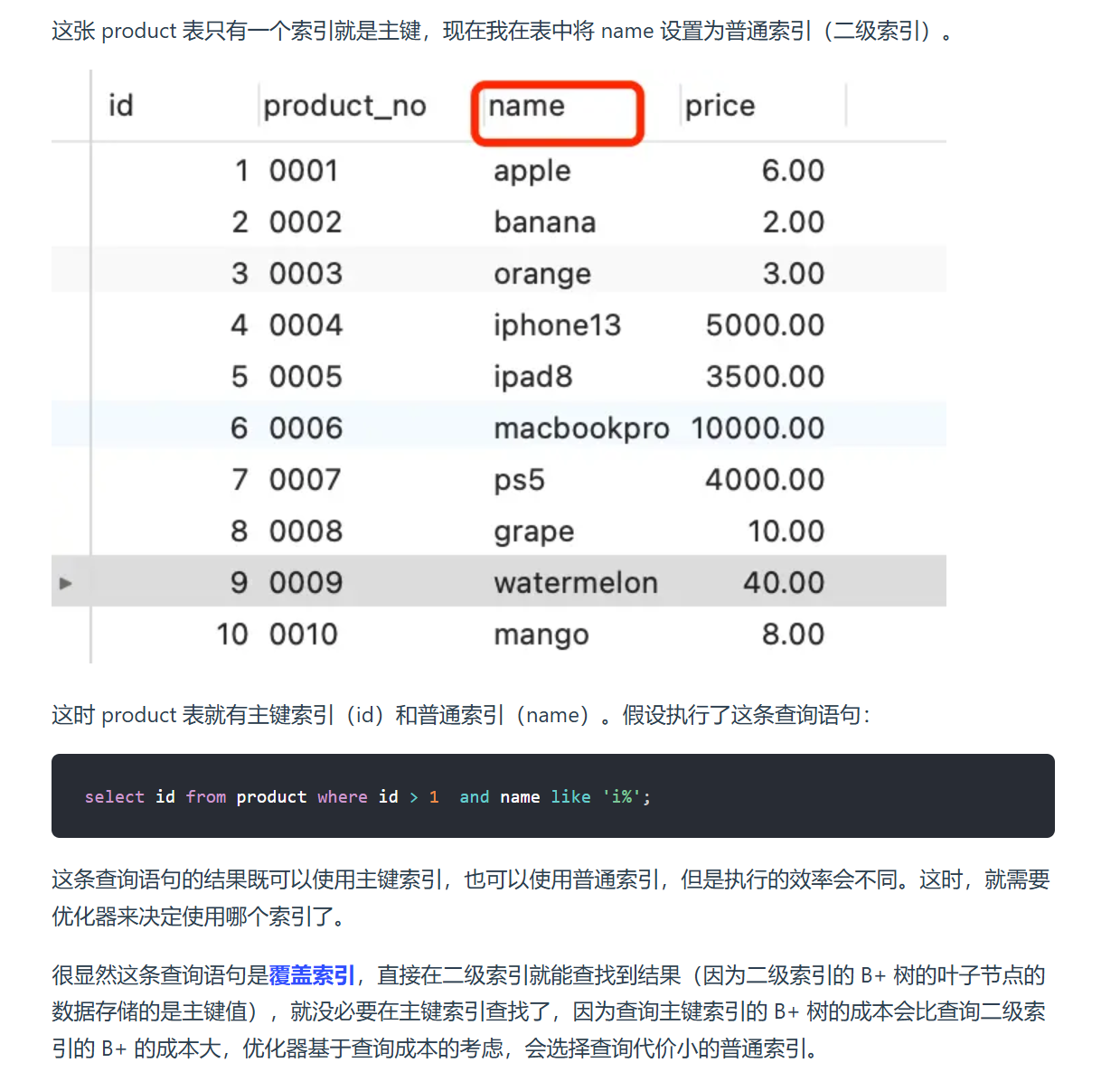
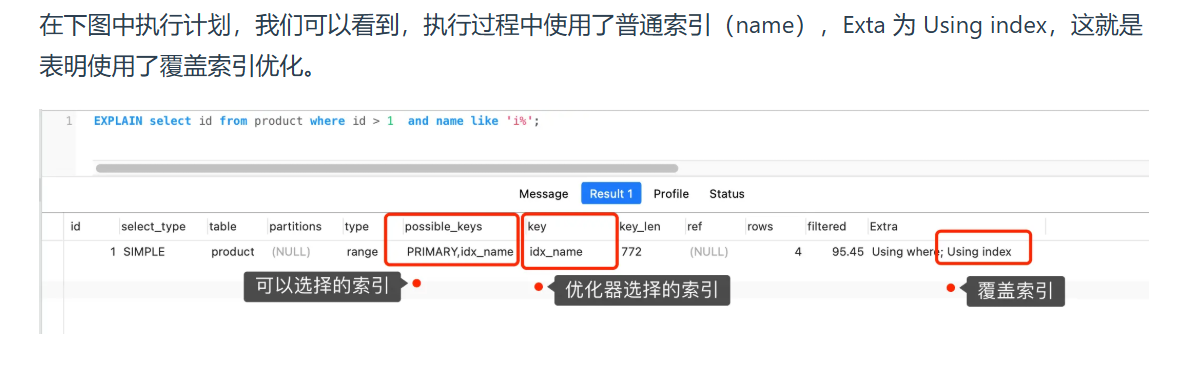
除此之外,优化器还有权力执行覆盖索引的优化。下面截图自小林coding网站:
6. 执行器(Executor)
- 主键索引查询
对于语句select * from product where id = 1:
执行器第一次查询,会调用 read_first_record 函数指针指向的函数,因为优化器选择的访问类型为const,这个函数指针被指向InnoDb 引擎索引査询的接口,把条件 id=1 交给存储引擎,让存储引擎定位符合条件的第一条记录。
存储引擎通过主键索引的 B+ 树结构定位到 id =1的第一条记录,如果记录是不存在的,就会向执行器上报记录找不到的错误,然后查询结束。如果记录是存在的,就会将记录返回给执行器;
执行器从存储引擎读到记录后,接着判断记录是否符合查询条件,如果符合则发送给客户端,如果不符合则跳过该记录。
执行器查询的过程是一个 while 循环,所以还会再査一次,但是这次因为不是第一次查询了,所以会调用 read_record 函数指针指向的函数,因为优化器选择的访问类型为 const,这个函数指针被指向为一个永远返回-1的函数,所以当调用该函数的时候,执行器就退出循环,也就是结束查询了。
至此,这个语句就执行完成了。
- 全表扫描
对于语句select * from product where name = 'iphone':
这条查询语句的查询条件没有用到索引,所以优化器决定选用访问类型为 ALL 进行查询,也就是全表扫描的方式查询,那么这时执行器与存储引擎的执行流程是这样的:
执行器第一次查询,会调用 read_first_record 函数指针指向的函数,因为优化器选择的访问类型为all,这个函数指针被指向为 InnoDB 引擎全扫描的接口,让存储引擎读取表中的第一条记录;·执行器会判断读到的这条记录的 name 是不是iphone,如果不是则跳过;如果是则将记录发给客户的。
执行器查询的过程是一个 while 循环,所以还会再査一次,会调用 read_record 函数指针指向的函数,.因为优化器选择的访问类型为 all,read_record 函数指针指向的还是 InnoDB 引擎全扫描的接口,所以接着向存储引擎层要求继续读刚才那条记录的下一条记录,存储引擎把下一条记录取出后就将其返回给执行器(Server层),执行器继续判断条件,不符合查询条件即跳过该记录,否则发送到客户端;
一直重复上述过程,直到存储引擎把表中的所有记录读完,然后向执行器(Server层)返回了读取完毕的信息;
执行器收到存储引擎报告的查询完毕的信息,退出循环,停止查询。
至此,这个语句就执行完成了。
- 索引下推
索引下推能够减少二级索引在查询时的回表操作,提高查询的效率,因为它将 Server 层部分负责的事情,交给存储引擎层去处理了。
举一个具体的例子,方便大家理解,这里一张用户表如下,我对 age 和 reward 字段建立了联合索引(age,reward):
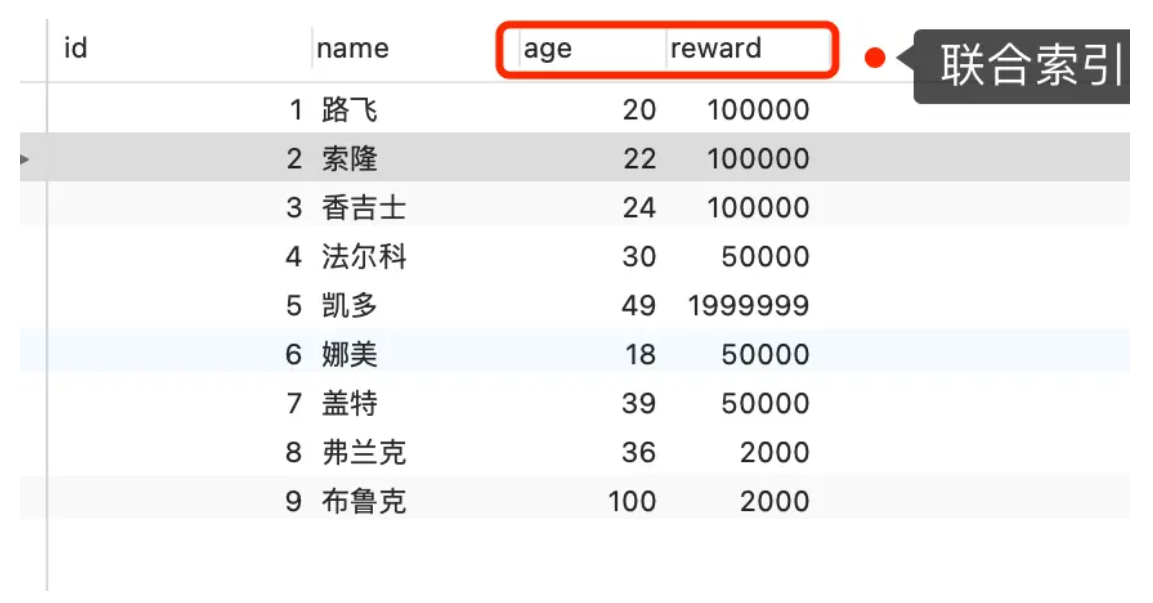
现在有下面这条查询语句:
1 | select * from t_user where age > 20 and reward = 10000; |

区分读取第一条记录和后续记录主要有以下几个原因:
- 初始化与迭代的区别
read_first_record不仅仅是读取记录,它还负责初始化整个扫描过程。它会设置必要的扫描上下文、初始化缓冲区、准备扫描参数,并将游标定位到表的起始位置。而read_record只负责移动游标并获取下一条记录。- 内部状态管理
获取第一条记录时需要建立扫描环境,而后续记录可以复用这个已建立的环境。这是一种常见的编程模式,类似于迭代器模式中的初始化与迭代分离。- 特殊情况处理
某些查询优化可能只对第一条记录有效。例如,当使用LIMIT 1或某些可以提前终止的查询时,只需处理第一条记录的逻辑。简而言之,这种区分反映了初始化操作和迭代操作的本质区别,尽管从外部看起来它们都是在读取记录并检查条件。这种设计既符合软件工程的最佳实践,也为各种优化提供了可能性。
3. MySQL存储引擎
3.1 存储引擎概述
存储引擎是MySQL的核心组件,负责数据的存储和提取。MySQL的存储引擎采用了可插拔的设计,允许在不同的表上使用不同的存储引擎。
在文件系统中,MySQL将每个数据库(也可以称之为schema)保存为数据目录下的一个子目录。创建表时,MySQL会在数据库子目录下创建一个和表同名的./rm文件保存表的定义。例如创建一个名为MyTable的表,MYSQL会在 Mytable.fm 文件中保存该表的定义。因为 MySQL使用文件系统的目录和文件来保存数据库和表的定义,大小写敏感性和具体的平台密切相关。在Windows中,大小写是不敏感的;而在类 Unix中则是敏感的。不同的存储引擎保存数据和索引的方式是不同的,但表的定义则是在MySQL服务层统一处理的。
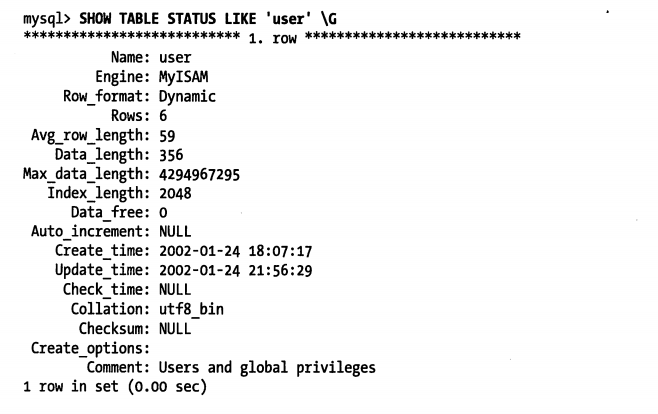
可以使用SHOW TABLE STATUS命令(在MySQL5.0以后的版本中,也可以查询INFORMATION_SCHEMA中对应的表)显示表的相关信息。例如,对于mysql数据库中的user表:
查看支持的存储引擎:
1 | SHOW ENGINES; |
查看表的存储引擎:
1 | SHOW TABLE STATUS FROM database_name WHERE name = 'table_name'; |
创建表时指定存储引擎:
1 | CREATE TABLE table_name ( |
修改表的存储引擎:
1 | ALTER TABLE table_name ENGINE = engine_name; |
3.2 主要存储引擎对比
MySQL 常见的存储引擎有 InnoDB、MyISAM、Memory。
我比较熟悉的是 InnoDB 引擎,它是 MySQL 默认的存储引擎,支持事务和行级锁,具有事务提交、回滚和崩溃恢复功能。
MYISAM 引擎我没有用过,但是我在学习的时候有了解过,它是不支持事务和行级锁的,而且由于只支持表锁,锁的粒度比较大,更新性能比较差,我认为它比较适合读多写少的场景。
Memory 引擎我了解不多,大概知道它是将数据存储在内存中,所以数据的读写还是比较快的,但是数据不具备持久性,我觉得适用于临时存储数据的场景。
memory 存储引起只支持 sql,没有 Redis 那么丰富的数据结构。
3.3 为什么MySQL默认选择InnoDB
InnoDB引擎在事务支持、并发性能、崩溃恢复等方面具有优势,因此被MySQL选择为默认的存储引擎。
- 事务支持:InnoDB引擎提供了对事务的支持,可以进行ACID(原子性、一致性、隔离性、持久性)属性的操作。Myisam存储引擎是不支持事务的。
- 并发性能:InnoDB引擎采用了行级锁定的机制,可以提供更好的并发性能,Myisam存储引擎只支持表锁,锁的粒度比较大。
- 崩溃恢复:InnoDB引引擎通过 redol0g 日志实现了崩溃恢复,可以在数据库发生异常情况(如断电)时,通过日志文件进行恢复,保证数据的持久性和一致性。Myisam是不支持崩溃恢复的。
4. InnoDB特性研究
InnoDB如何存储数据(宏观)
数据页是存储引擎读写的最小单位,默认大小为16KB。数据页的默认结构如下:
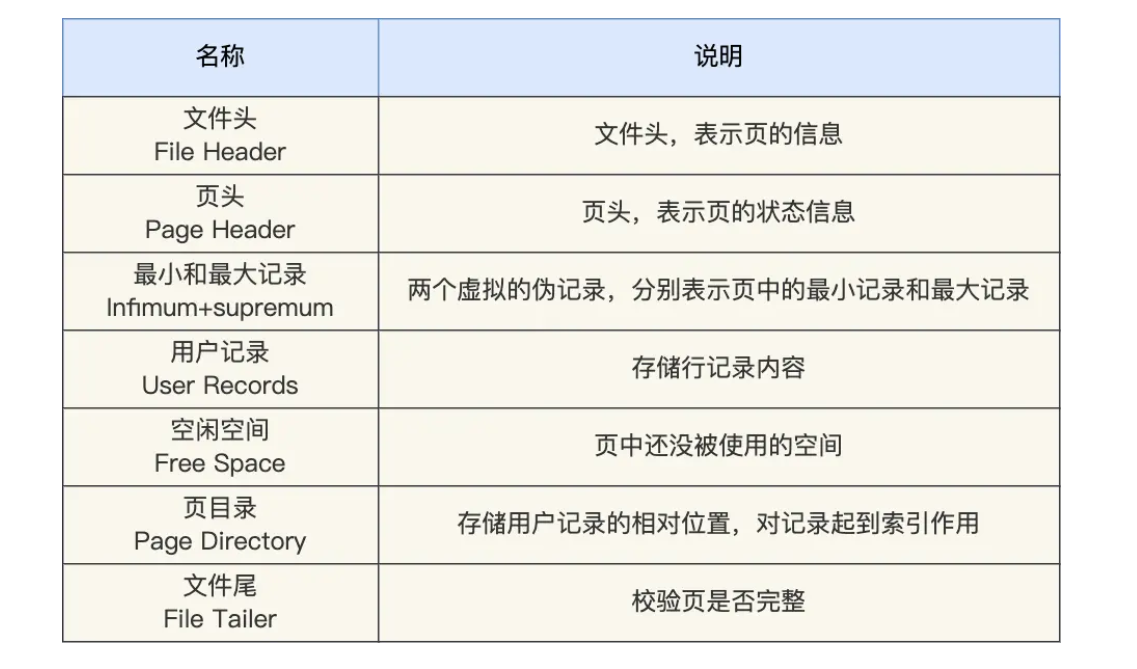
每个数据页由双向链表互相指向文件头以相互连接:
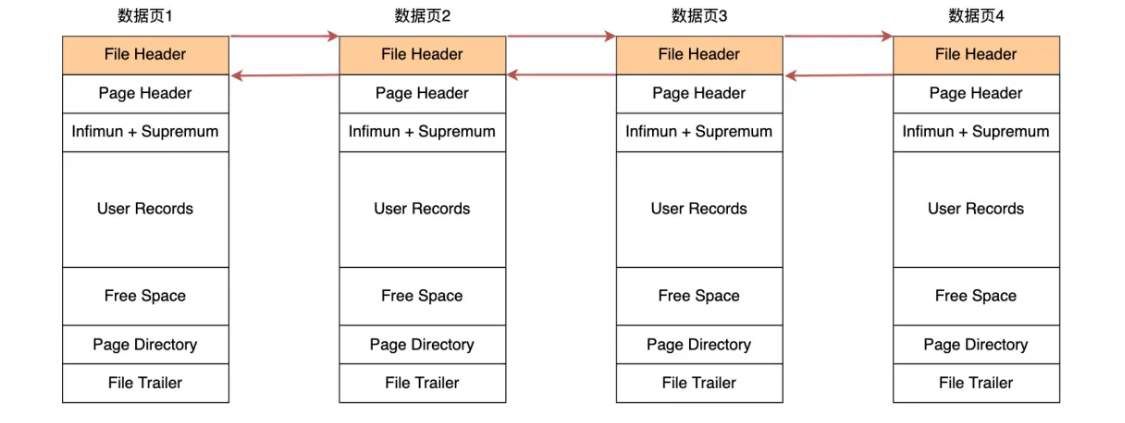
对于单页来说:
数据页中的记录按照「主键」顺序组成单向链表,单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。
因此,数据页中有一个页目录,起到记录的索引作用,就像我们书那样,针对书中内容的每个章节设立了一个目录,想看某个章节的时候,可以查看目录,快速找到对应的章节的页数,而数据页中的页目录就是为了能快速找到记录。
单页数据结构如下:
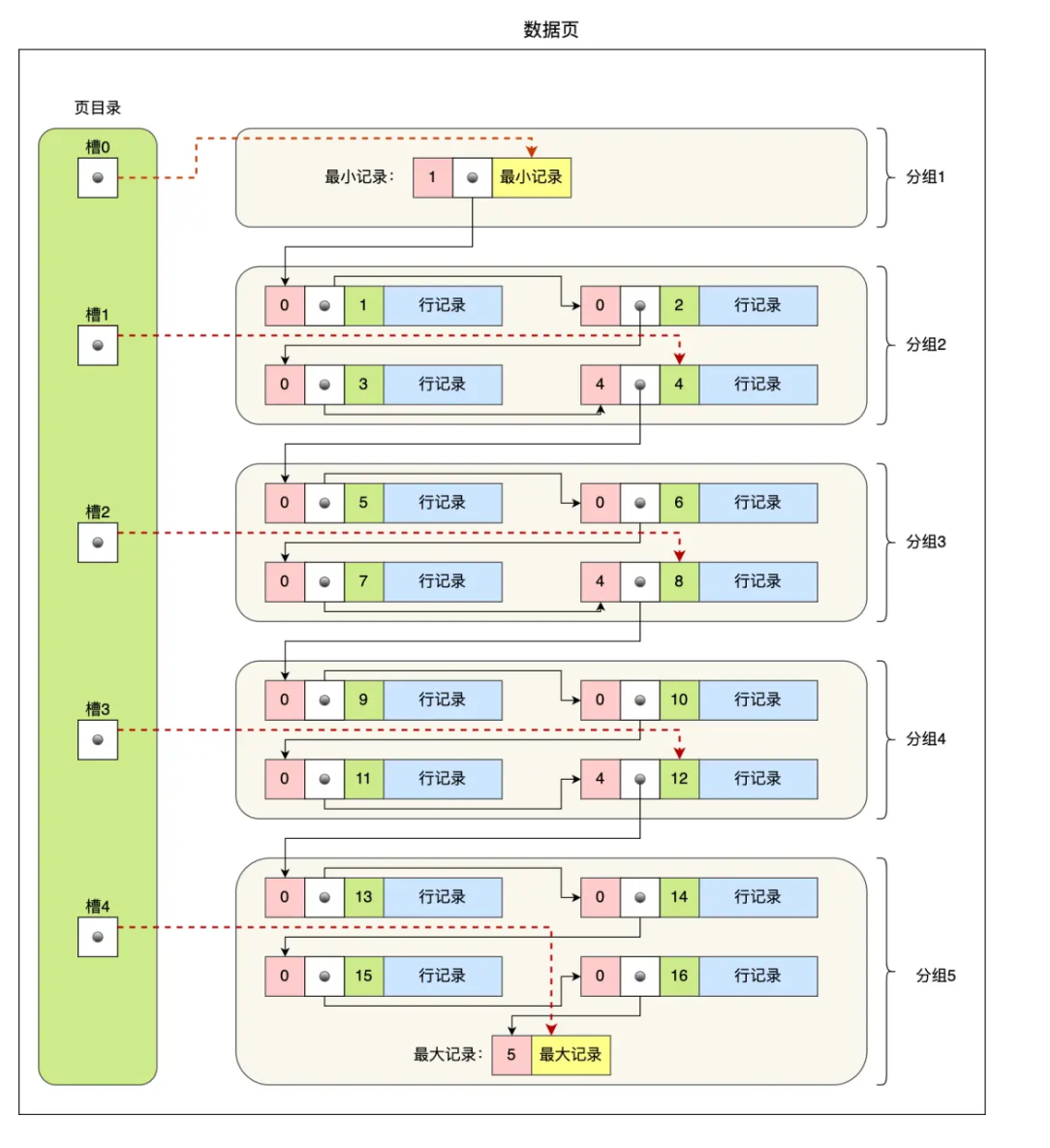
查找时,槽指针指向了不同组中的最后一个记录,页目录的槽相当于分组记录的索引。通过二分法先确定槽,再在组内的单项链表遍历。
在有多个数据页时,InnoDB采用B+树作为索引:
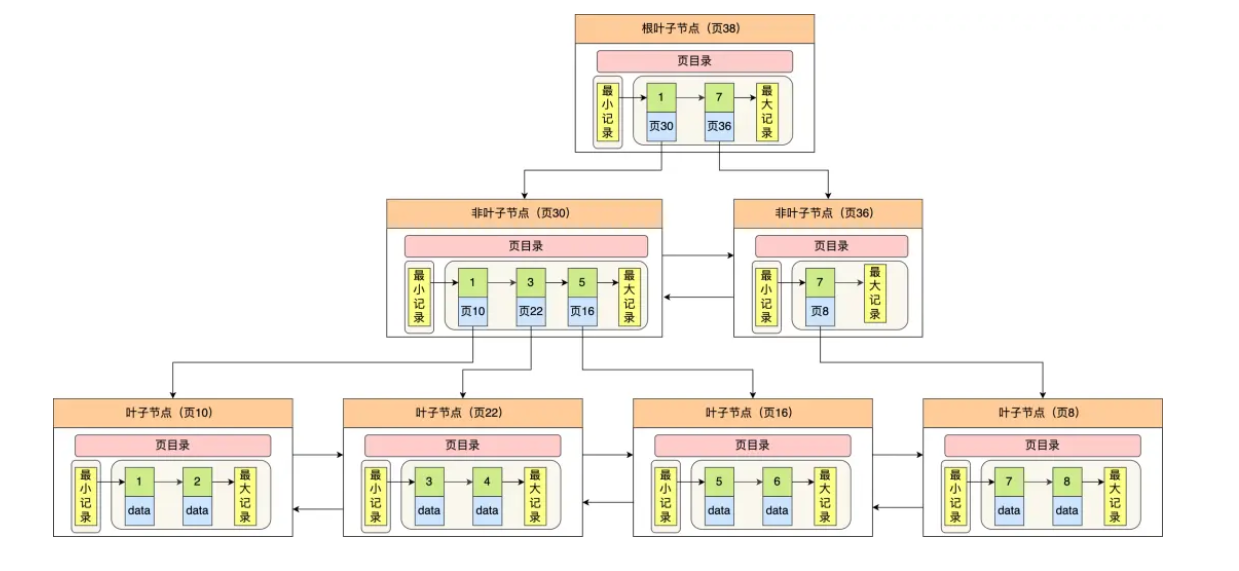
非叶子节点仅存放目录项作为索引,叶子节点存储数据。
例如实现快速查找主键为6的记录,以上图为例子:
从根节点开始,通过二分法快速定位到符合页内范围包含查询值的页,因为查询的主键值为 6,在[1,7)范围之间,所以到页 30 中查找更详细的目录项;
在非叶子节点(页30)中,继续通过二分法快速定位到符合页内范围包含查询值的页,主键值大于 5所以就到叶子节点(页16)查找记录;
接着,在叶子节点(页16)中,通过槽查找记录时,使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到主键为6的记录。
当有二级索引时,会以二级索引为核心构建第二个B+树,此时需要回表操作。当然,如果是通过二级索引查找主键或聚簇索引,回表操作就不用了,这里就是索引覆盖的含义。
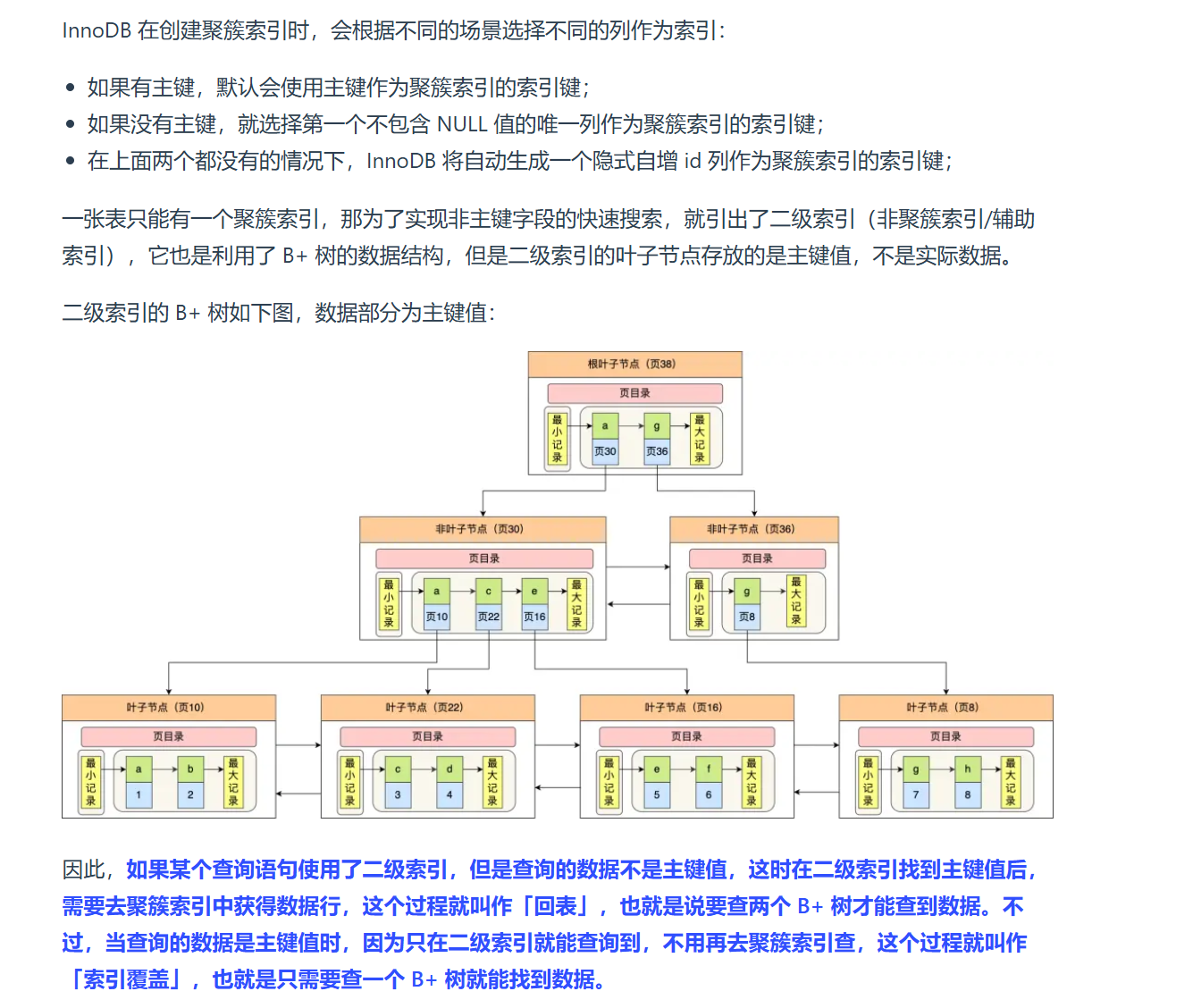
缓冲池Buffer Pool
虽然说 MySQL的数据是存储在磁盘里的,但是也不能每次都从磁盘里面读取数据,这样性能是极差的要想提升查询性能,加个缓存就行了嘛。所以,当数据从磁盘中取出后,缓存内存中,下次查询同样的数据的时候,直接从内存中读取。
为此,Innodb 存储引擎设计了一个缓冲池(Buffer Pool)来提高数据库的读写性能。
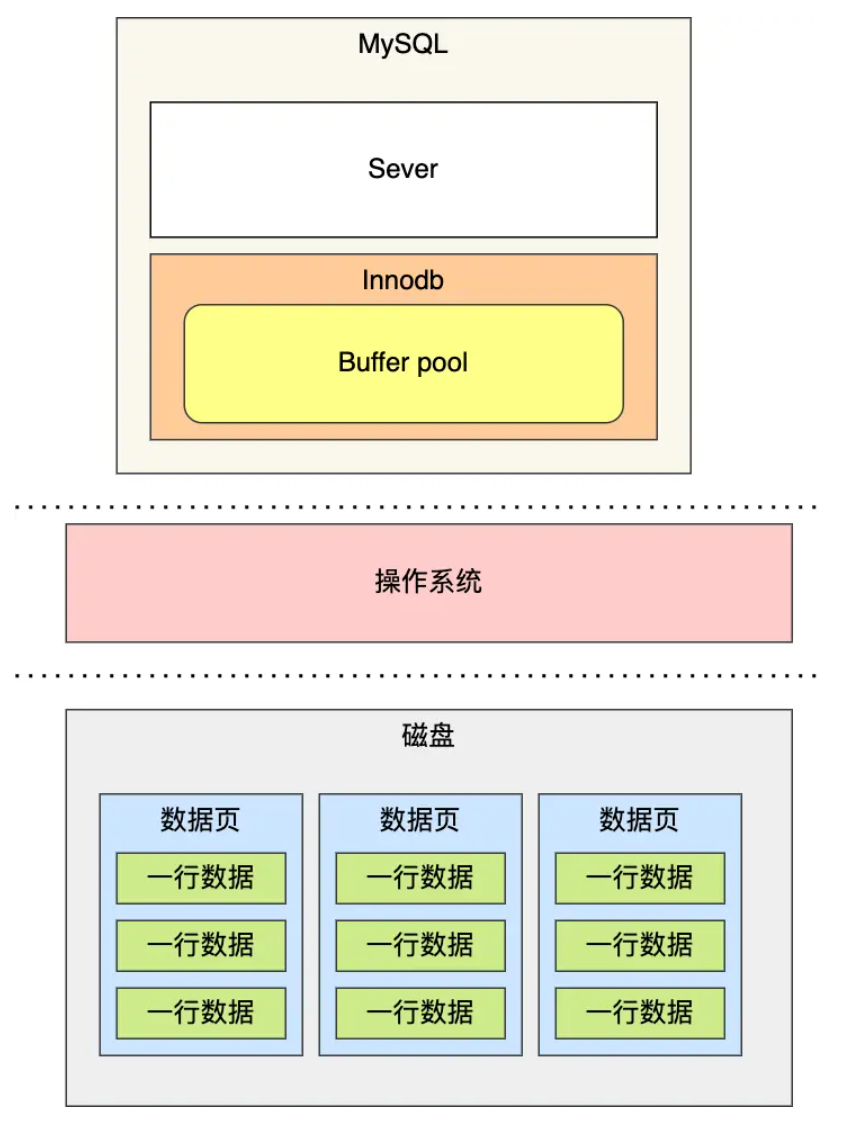
Buffer Pool 是在 MySQL 启动的时候,向操作系统申请的一片连续的内存空间,默认配置下 Buffer Pool只有128MB。
可以通过调整:innodb_buffer_pool_size参数来设置 Buffer Pool 的大小,一般建议设置成可用物理内存的 60%~80%。
Buffer Pool中的缓存数据同样按照页划分,在启动时,这些缓存页都是空闲的,之后随着程序运行才会有磁盘上的页被缓存到Pool中。
所以,MySQL刚启动的时候,你会观察到使用的虚拟内存空间很大,而使用到的物理内存空间却很小,这是因为只有这些虚拟内存被访问后,操作系统才会触发缺页中断,接着将虚拟地址和物理地址建立映射关系。
Buffer Poo 除了缓存「索引页」和「数据页」,还包括了 undo 页,插入缓存、自适应哈希索引、锁信息等等。
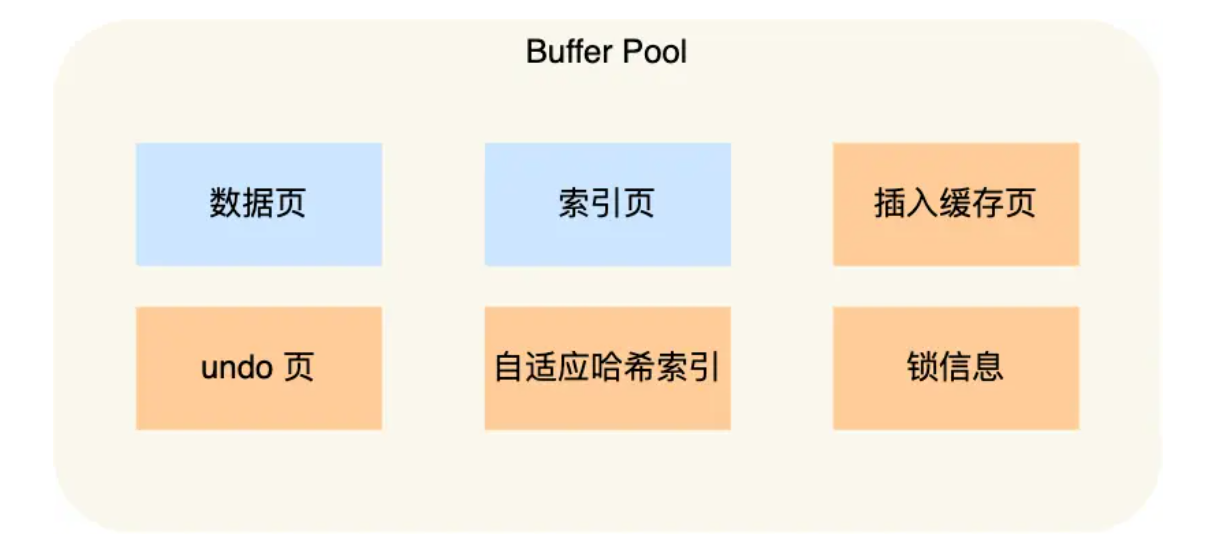
为了更好的管理这些在 Buffer Pool 中的缓存页,InnoDB 为每一个缓存页都创建了一个控制块,控制块信息包括「缓存页的表空间、页号、缓存页地址、链表节点」等等。
控制块也是占有内存空间的,它是放在 Buffer Pool的最前面,接着才是缓存页,如下图:
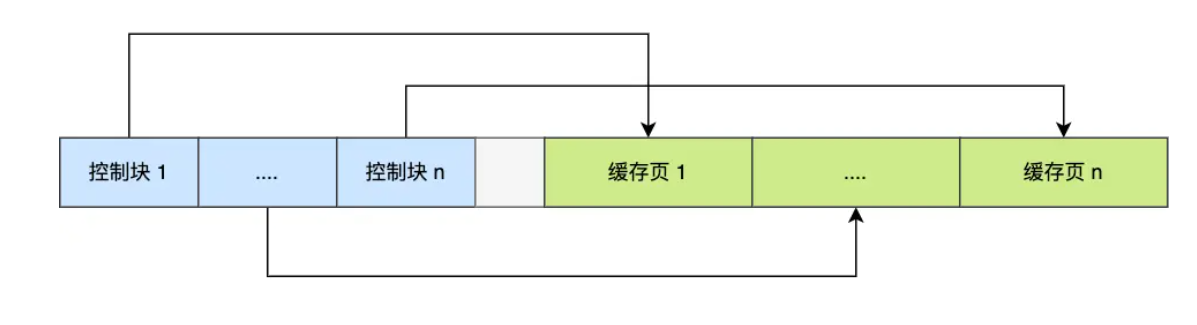
对于剩余的不够分配一对控制块+缓存页的空间称之为碎片空间。此时如果要查询一条记录,InnoDB仍然会把一整个页加载到Pool中,因为索引只能定位到磁盘中的页,而定位不到记录。
Buffer Pool里有三种页和链表来管理数据:
- 干净页、脏页、空闲页
- Free链表,LRU链表、Flush链表
**Free Page(空闲页)**:表示此页未被使用,位于 Free 链表;
**Clean Page(干净页)**:表示此页已被使用,但是页面未发生修改,位于LRU链表。
**Dirty Page(脏页)**:表示此页「已被使用」且「已经被修改」,其数据和磁盘上的数据已经不一致。当脏页上的数据写入磁盘后,内存数据和磁盘数据一致,那么该页就变成了干净页。脏页同时存在于LRU 链表和 Flush 链表。
Free链表:
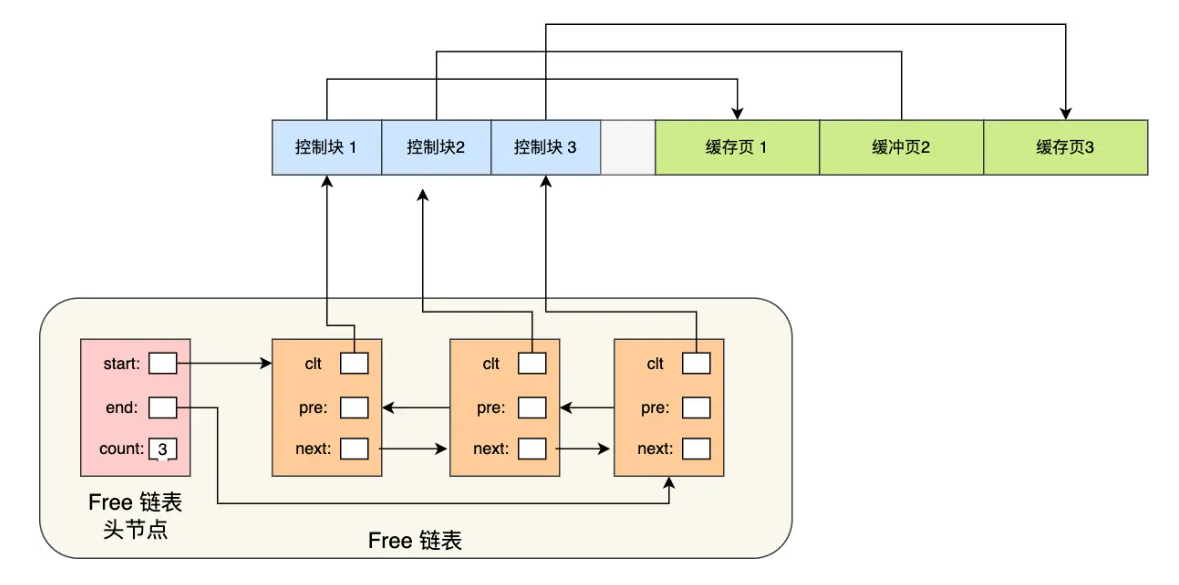
为了能够快速找到空闲的缓存页,可以使用链表结构,将空闲缓存页的「控制块」作为链表的节点,这个链表称为 Free 链表(空闲链表)。Free链表的头结点还记录了头尾结点的地址和空闲页的数量。有了 Free 链表后,每当需要从磁盘中加载一个页到 Buffer Pool中时,就从 Free链表中取一个空闲的缓存页,并且把该缓存页对应的控制块的信息填上,然后把该缓存页对应的控制块从 Free 链表中移除。
Flush链表:
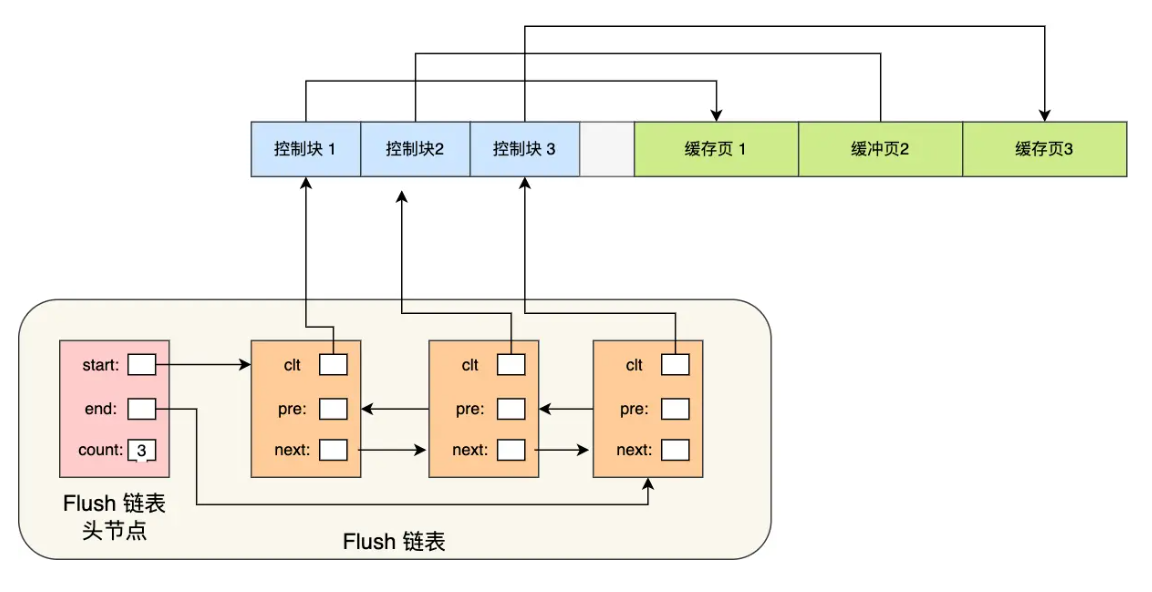
设计 Buffer Pool 除了能提高读性能,还能提高写性能,也就是更新数据的时候,不需要每次都要写入磁盘,而是将 Buffer Pool 对应的缓存页标记为脏页,然后再由后台线程将脏页写入到磁盘。
那为了能快速知道哪些缓存页是脏的,于是就设计出 Flush 链表,它跟 Free 链表类似的,链表的节点也是控制块,区别在于 Flush 链表的元素都是脏页。
LRU链表:
为了提高缓存命中率,故设计LRU(Least Recently Used)链表。原理很简单,将最新使用的页放到head指针,对尾部页实行末尾淘汰制。
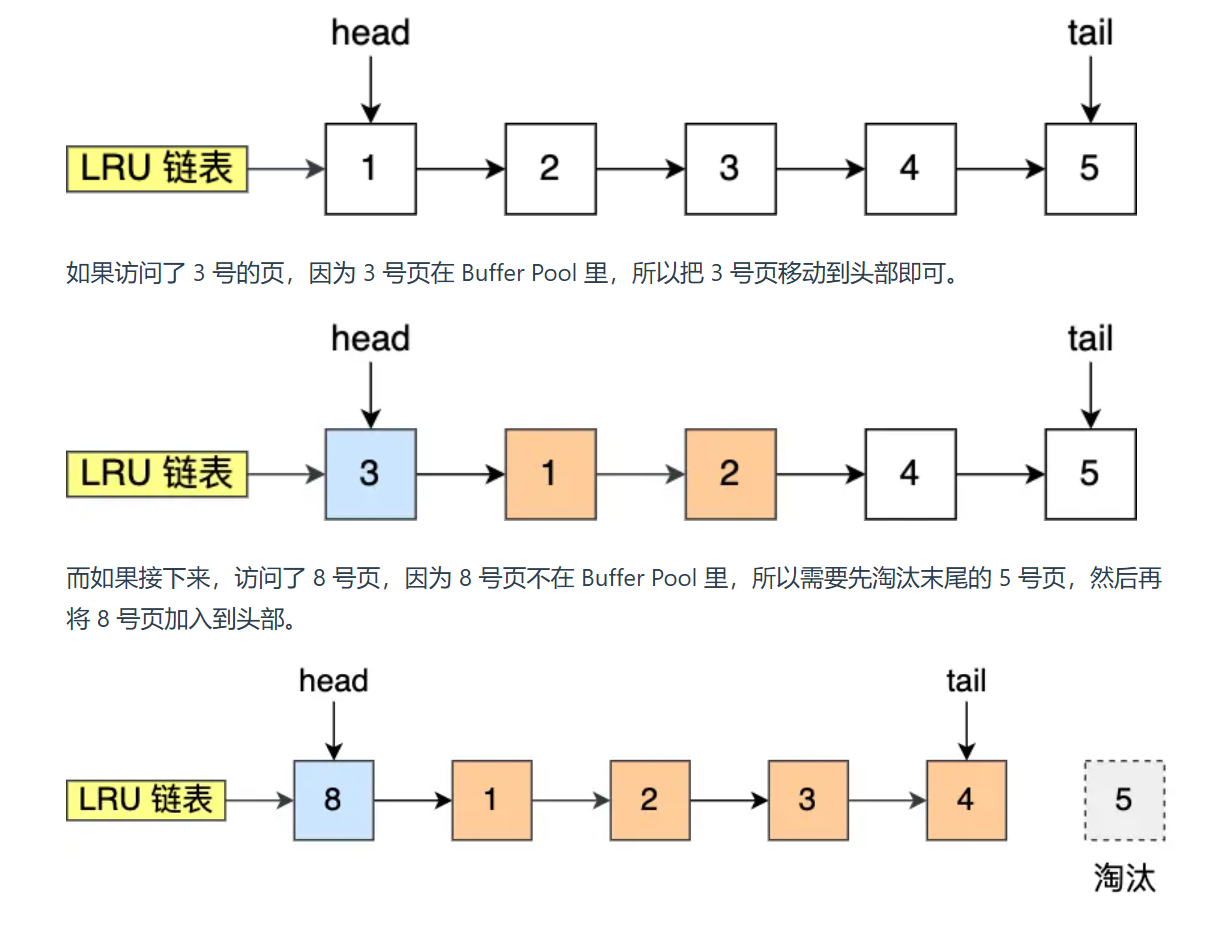
然而还需要解决预读失效和Buffer Pool污染的问题。
什么是预读失效?
先来说说 MySQL 的预读机制。程序是有空间局部性的,靠近当前被访问数据的数据,在未来很大概率会被访问到。
所以,MSQL在加载数据页时,会提前把它相邻的数据页一并加载进来,目的是为了减少磁盘 IO。但是可能这些被提前加载进来的数据页,并没有被访问,相当于这个预读是白做了,这个就是预读失效。
如果使用简单的 LRU 算法,就会把预读页放到 LRU 链表头部,而当 Buffer Pool空间不够的时候,还需要把未尾的页淘汰掉。
如果这些预读页如果一直不会被访问到,就会出现一个很奇怪的问题,不会被访问的预读页却占用了 LRU链表前排的位置,而未尾淘汰的页,可能是频繁访问的页,这样就大大降低了缓存命中率。
为解决预读失效导致的缓存命中率降低问题,将LRU链表重构成young和old区域,默认比例是63:37.此时,预读的页只会放入old链表头部,等到真正读到之后才会放入young区。
举个例子:
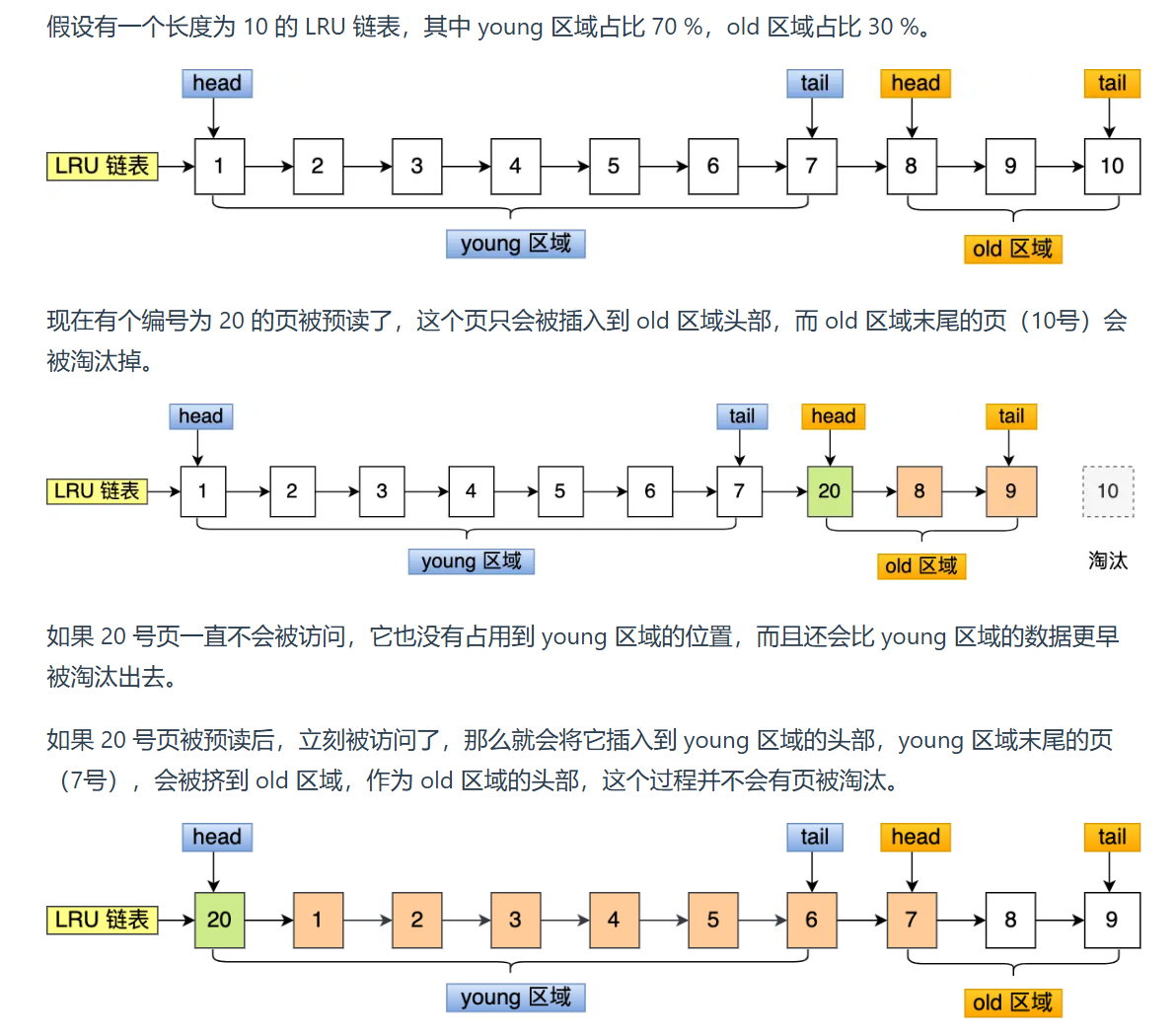
什么是Buffer Pool 污染?
当某一个 SQL语句扫描了大量的数据时,在 Buffer Pool 空间比较有限的情况下,可能会将 Buffer Pool里的所有页都替换出去,导致大量热数据被淘汰了,等这些热数据又被再次访问的时候,由于缓存未命中,就会产生大量的磁盘 IO,MySQL性能就会急剧下降,这个过程被称为 Buffer Pool 污染。
注意, Buffer Pool 污染并不只是査询语句査询出了大量的数据才出现的问题,即使查询出来的结果集很小,也会造成 Buffer Pool 污染。
LRU 链表中 young 区域就是热点数据,只要我们提高进入到 young 区域的门槛,就能有效地保证 young区域里的热点数据不会被替换掉。
MySQL 是这样做的,进入到 young 区域条件增加了一个停留在 old 区域的时间判断。具体是这样做的,在对某个处在 od 区域的缓存页进行第一次访问时,就在它对应的控制块中记录下来这个访问时间:
- 如果后续的访问时间与第一次访问的时间在某个时间间隔内,那么该缓存页就不会被从 old 区域移动到young 区域的头部;
- 如果后续的访问时间与第一次访问的时间不在某个时间间隔内,那么该缓存页移动到 young 区域的头部;
- 这个间隔时间是由 innodb_old_blocks_time 控制的,默认是 1000 ms。
也就说,只有同时满足「被访问」与「在 old 区域停留时间超过1秒」两个条件,才会被插入到 young区域头部,这样就解决了 Buffer Pool 污染的问题。
另外,MySQL 针对 young 区域其实做了一个优化,为了防止 young 区域节点频繁移动到头部。young 区域前面 1/4 被访问不会移动到链表头部,只有后面的 3/4被访问了才会。
脏页刷新
下面几种情况会触发脏页的刷新:
- 当 redo log 日志满了的情况下,会主动触发脏页刷新到磁盘;
- Buffer Pool空间不足时,需要将一部分数据页淘汰掉,如果淘汰的是脏页,需要先将脏页同步到磁盘;
- MySQL认为空闲时,后台线程会定期将适量的脏页刷入到磁盘;
- MySQL正常关闭之前,会把所有的脏页刷入到磁盘。
Change Buffer
Change Buffer 是 Buffer Pool 的一部分,专门用于缓存对二级索引的修改:
- 主要功能:缓存对非唯一二级索引页的修改操作(插入、删除、更新)
- 适用条件:仅适用于二级索引,且该索引页不在 Buffer Pool 中
- 优化目标:将随机 I/O 转换为顺序 I/O,提高写入性能
与Buffer Pool的关系:
包含关系:Change Buffer 物理上是 Buffer Pool 的一部分,占用 Buffer Pool 的空间
协同工作:
- 当修改二级索引时,如果索引页不在 Buffer Pool 中,修改会被记录在 Change Buffer 中
- 当索引页被加载到 Buffer Pool 时,相关的 Change Buffer 记录会被合并到实际的索引页
持久化:Change Buffer 的内容同时也会被写入系统表空间,在实例重启后仍然有效
参数控制:可以通过 innodb_change_buffer_max_size 参数控制 Change Buffer 占用 Buffer Pool 的比例。在写密集型的数据库中,这个比例越大越好。
5. InnoDB与MyISAM的对比
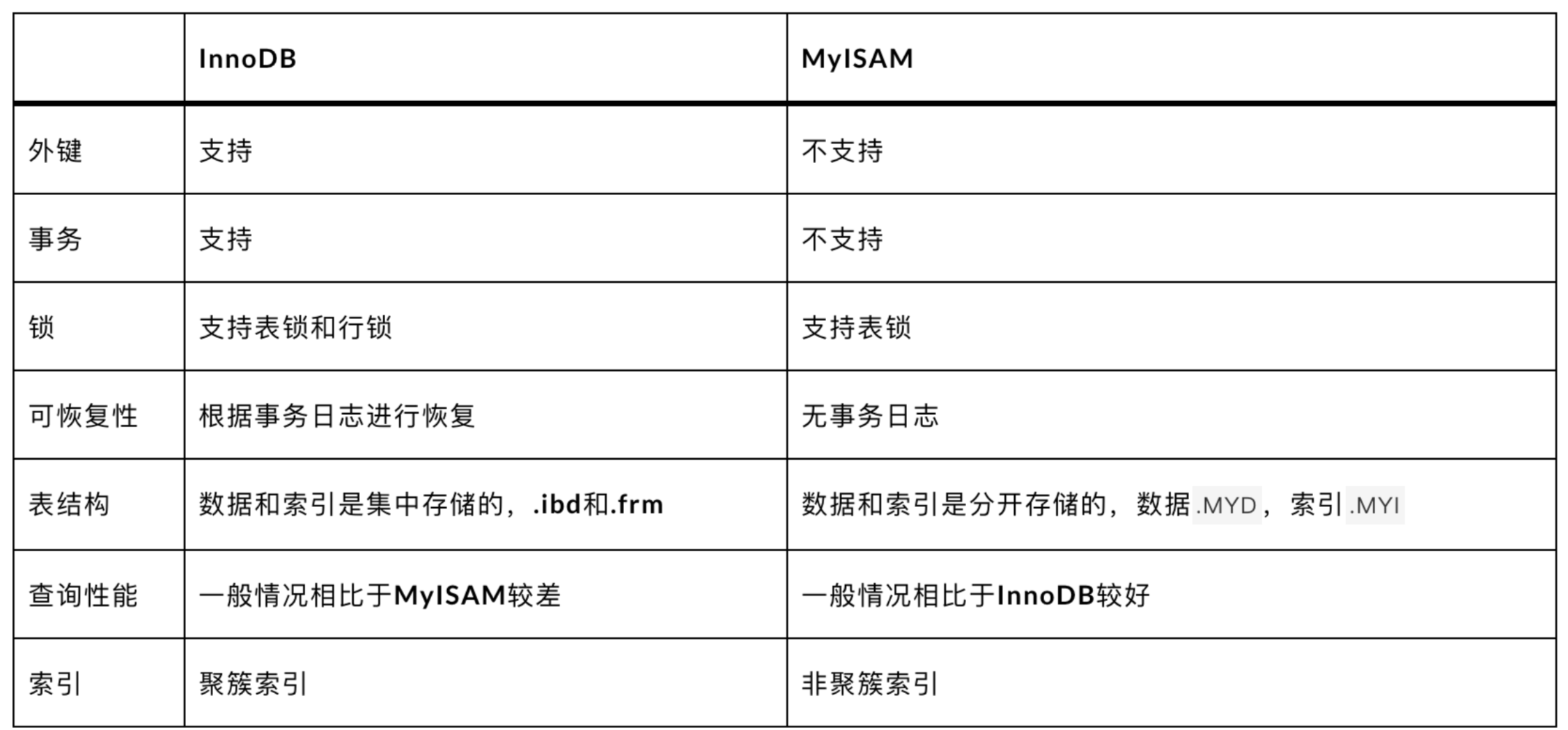
1.事务支持
2.行级锁
3.崩溃恢复(redolog)
4.聚簇索引和非聚簇索引
5.存储结构(innodb 是表结构 +聚簇索引即 .frm 和 .idb,myisam 是.frm + .myi + .myd)
6.Myisam count 优化
数据存储

InnoDB 引擎数据存储的方式采用的是索引组织表,在索引组织表中,数据即索引,索引即数据,因此表数据和索引数据都存储在同一个文件中。MYISAM 引擎数据存储的方式采用的是堆表,在堆表的组织结构中,数据和索引分开存储,因此表数据和索引数据会分别放在两个不同的文件中存储。
索引组织表优点:
- 在索引组织表将索引和数据保存在同一个B+树中,因此从聚簇索引中获取数据比非聚簇索引更快,查询数据会更快
- 在索引组织表中,二级索引设计有一个非常大的好处,若记录发生了修改,则其他索引无须进行维护除非记录的主键发生了修改,与堆表的索引实现对比着看,你会发现索引组织表在存在大量变更的场景,性能优势会非常明显,因为大部分情况下都不需要维护其他二级索引。
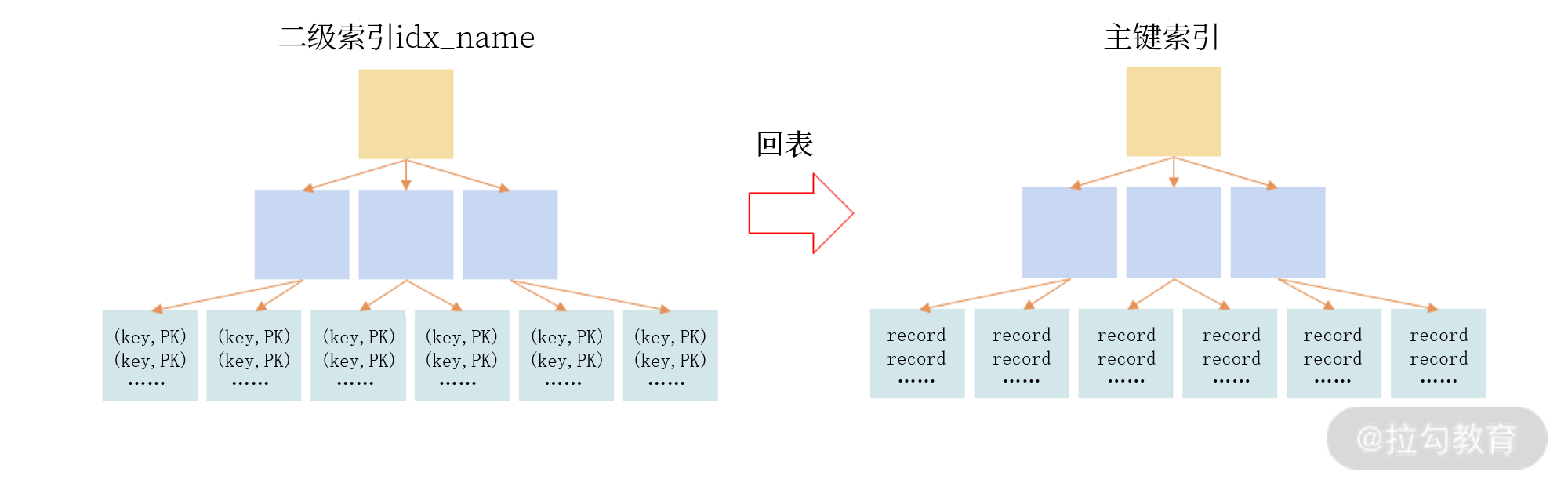
堆表缺点:
- 堆表中的索引都是二级索引,哪怕是主键索引也是二级索引,也就是说它没有聚簇索引,每次索引查询都要回表。
注:此处“每次索引查询都要回表”的意思是:不管是不是主键索引都需要先去索引表中找到索引,在根据索引中记录的位置去数据表中找到对应的记录,然后这边的回表就对应了根据索引找记录的过程。
- m

B+树结构
InnoDB 引擎 B+ 树叶子节点存储索引+数据,MyISAM 引擎 B+ 树叶子节点存储索引+数据地址。
事务
InnoDB支持事务,而MyISAM不支持。
锁粒度

COUNT(*) 查询性能
在执行COUNT(*)不带WHERE条件的查询时:
- MyISAM更快:因为MyISAM在表级别维护了一个计数器,记录表中的行数
- InnoDB较慢:需要全表扫描或索引扫描来计算行数
示例:
1 | -- MyISAM表,直接返回存储的行数 |
为什么InnoDB不维护行数计数器?这是因为InnoDB的MVCC机制,不同事务可能看到不同的行数。
读写性能
- 读操作:MyISAM在全表扫描的场景下通常更快
- 写操作:InnoDB的行级锁使其在高并发写入场景下表现更好
6. 数据类型与存储
6.1 MySQL中的数据类型
MySQL支持多种数据类型,合理选择数据类型可以优化存储空间和查询性能:
数字类型
- 整数:TINYINT, SMALLINT, MEDIUMINT, INT, BIGINT
- 浮点数:FLOAT, DOUBLE
- 定点数:DECIMAL
日期和时间类型
- DATE:日期,格式为’YYYY-MM-DD’
- TIME:时间,格式为’HH:MM:SS’
- DATETIME:日期和时间,格式为’YYYY-MM-DD HH:MM:SS’
- TIMESTAMP:时间戳,会随时区变化
字符串类型
- CHAR:定长字符串
- VARCHAR:变长字符串
- TEXT:长文本数据
二进制类型
- BINARY:定长二进制数据
- VARBINARY:变长二进制数据
- BLOB:二进制大对象
6.2 Mysql存储过程(微观)
以COMPACT行格式为例:

变长字段长度列表记录的是所有变长字段占用的字节之和,具体执行方案为:
- 条件一:如果变长字段允许存储的最大字节数小于等于 255 字节,就会用1字节表示「变长字段长度」
- 条件二:如果变长字段允许存储的最大字节数大于 255 字节,就会用2 字节表示「变长字段长度」
NULL值记录的是列表中值为null的信息,若为null则标注为1,否则为0.
因此,一行记录最大能存储 65535 字节的数据,但是这个是包含「变长字段字节数列表所占用的字节数」和[NULL值列表所占用的字节数」。所以,我们在算 varchar(n)中n最大值时,需要减去这两个列表所占用的字节数。
如果一张表只有一个 varchar(n)字段,且允许为 NULL,字符集为 ascii。varchar(n)中n最大取值为65532。
计算公式:65535-变长字段字节数列表所占用的字节数-NULL值列表所占用的字节数=65535-2-1=65532。
如果有多个字段的话,要保证所有字段的长度+变长字段字节数列表所占用的字节数 + NULL值列表所占用的字节数<= 65535。
6.3 CHAR与VARCHAR的比较
可以从三个方面考虑:
1.语义上的区别
char类型是一种固定长度的字符串类型,它在数据库中占用固定的存储空间,无论实际存储的数据长度是多。少,都会占用定义时指定的固定长度。例如,如果定义一个char(10)类型的字段,那么无论实际存储的数据长度是多少,都会占用10个字节的存储空间(字符集为ASCII的情况下,1个字符是 1字节大小,10 个字符就是 10 字节大小)。
而varchar类型是一种可变长度的字符串类型,它在数据库中只占用实际存储数据的长度加上一定的额外存储空间。例如,如果定义一个varchar(10)类型的字段,并存储了一个长度为5的字符串,那么它只会占用5个字节的存储空间(字符集为ASCII的情况下)加上一定的额外存储空间(存储字符串长度的空间)。
2.存储区别
varchar会占用额外的1~2字节来存储字符串长度。如果最大长度超过255,就需要2字节,否则1字节。
对于char(N)字段,如果实际存储数据小于N字节,会填充空格到N个字节。
3.修改区别
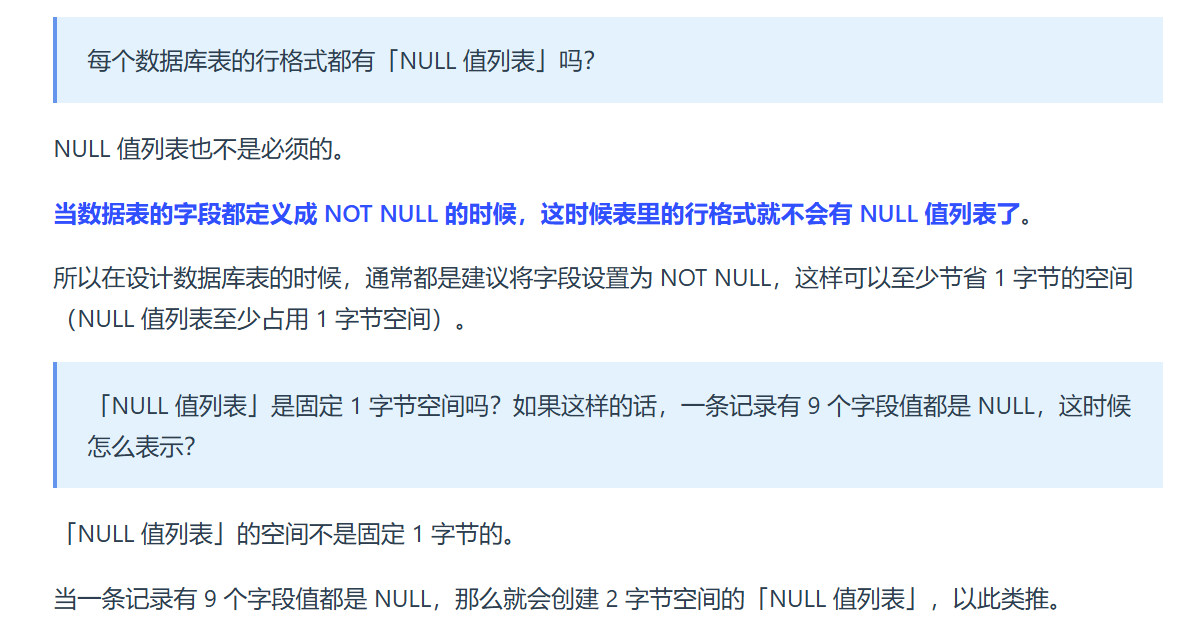
MySQL中的记录是存在于页中的,当字符串使用固定长度的char时,字段类型占用的空间会设置为最大值,方便修改操作可以在当前记录中进行修改(原地修改)(超出长度报错)
与磁盘IO的单位是页,记录越小页中存储的记录数量就可能越多,查询相同记录数量需要的IO次数就可能越少
由于记录中该类型的空间会先分配成最大值,长度会收到限制(最大不能超过255),使用时要设置成满足需求且尽量小的长度。
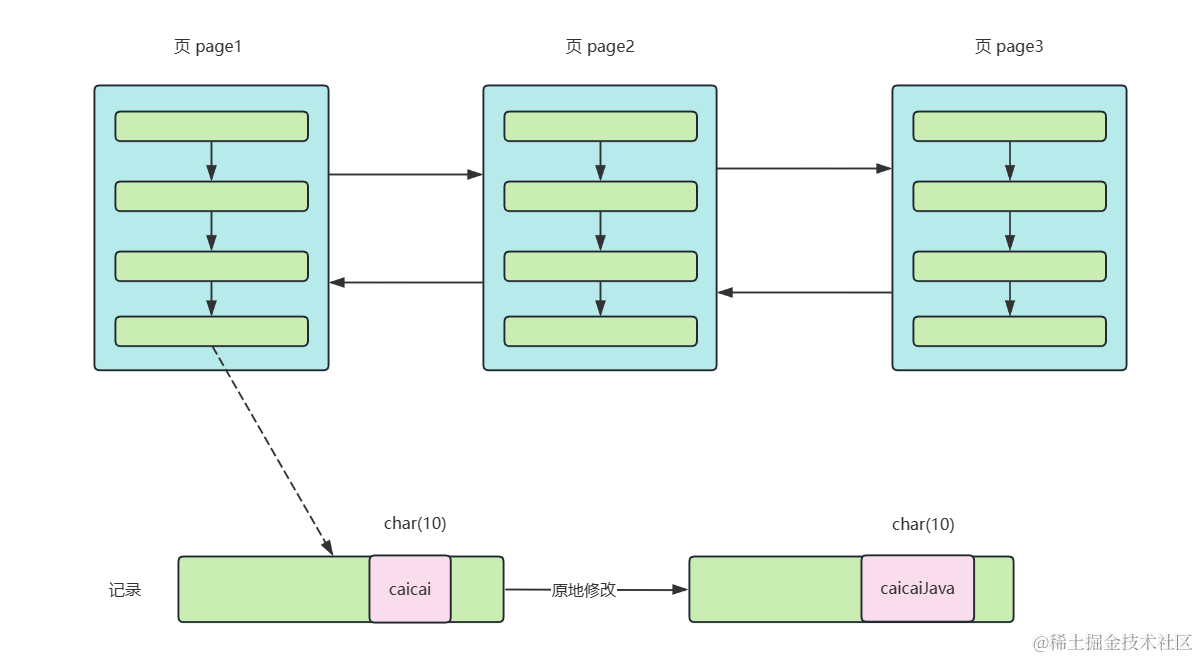
当修改varchar类型的字符串时,并不一定能和char类型一样在原地修改;当记录所在的页已满,而修改的varchar字符串又变长时,会产生新的页并重建记录放到新的页中。
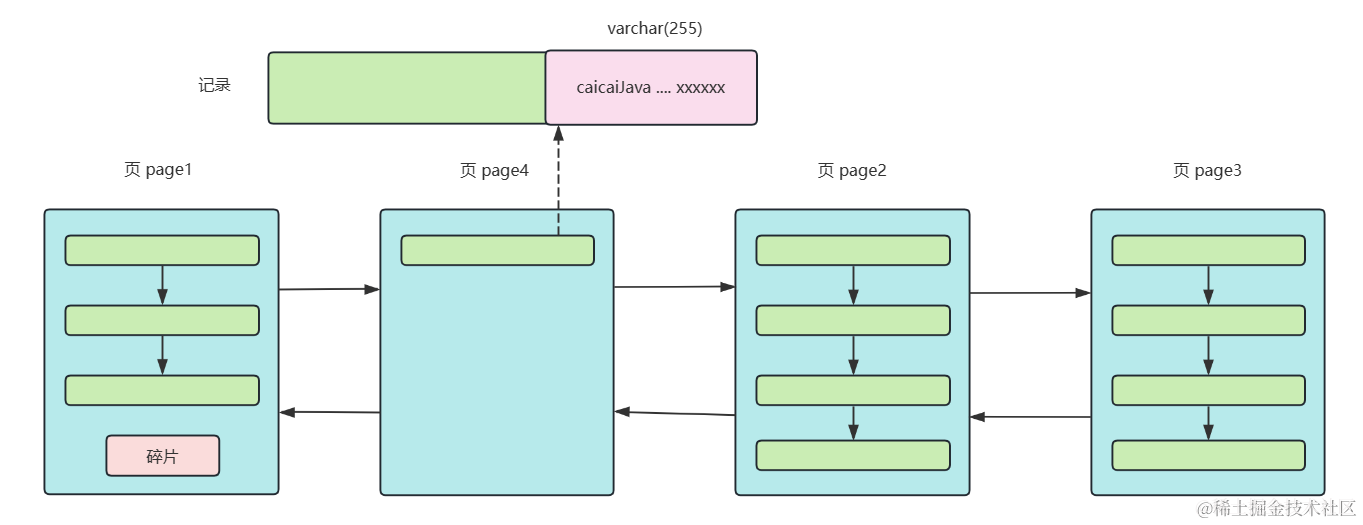
对于写操作来说,char能够原地修改,而varchar有重建记录、页分裂的开销
对于读操作,char与varchar类型的性能要看具体场景,如果char冗余部分空间,那么查询相同记录数量可能会增加IO次数;如果使用空间紧凑,那么性能会优于varchar
4.性能区别
理论上CHAR比VARCHAR更快,因为CHAR是固定长度的,而VARCHAR需要增加一个长度标识,处理时需要多一次运算。
理论上CHAR比VARCHAR快的根本原因是站在CPU的角度来说的,但性能是综合各种因素后的最终结果,当Innodb buffer pool小于表大小时,”磁盘读写”成为了性能的关键因素,而VARCHAR更短,因此性能反而比CHAR高。但是当Innodb buffer pool足够大时,CHAR 和VARCHAR性能没有太大的差别。
补充:
CHAR 和 VARCHAR 虽然分别用于存储定长和变长字符,但对于变长字符集(如 GBK、UTF8MB4),其本质是一样的,都是变长,设计时完全可以用 VARCHAR 替代 CHAR;
推荐 MySQL 字符集默认设置为 UTF8MB4,可以用于存储 emoji 等扩展字符;
排序(Collation)规则很重要,用于字符的比较和排序,但大部分场景不需要用区分大小写的排序规则;

6.4 存储空间问题详解
假如说一个字段是varchar(10),但它其实只有6个字节,那他在内存中占的存储空间是多少?在文件中占的存储空间是多少?

varchar(10)和varchar(100),如果只使用了5字节,内存和文件分别占用多少字节?
如果在mysql使用 utf8mb4 字符集(一个字符4字节),考虑到字符类型为变长类型,必须存储变长长度(至少占一个字节),因此肯定是不含NULL值的。
如此一来,varchar(10)在内存中占用40+1=41个字节,在文件中占用5+1=6字节( 文件就是你具体的字符串的长度,比如1个字符,那么就是 1 字符*字符集的大小然后还要加上额外的可变长字符串长度的空间。);
varchar(100)在内存中占用400+1=401 个字节,在文件中占用5+1=6字节。
在内存中是400+1,所以这里如果允许是 null varchar(100)内存里应该是400+1+1=402 个字节,以及文件里是 5+1+1=7个字节

7. 索引技术
7.1 索引基础
索引是数据库中用于提高查询性能的数据结构,类似于书的目录:
索引的基本概念
- 索引是指向表中数据的指针
- 索引是有序的数据结构
- 索引可以加速数据检索,但会减慢数据修改
索引的分类
- 按数据结构分:B+树索引、哈希索引、全文索引等
- 按功能分:主键索引、唯一索引、普通索引、全文索引等
- 按列数分:单列索引、联合索引(复合索引)
创建和管理索引
1 | -- 创建索引 |
7.2 B+树索引
B+树是MySQL中最常用的索引数据结构:
B+树结构原理
- 平衡树结构,所有叶子节点在同一层
- 非叶子节点只存储键值,不存储数据
- 叶子节点存储键值和数据(或数据指针)
- 叶子节点通过链表连接,方便范围查询
B+树索引的优势
- 高效的等值查询和范围查询
- 适合磁盘存储(减少I/O次数)
- 良好的扩展性和平衡性
InnoDB中的B+树索引
- 每个索引对应一棵B+树
- 索引页大小通常为16KB
- 树的高度通常为2-4层
7.3 聚簇索引与非聚簇索引的区别
InnoDB使用索引组织表,数据存储方式与索引密切相关:
聚簇索引(Clustered Index)
- 数据行存储在索引的叶子节点上
- 一个表只能有一个聚簇索引
- 默认情况下,主键索引是聚簇索引
- 如果没有定义主键,InnoDB会选择第一个唯一非空索引作为聚簇索引
- 如果没有主键也没有合适的唯一索引,InnoDB会生成一个隐藏的聚簇索引
非聚簇索引(辅助索引,Secondary Index)
- 叶子节点存储的是主键值,而不是数据行
- 通过辅助索引查找数据需要两次查找:先找到主键,再通过主键找到数据行
- 这个过程称为”回表”
对比
- 聚簇索引:数据访问更快,因为索引和数据存储在一起
- 非聚簇索引:需要额外的查找步骤,但维护成本较低
- 聚簇索引适合范围查询,非聚簇索引适合等值查询
实际应用建议
- 主键应选择较短的列(减少辅助索引大小)
- 主键应尽量使用递增值(避免页分裂)
- 避免频繁修改聚簇索引列的值
7.4 普通索引与唯一索引
普通索引与唯一索引的功能差异
- 普通索引:允许索引列有重复值
- 唯一索引:要求索引列值唯一(NULL除外)
性能对比
- 查询性能:理论上差别不大
- 更新性能:普通索引的更新操作通常比唯一索引快
更新性能分析
- 普通索引:使用change buffer,可能不需要立即读取原数据页
- 唯一索引:必须先读取原数据页,判断是否违反唯一性约束
使用建议
- 需要保证数据唯一性时使用唯一索引
- 对于频繁更新但不需要唯一约束的列,使用普通索引可能更有性能优势
- 读多写少的场景,两者性能差异不大
8. InnoDB的优化机制
8.1 缓冲池管理
缓冲池是InnoDB的核心内存结构,对性能有重要影响:
缓冲池的作用
- 缓存表数据和索引数据
- 减少磁盘I/O
- 提高查询和更新性能
LRU算法基础
- 传统LRU(Least Recently Used)算法:最近最少使用
- 当缓冲池满时,淘汰最久未使用的页
InnoDB对LRU的优化
- InnoDB使用改进的LRU算法
- 将缓冲池分为两部分:新生代(young)和老生代(old)
- 新页首先加入老生代,只有在老生代停留一段时间后被访问,才会移动到新生代
- 这种策略防止了一次性扫描大表对缓冲池的污染
冷热数据分离
- 新生代(young区域):约占缓冲池的5/8,存放热点数据
- 老生代(old区域):约占缓冲池的3/8,作为新页的缓冲区
- midpoint:新老生代的分界点,默认位于LRU列表的37%处
预读优化
- 线性预读:根据连续访问的模式,预读下一批数据页
- 随机预读:根据访问模式,预读附近的数据页
可以通过以下命令查看和调整缓冲池参数:
1 | -- 查看缓冲池大小 |
8.2 事务与锁
InnoDB的事务和锁机制是其核心特性:
事务隔离级别
- READ UNCOMMITTED(读未提交)
- READ COMMITTED(读已提交)
- REPEATABLE READ(可重复读,InnoDB默认级别)
- SERIALIZABLE(串行化)
锁类型
- 共享锁(S锁):允许多个事务同时读取同一行
- 排他锁(X锁):一个事务持有X锁时,其他事务不能对该行加任何锁
行锁实现
- 记录锁:锁定单个行记录
- 间隙锁:锁定索引记录之间的间隙
- Next-Key锁:记录锁和间隙锁的组合,防止幻读
死锁处理
- 超时机制:当锁等待超过设定时间,事务回滚(innodb_lock_wait_timeout)
- 死锁检测:主动检测死锁环,回滚代价较小的事务(innodb_deadlock_detect)
8.3 MVCC机制
多版本并发控制(MVCC)是InnoDB实现高并发的关键机制:
MVCC原理
- 保留数据的多个版本
- 每个事务看到的是数据在事务开始时的一致性快照
- 读写操作可以并行进行,不需要加锁
实现方式
- 隐藏列:每行数据有两个隐藏列(事务ID,回滚指针)
- 回滚段:存储旧版本数据
- 一致性读视图:事务开始时确定可见的版本范围
MVCC的优点
- 提高并发性能
- 实现一致性读
- 避免加锁带来的开销
读已提交与可重复读的区别
- 读已提交:每次SELECT都创建新的读视图
- 可重复读:事务中首次SELECT创建读视图,后续SELECT复用该视图
1 | I need to continue the teaching plan from where I left off. It seems my response was cut off at the section 8.3 about MVCC mechanism. I'll continue from there and ensure I complete the rest of section 8.3. The previous sections were: |
这样的MVCC机制使InnoDB能够在保证数据一致性的同时,提供较高的并发性能,是InnoDB成为MySQL默认存储引擎的重要原因之一。
读已提交与可重复读的隔离级别区别示例:
假设有一个账户表,初始余额为1000:
1 | CREATE TABLE accounts ( |
场景1:READ COMMITTED(读已提交)
- 事务A开始,查询账户余额
1 | START TRANSACTION; |
- 事务B开始,修改余额并提交
1 | START TRANSACTION; |
- 事务A再次查询余额
1 | SELECT balance FROM accounts WHERE id = 1; -- 返回2000 |
在READ COMMITTED级别,事务A可以看到事务B提交的修改。
场景2:REPEATABLE READ(可重复读)
- 事务A开始,查询账户余额
1 | START TRANSACTION; |
- 事务B开始,修改余额并提交
1 | START TRANSACTION; |
- 事务A再次查询余额
1 | SELECT balance FROM accounts WHERE id = 1; -- 仍然返回1000 |
在REPEATABLE READ级别,事务A看到的是事务开始时的快照,不会看到事务B的修改。
MVCC的局限性:
- 只适用于SELECT操作,不适用于UPDATE、DELETE操作
- 增加了存储和计算开销
- 回滚段可能占用大量空间
 微信
微信 支付寶
支付寶



