SQLTutorial01
1.多表查询
使用inner join ...on...进行表连接。
例:
1 | select qpd.device_id, qpd.question_id, qpd.result |
2.条件函数
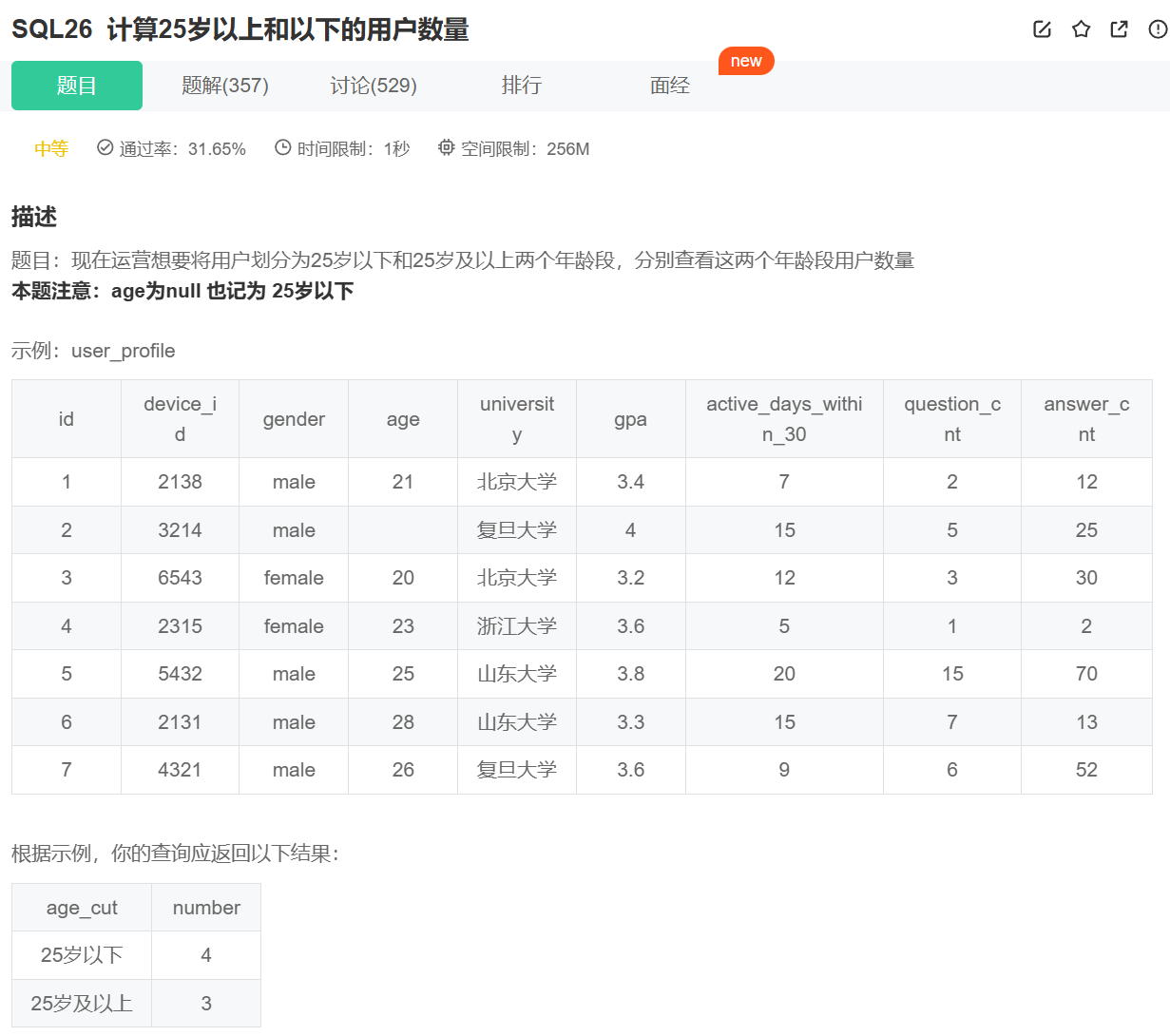
题目示例:计算25岁以上和以下的用户数量(SQL26)
1 | SELECT |
1. COUNT 的作用
COUNT 是聚合函数,用于统计行数。常见用法有两种:
- **
COUNT(*)**:统计所有行的数量,包括值为NULL的行。 - **
COUNT(column_name)**:统计指定列中非NULL值的行数。
在本题中的应用:
题目要求统计用户数量,且需包含 age 为 NULL 的情况。因此必须使用 COUNT(*),以确保所有行都被计数。
2. GROUP BY 的作用
GROUP BY 用于将结果集按指定列或表达式分组,每组返回一行。其核心逻辑是:
- 将相同值的行归为一组。
- 结合聚合函数(如
COUNT、SUM等),对每组数据进行统计。
在本题中的应用:
通过 CASE WHEN 生成年龄分类字段 age_cut(“25岁以下”或“25岁及以上”),再用 GROUP BY age_cut 将所有用户按此分类分为两组。每组内的行数即为该年龄段的用户数量。
3. 为什么结合 COUNT 和 GROUP BY 能解决问题?
以题目示例数据为例:
| 原始年龄 | 分类(CASE WHEN 生成) |
|---|---|
| 21 | 25岁以下 |
| NULL | 25岁以下 |
| 20 | 25岁以下 |
| 23 | 25岁以下 |
| 25 | 25岁及以上 |
| 28 | 25岁及以上 |
| 26 | 25岁及以上 |
分组过程:
GROUP BY age_cut将数据分为两组:- “25岁以下”组:包含年龄为21、NULL、20、23的4行。
- “25岁及以上”组:包含年龄为25、28、26的3行。
统计过程:
COUNT(*)对每组行数进行统计:- “25岁以下”组:
COUNT(*)结果为4。 - “25岁及以上”组:
COUNT(*)结果为3。
- “25岁以下”组:
先分组,再统计。
3.distinct关键字
用户表(
user_profile):device_id university 1 北京大学 2 复旦大学 3 北京大学 答题记录表(
question_practice_detail):device_id question_id 1 100 1 101 # 设备1回答了2个问题 2 102 # 设备2回答了1个问题 3 103 # 设备3回答了1个问题
执行结果:
| university | avg_answer_cnt | |
|---|---|---|
| 北京大学 | (2+1)/2 = 1.5 | # 总问题数3(设备1答2题,设备3答1题),不同设备数2 |
| 复旦大学 | 1/1 = 1 | # 总问题数1(设备2答1题),不同设备数1 |
1 | select university, |
DISTINCT关键字的作用
- 含义:
DISTINCT用于去重,确保统计的是唯一值。 - 在代码中的应用:
COUNT(DISTINCT qpd.device_id):统计每个大学中不同的设备数量。- 如果没有
DISTINCT,COUNT(qpd.device_id)会统计所有设备的答题记录数(包含重复设备),导致分母错误。
4.窗口函数与topk问题
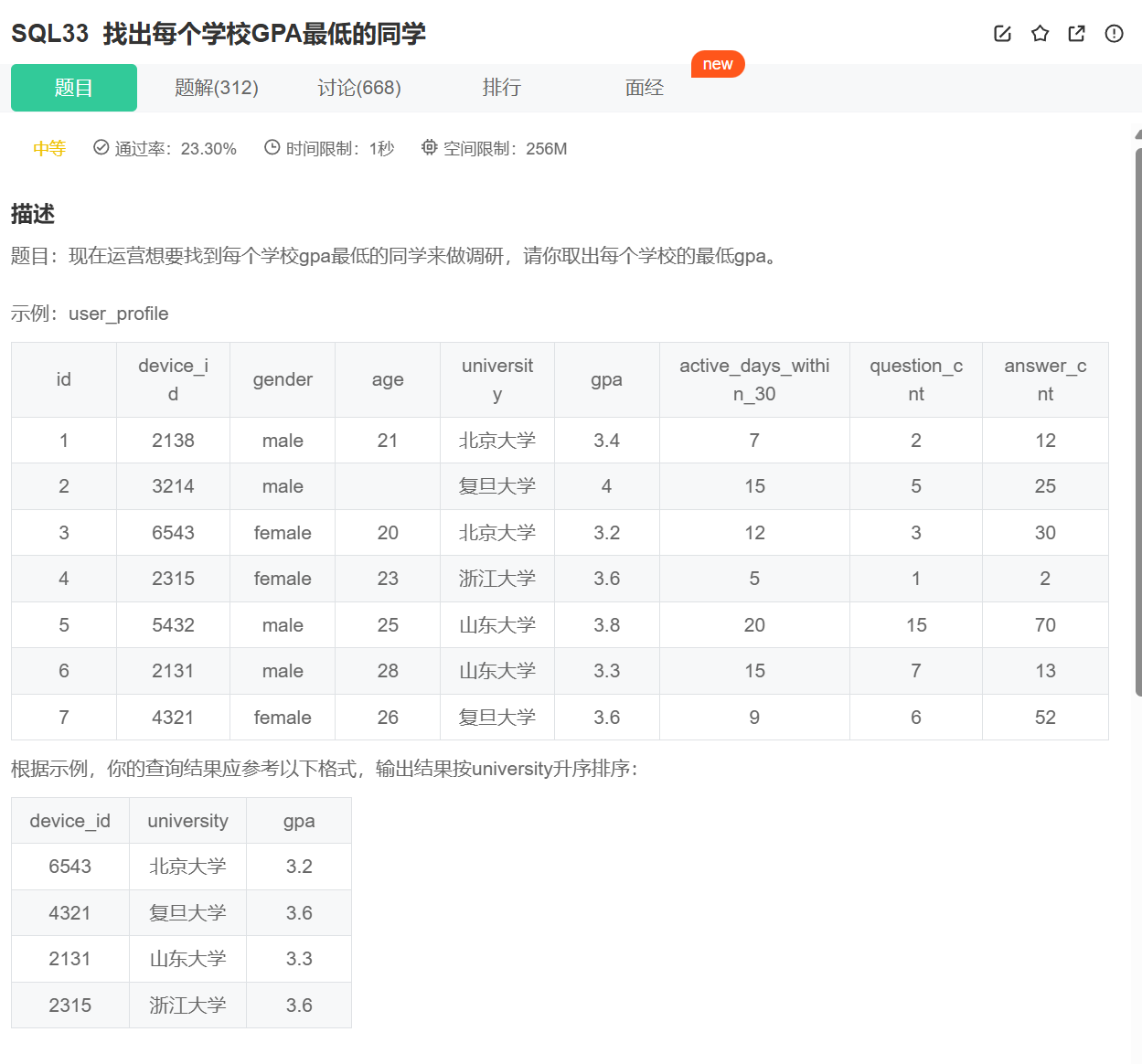
1 | SELECT device_id, university, gpa |
- **
ROW_NUMBER()**:窗口函数,为每一行分配一个唯一的序号。- **
PARTITION BY school**:按学校分区,每个学校的行独立编号。 - **
ORDER BY GPA ASC**:在每个学校内,按GPA升序排序(GPA越低,排名越靠前)。
- **
窗口函数详解
1. ROW_NUMBER() vs RANK() vs DENSE_RANK()
| 函数 | 行为 |
|---|---|
ROW_NUMBER() |
始终生成唯一序号(即使数据相同,如GPA并列最低,也会分配不同序号)。 |
RANK() |
相同值的行序号相同,但后续序号会跳跃(如1,1,3)。 |
DENSE_RANK() |
相同值的行序号相同,后续序号连续(如1,1,2)。 |
示例:若两学生GPA相同且最低:
1 | ROW_NUMBER() --> 1, 2 |
2. PARTITION BY 的作用
- 功能:将数据划分为多个独立的分区,窗口函数在每个分区内单独计算。
- 类比:类似于
GROUP BY,但不会折叠行,保留原始数据行的完整性。
3. ORDER BY GPA ASC 的意义
- 升序排序:GPA越低排名越靠前,因此
rank = 1对应GPA最低的学生。 - 降序排序:若改为
ORDER BY GPA DESC,则rank = 1对应GPA最高的学生。
适用场景
- Top K问题:如“每个部门薪资最高的员工”、“每个类别销量前3的产品”。
- 去重:当需要按某字段分组并保留特定行时(如保留最新记录)。
其实就是通过窗口函数新增一列ranking列,对每个分区下的ranking排列,再在外部的where语句查询最终结果。
5.日期函数
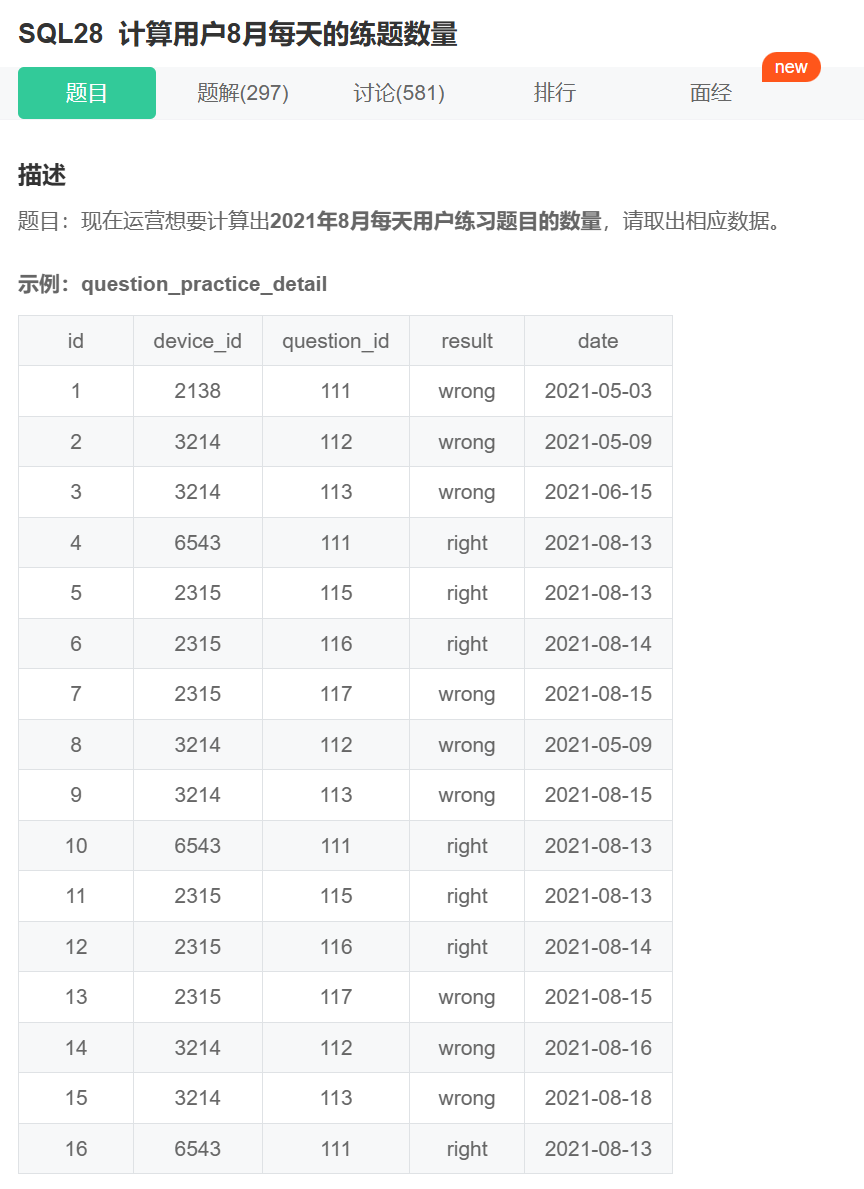
解法一:日期函数过滤
1 | select |
解法二:模糊查询
1 | SELECT DAY(date) day, |
6.左联表
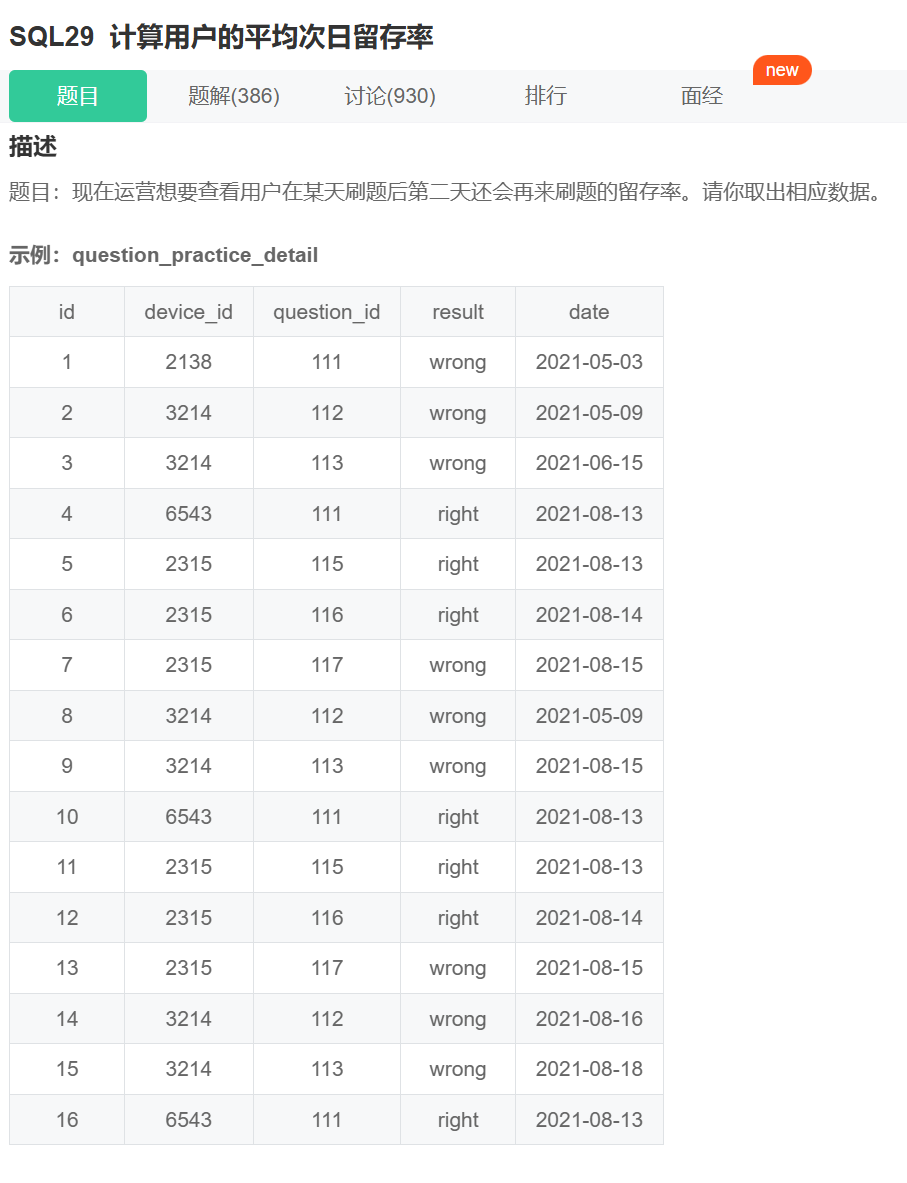
解决思路
- 数据去重:确保每个用户每天只计一次活跃记录。
- 自连接:将同一用户的连续两天活跃记录关联。
- 计算留存率:统计留存用户数除以总活跃用户数。
SQL代码
1 | SELECT |
代码解释
1. 数据去重
1 | (SELECT DISTINCT device_id, date FROM question_practice_detail) d1 |
- 作用:提取每个用户每天的 唯一活跃记录,避免同一天多次刷题重复计数。
- 示例:用户2315在2021-08-13有3条记录,去重后仅保留1条。
2. 自连接关联次日记录
1 | LEFT JOIN ... ON |
- 逻辑:将每个用户的活跃日期(
d1.date)与其次日活跃日期(d2.date)关联。 - 结果:
- 若用户次日有活跃,
d2.date不为NULL。 - 若用户次日无活跃,
d2.date为NULL。
- 若用户次日有活跃,
3. 计算留存率
1 | ROUND(COUNT(DISTINCT d2.device_id, d2.date) / COUNT(DISTINCT d1.device_id, d1.date), 4) |
- 分子:次日留存用户数(
d2中非NULL的记录)。 - 分母:总活跃用户数(
d1中所有记录)。 - **ROUND(…, 4)**:结果保留4位小数。
示例数据验证
输入数据
| device_id | date |
|---|---|
| 2138 | 2021-05-03 |
| 3214 | 2021-05-09 |
| 3214 | 2021-06-15 |
| 6543 | 2021-08-13 |
| 2315 | 2021-08-13 |
| 2315 | 2021-08-14 |
| 2315 | 2021-08-15 |
| 3214 | 2021-08-16 |
自连接结果
| d1.date | d2.date |
|---|---|
| 2021-05-03 | NULL |
| 2021-05-09 | NULL |
| 2021-06-15 | NULL |
| 2021-08-13 | 2021-08-14 |
| 2021-08-14 | NULL |
| 2021-08-15 | NULL |
| 2021-08-16 | NULL |
计算结果
- 分子(留存用户数):1(2021-08-13 → 2021-08-14)
- 分母(总活跃用户数):7
- 留存率:
1/7 ≈ 0.1429
总结
- 去重必要性:避免同一天多次刷题导致统计偏差。
- LEFT JOIN:保留所有首次活跃记录,即使次日无活跃。
- 日期函数:
DATE_ADD用于精确匹配次日日期。 - 结果精度:使用
ROUND控制小数位数。
7.例题

补充一下常见的日期函数吧:
NOW()- 返回当前的日期和时间。
DATEDIFF()-返回两个日期之间的天数差异。
DATE_SUB()-从一个日期中减去指定的时间间隔。
DATE_ADD()-向一个日期加上指定的时间间隔。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 0kr's Blog!
 微信
微信 支付寶
支付寶
评论



