OS01
本篇讲述操作系统的硬件结构相关知识。
一、基础概念
在开始探讨复杂的计算机系统之前,我们需要先了解一些基础概念,包括冯诺依曼模型以及系统的基本组成。这些概念是我们理解后续内容的基础。
1. 冯诺依曼模型介绍
冯诺依曼模型是现代计算机体系结构的基础,包含五个基本部件:运算器、控制器、存储器、输入设备和输出设备。该模型的核心思想是”存储程序”,即程序和数据都存储在同一个存储器中。
冯诺依曼模型有哪些组成?
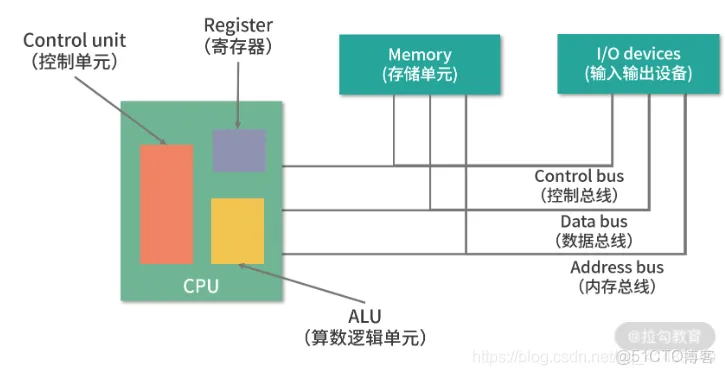
- 中央处理器(运算器和控制器)
- 内存(存储器,图中为存储单元)
- 总线(连接各部件)
- 输入、输出设备
- 其他存储设备(图中未显示)
运算器、控制器是在中央处理器里的,存储器就我们常见的内存,输入输出设备则是计算机外接的设备比如键盘就是输入设备,显示器就是输出设备。
存储单元和输入输出设备要与中央处理器打交道的话,离不开总线。所以,它们之间的关系如下图:
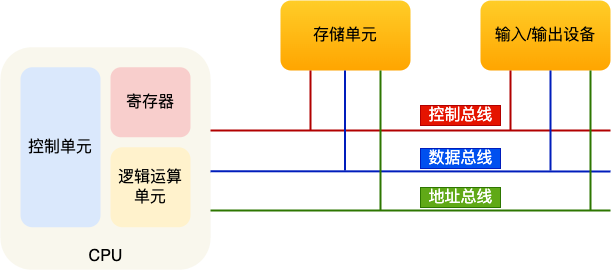
接下来,分别介绍内存、中央处理器、总线、输入输出设备。
内存
我们的程序和数据都是存储在内存,存储的区域是线性的。
在计算机数据存储中,存储数据的基本单位是字节(byte),1字节等于8位(8 bit)。每一个字节都对应一个内存地址。
内存的地址是从0开始编号的,然后自增排列,最后一个地址为内存总字节数 - 1,这种结构好似我们程序里的数组,所以内存的读写任何一个数据的速度都是一样的。
CPU
中央处理器也就是我们常说的CPU(Central Processing Unit),32位和64位CPU最主要区别在于一次能计算多少字节数据:
- 32位CPU一次可以计算4个字节;
- 64位CPU一次可以计算8个字节;
这里的32位和64位,通常称为CPU的位宽,代表的是CPU一次可以计算(运算)的数据量。
之所以CPU要这样设计,是为了能计算更大的数值,如果是8位的CPU,那么一次只能计算1个字节0-255范围内的数值,这样就无法一次完成计算10000 * 500,于是为了能一次计算大数的运算,CPU需要支持多个byte一起计算;所以CPU位宽越大,可以计算的数值就越大,比如说32位CPU能计算的最大整数是4294967295。
CPU内部还有一些组件,常见的有寄存器、控制单元和逻辑运算单元等。其中,控制单元负责控制CPU工作,逻辑运算单元负责计算,而寄存器可以分为多种类,每种寄存器的功能又不尽相同。
CPU中的寄存器主要作用是存储计算时的数据,你可能好奇为什么有了内存还需要寄存器?原因很简单,因为内存离CPU太远了,而寄存器就在CPU里,还紧挨着控制单元和逻辑运算单元,自然计算的速度会很快。后面我们还会再讲到。
常见的寄存器种类有:
- 通用寄存器(GR,General register),可用于传送和暂存数据,也可参与算术逻辑运算,并保存运算结果。除此之外,它们还各自具有一些特殊功能。
比如16位cpu通用寄存器共有8个:AX(累加器(Accumulator Register)),BX(基地址寄存器(Base Register)),CX(计数寄存器(Count Register)),DX(数据寄存器(Data Register)),BP(基址指针寄存器(Base Pointer)),SP(堆栈指针寄存器(Stack Pointer)),SI(源变址寄存器 (Source Index)),DI(目的变址寄存器(Destination Index)).八个寄存器都可以作为普通的数据寄存器使用。
- 程序计数器(PC,Program counter),用来存储CPU要执行下一条指令「所在的内存地址」,注意不是存储了下一条要执行的指令,此时指令还在内存中,程序计数器只是存储了下一条指令的地址。当执行一条指令时,首先需要根据PC中存放的指令地址,将指令由内存取到指令寄存器中,此过程称,为“取指令”。与此同时,PC中的地址或自动加1或由转移指针给出下一条指令的地址。此后经过分析指令,执行指令。完成第一条指令的执行,而后根据PC取出第二条指令的地址,如此循环,执行每一条指令。
- 指令寄存器(IR,Instruction Register),用来存放当前正在执行的指令,也就是指令本身,指令被执行完成之前,指令都存储在这里。
总线
总线是用于 CPU 和内存以及其他设备之间的通信,总线可分为3种:
- 地址总线,用于指定 CPU 将要操作的内存地址;
- 数据总线,用于读写内存的数据;
- 控制总线,用于发送和接收信号,比如中断、设备复位等信号,CPU 收到信号后自然进行响应,这时也需要控制总线;
当 CPU 要读写内存数据的时候,一般需要通过下面这三个总线:
- 首先要通过「地址总线」来指定内存的地址;
- 然后通过「控制总线」控制是读或写命令;
- 最后通过「数据总线」来传输数据;
输入输出设备
输入设备向计算机输入数据,计算机经过计算后,把数据输出给输出设备。期间,如果输入设备是键盘,按下按键时是需要和 CPU 进行交互的,这时就需要用到控制总线了。这里的触发顺序个人感觉可以理解为:先用地址总线查找,再用数据总线传输,期间控制总线控制中断或者异常信号。
3. 计算机系统的基本组成
计算机系统由硬件和软件两部分组成。硬件包括CPU、内存、输入输出设备和总线等;软件包括系统软件(如操作系统)和应用软件。
在这里最需要明确的是操作系统处于电脑中的哪个层次:

操作系统是在硬件基础上的第一层扩展,很多与硬件有关的工作都是通过操作系统调用反馈到硬件完成的。
二、CPU执行程序的过程
1. 线路位宽与CPU位宽
到此你可能会问,介绍了总线,那数据如何通过线路传递的呢?其实是通过操作电压,低电压是 0,高电压是 1。
如果只有一条线路,每次只能传递1个信号,因为你必须在 0,1中选一个。比如你构造高高低低这样的信号,其实就是 1100——这种传递是相当慢的,因为你需要传递 4 次。
这种一个 bit 一个 bit 发送的方式,我们叫作串行。如果希望每次多传一些数据,就需要增加线路,也就是需要并行。
如果只有1条地址总线,那每次只能表示 0-1两种情况,所以只能操作2个内存地址;如果有 10 条地址总线,一次就可以表示 2^10 种情况,也就是可以操作 1024 个内存地址;如果你希望操作 4G 的内存,那么就需要 32 条线,因为 2^32 是 4G。
请注意,我们刚刚所说的都是线路位宽,指数据总线一次能传输的位数。那么CPU位宽,其实就是指其能处理的数据位数。
那么很显然,CPU 的位宽最好不要小于线路位宽,比如 32 位 CPU 控制 40 位宽的地址总线和数据总线的话,工作起来就会非常复杂且麻烦,所以 32 位的 CPU 最好和 32 位宽的线路搭配,因为 32 位 CPU 一次最多只能操作32 位宽的地址总线和数据总线。
如果用 32 位 CPU 去加和两个 64 位大小的数字,就需要把这2个 64 位的数字分成2个低位 32 位数字和2 个高位 32 位数字来计算,先加个两个低位的 32 位数字,算出进位,然后加和两个高位的 32 位数字,最后再加上进位,就能算出结果了,可以发现 32 位 CPU 并不能一次性计算出加和两个 64 位数字的结果。对于 64 位 CPU 就可以一次性算出加和两个 64 位数字的结果,因为 64 位 CPU 可以一次读入 64 位的数字,并且 64 位 CPU 内部的逻辑运算单元也支持 64 位数字的计算。
但这并不代表 64 位 CPU 性能比 32 位 CPU 高很多。要知道,大部分应用不需要计算超过 32 位的数字,比如你做一个电商网站,用户的金额通常是 10 万以下的,而 32 位有符号整数,最大可以到20 亿。所以这样的计算在 32 位还是 64 位中没有什么区别。
另外,32 位 CPU 最大只能操作 4GB 内存,就算你装了8GB 内存条,也没用。而 64 位 CPU 寻址范围则很大,理论最大的寻址空间为2^64。
2. 指令周期
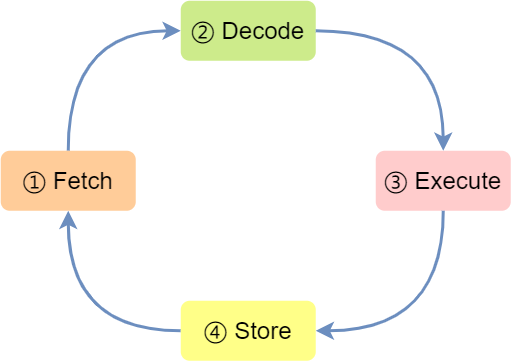
CPU执行指令的基本周期包括:
- 取指(Fetch):从内存读取指令
- 译码(Decode):解释指令的含义
- 执行(Execute):执行指令(可能涉及读取操作数、进行计算、访问内存等)
- 写回(Write-back):将结果写回寄存器或内存
这四个步骤构成了CPU执行任何指令的基本循环,无论是简单的加法还是复杂的浮点运算,都遵循这一过程。
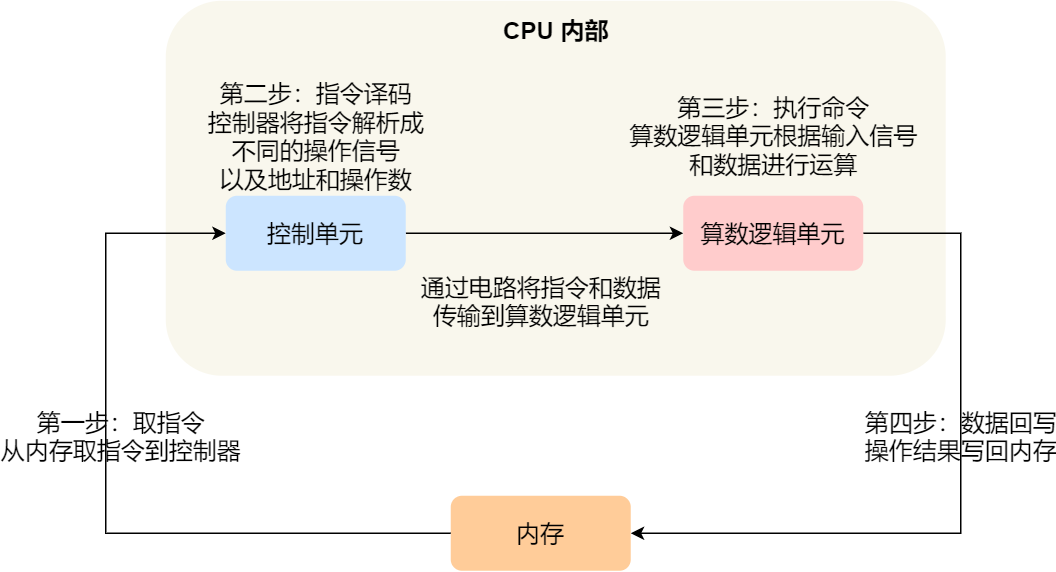
事实上,不同的阶段其实是由计算机中的不同组件完成的:
3. 示例:a = 1 + 2 的执行过程
知道了基本的程序执行过程后,让我们通过一个简单的赋值操作 a = 1 + 2 来理解CPU执行程序的具体过程。
CPU 是不认识 a = 1 + 2 这个字符串,这些字符串只是方便我们程序员认识,要想这段程序能跑起来,还需要把整个程序翻译成[汇编语言]的程序,这个过程称为编译或汇编代码。
对于汇编代码,我们还需要用汇编器翻译成机器码,这些机器码由 0 和 1 组成的机器语言,这一条条机器码,就是一条条的[计算机指令],这个才是 CPU 能够真正认识的东西。
下面来看看 a = 1 + 2 在 32 位 CPU 的执行过程。
程序编译过程中,编译器通过分析代码,发现 1 和 2 是数据,于是程序运行时,内存会有个专门的区域来存放这些数据,这个区域就是「数据段」。如下图,数据 1 和 2 的区域位置:
- 数据 1 被存放到 0x200 位置;
- 数据 2 被存放到 0x204 位置;
注意,数据和指令是分开区域存放的,存放指令区域的地方称为「正文段」。
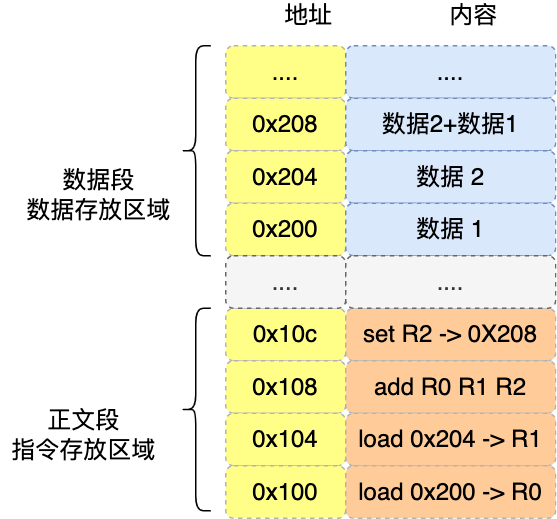
编译器会把 a=1+2翻译成4条指令,存放到正文段中。如图,这4条指令被存放到了 0x100 ~0x10c 的区域中:
- 0x100 的内容是 load 指令将 0x200 地址中的数据1装入到寄存器 R ;·
- 0x104 的内容是 load 指令将 0x204 地址中的数据2装入到寄存器 R1;
- 0x108 的内容是 add 指令将寄存器 R8 和 R1的数据相加,并把结果存放到寄存器 R2;
- 0x10c 的内容是 store 指令将寄存器 R2 中的数据存回数据段中的 0x208 地址中,这个地址也就是变量 a 内存中的地址;
编译完成后,具体执行程序的时候,程序计数器会被设置为 0x100 地址,然后依次执行这4条指令:
- 取指:CPU从程序计数器读取指令地址,从内存中取出”加载数值1到寄存器R1”的指令
- 译码:CPU解析指令,确定需要执行的操作是将常数1加载到寄存器R1
- 执行:CPU将数值1加载到寄存器R1
- 取指:取出”加载数值2到寄存器R2”的指令
- 译码:解析为将常数2加载到寄存器R2
- 执行:CPU将数值2加载到寄存器R2
- 取指:取出”将R1和R2相加,结果存入R3”的指令
- 译码:解析为将R1和R2相加,结果存入R3
- 执行:CPU执行加法运算,1+2=3,将结果3存入寄存器R3
- 取指:取出”将R3的值存入变量a的内存地址”的指令
- 译码:解析为存储操作
- 执行:CPU将R3中的值3存入变量a的内存地址
- 写回:操作完成,变量a的值被更新为3
上面的例子中,由于是在 32 位 CPU 执行的,因此一条指令是占 32 位大小,所以你会发现每条指令间隔4 个字节。
而数据的大小是根据你在程序中指定的变量类型,比如 int 类型的数据则占4个字节, char 类型的数据则占1个字节。
4. 指令类型
上面的例子中,图中指令的内容我写的是简易的汇编代码,目的是为了方便理解指令的具体内容,事实上指令的内容是一串二进制数字的机器码,每条指令都有对应的机器码,CPU 通过解析机器码来知道指令的内容。
不同的 CPU 有不同的指令集,也就是对应着不同的汇编语言和不同的机器码,接下来选用最简单的 RISC-V 指令集,来看看机器码是如何生成的,这样也能明白二进制的机器码的具体含义。
RISC-V 的指令是一个 32 位的整数,高 7 位代表着操作码,表示这条指令是一条什么样的指令,剩下的 25 位不同指令类型所表示的内容也就不相同,主要有六种类型:R、I、S、B、U 和 J。
1 | 32 位 |
一起具体看看这六种类型的含义:
- R 指令,用在算术和逻辑操作,里面有读取和写入数据的寄存器地址。高7位的操作码指示这是什么类型的指令,接下来有三个5位的寄存器地址字段(rs1源寄存器1,rs2源寄存器2,rd目标寄存器),最后10位包含功能码,用于进一步指定具体操作;
- I 指令,用在立即数操作、加载指令和跳转指令。这个类型的指令,没有rs2寄存器,而是把这部分和后面的位一起合并成了一个12位的立即数字段;
- S 指令,用在存储操作。这个类型有rs1和rs2,但没有rd,因为存储操作不需要写回寄存器,而是把数据写入内存,立即数分成了两部分,表示存储的内存地址偏移;
- B 指令,用在条件分支。与S型类似,但立即数字段被重新排列,以便于计算分支目标地址;
- U 指令,用在长立即数操作。顾名思义,这类指令的立即数字段更大,占据了指令的大部分位置;
- J 指令,用在无条件跳转。与MIPS类似,高7位之外的25位大部分用于表示跳转目标地址。
接下来,我们把前面例子的这条指令:「add 指令将寄存器 R0 和 R1 的数据相加,并把结果放入到 R2」,翻译成RISC-V机器码。
在RISC-V中,这条add指令的格式是R型,它的二进制表示为:0000000 00001 00000 000 00010 0110011,其中:
- 0110011是操作码,表示这是一个R型整数运算指令
- 00010是rd(R2),目标寄存器
- 000是功能码,表示这是加法操作
- 00000是rs1(R0),第一个源寄存器
- 00001是rs2(R1),第二个源寄存器
- 0000000是另一部分功能码,进一步指定这是普通加法
把上面这些数字拼在一起,就是一条 32 位的 RISC-V 加法指令了。编译器在编译程序的时候,会构造指令,这个过程叫做指令的编码。CPU 执行程序的时候,就会解析指令,这个过程叫作指令的解码/译码。
5. 指令执行速度
CPU的硬件参数都会有 GHz 这个参数,比如一个 1 GHz 的 CPU,指的是时钟频率是 1 G,代表着 1 秒会产生 1G 次数的脉冲信号,每一次脉冲信号高低电平的转换就是一个周期,称为时钟周期。
对于 CPU 来说,在一个时钟周期内,CPU 仅能完成一个最基本的动作,时钟频率越高,时钟周期就越短,工作速度也就越快。
一个时钟周期一定能执行完一条指令吗?答案是不一定的,大多数指令不能在一个时钟周期完成,通常需要若干个时钟周期。不同的指令需要的时钟周期是不同的,加法和乘法都对应着一条 CPU 指令,但是乘法需要的时钟周期就要比加法多。
如何让程序跑的更快?
程序执行的时候,耗费的 CPU 时间少就说明程序是快的,对于程序的 CPU 执行时间,我们可以拆解成CPU 时钟周期数(CPU Cycles)和时钟周期时间(Clock Cycle Time)的乘积。
1 | 程序的 CPU 执行时间 = CPU 时钟周期数 x 时钟周期时间 |
时钟周期时间就是我们前面提及的 CPU 主频,主频越高说明 CPU 的工作速度就越快,比如我手头上的电脑的 CPU 是 2.4 GHz 四核 Intel Core i5,这里的 2.4 GHz 就是电脑的主频,时钟周期时间就是 1/2.4G。
要想 CPU 跑的更快,自然缩短时钟周期时间,也就是提升 CPU 主频,但是今非彼日,摩尔定律早已失效,当今的 CPU 主频已经很难再做到翻倍的效果了。
另外,换一个更好的 CPU,这个也是我们软件工程师控制不了的事情,我们应该把目光放到另外一个乘法因子 —— CPU 时钟周期数,如果能减少程序所需的 CPU 时钟周期数量,一样也是能提升程序的性能的。
对于 CPU 时钟周期数我们可以进一步拆解成:指令数 x 每条指令的平均时钟周期数(Cycles Per Instruction, 简称 CPI),于是程序的 CPU 执行时间的公式可变成如下:
1 | 程序的 CPU 执行时间 = 指令数 x CPI x 时钟周期时间 |
因此,要想程序跑的更快,优化这三者即可:
- 指令数,表示执行程序所需要多少条指令,以及哪些指令。这个层面是基本靠编译器来优化,毕竟同样的代码,在不同的编译器,编译出来的计算机指令会有各种不同的表示方式。
- 每条指令的平均时钟周期数 CPI,表示一条指令需要多少个时钟周期数,现代大多数 CPU 通过流水线技术(Pipeline),让一条指令需要的 CPU 时钟周期数尽可能的少;
- 时钟周期时间,表示计算机主频,取决于计算机硬件。有的 CPU 支持超频技术,打开了超频意味着把 CPU 内部的时钟给调快了,于是 CPU 工作速度就变快了,但是也是有代价的,CPU 跑的越快,散热的压力就会越大,CPU 会很容易奔溃。
很多厂商为了跑分而跑分,基本都是在这三个方面入手的呢,特别是超频这一块。
 微信
微信 支付寶
支付寶



