FeatureEngineering03
主成分分析(Principal Component Analysis)
在前一课中,我们了解了特征工程的第一个基于模型的方法:聚类。在本课中,我们将学习下一个方法:主成分分析(PCA)。就像聚类是基于接近度对数据集进行划分一样,PCA可以被视为对数据变异性的划分。PCA是探索数据中重要关系并创建更具信息量特征的有效工具。
说明:PCA通常应用于标准化数据。对于标准化数据,”变异性”意味着”相关性”。对于未标准化数据,”变异性”意味着”协方差”,我们也不需要这玩意儿(详情理论可以学习概率论相关知识)。本课程中的所有数据在应用PCA前都将被标准化。
主成分分析
我们使用的是Abalone数据集,其中包含了几千个塔斯马尼亚鲍鱼的物理测量值。我们现在只看两个特征:”高度”和”直径”。
您可以想象,在这些数据中存在”变异性轴(variation)”,描述了鲍鱼之间的差异方式。在图形上,这些轴表现为沿数据自然维度的垂直线,每个原始特征对应一个轴。
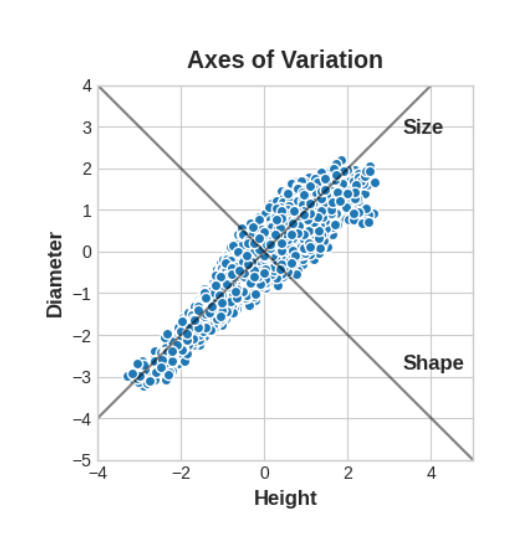
通常,我们可以为这些变异性轴命名。较长的轴我们可以称为”Size”成分:小高度和小直径(左下方)与大高度和大直径(右上方)形成对比。较短的轴我们可以称为”Shape”成分:小高度和大直径(扁平形状)与大高度和小直径(圆形形状)形成对比。
注意,我们不必用”高度”和”直径”来描述鲍鱼,也可以用”大小”和”形状”来描述。这实际上就是PCA的核心思想:我们不用原始特征描述数据,而是用它的变异性轴。这些变异性轴成为新的特征。
译者注:不是翻得不好原文就是很拗口,我再说明一下。PCA的作用就是,将新的特征/坐标轴沿着数据变异的主要方向设置。这样做的好处就是,变换后,数据可以用更少、更有解释性的特征来描述,比如说size和shape。Is that clearer?
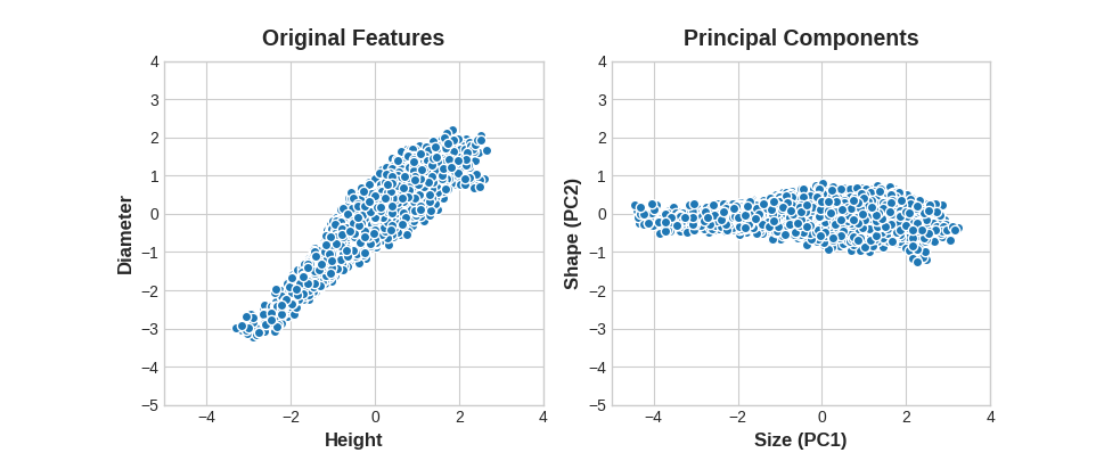
PCA构造的新特征实际上只是原始特征的线性组合(加权和):
1 | df["Size"] = 0.707 * X["Height"] + 0.707 * X["Diameter"] |
这些新特征被称为数据的主成分(principal components)。这些权重被称为载荷(loadings)。原始数据集有多少特征,就会有多少主成分:如果我们使用了十个特征而不是两个,我们会得到十个成分。
一个成分的载荷通过正负号和大小告诉我们它表达了什么变异性:
| Features \ Components | Size (PC1) | Shape (PC2) |
|---|---|---|
| Height | 0.707 | 0.707 |
| Diameter | 0.707 | -0.707 |
这个载荷表显示,在”大小”成分中,”高度”和”直径”朝同一方向变化(同号),但在”形状”成分中,它们朝相反方向变化(异号)。在每个成分中,载荷大小相同,因此两个特征在两个成分中的贡献均等。
PCA还告诉我们每个成分中变异性的数量。从图中可以看出,数据在”大小”成分上的变异性比在”形状”成分上的大。PCA通过每个成分的解释方差百分比精确地量化了这一点。
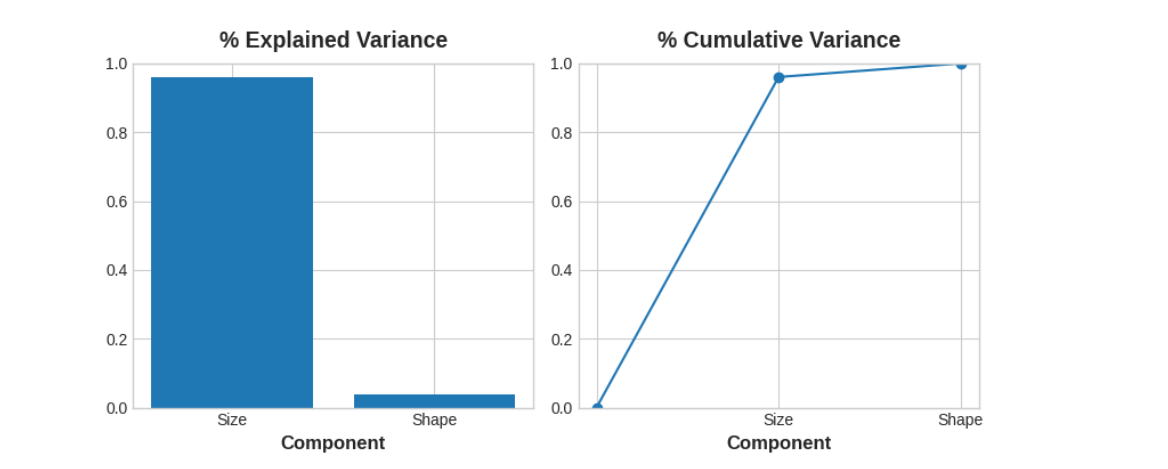
“大小”成分解释了约96%的”高度”和”直径”之间的方差,而”形状”成分解释了约4%。
需要记住的是,成分中的方差量不一定对应于它作为预测因子的好坏:这取决于你要预测什么。
译者注:这里可以多举几个例子方便理解。
预测特征的有效性主要取决于它与预测目标的相关性,而不仅仅是它在原始数据中解释的方差量。例如:如果你要预测鲍鱼的年龄,可能”形状”特征(尽管只解释4%的方差)与年龄的相关性比”大小”特征更强;如果预测鲍鱼的重量,”大小”特征可能更有用。
在疾病诊断中,某些罕见但关键的生物标志物可能只在数据中占很小的变异性,但对特定疾病的诊断却至关重要;
在图像识别中,背景像素可能占据大部分图像方差,但对识别目标对象的贡献却很小。
因此,低方差成分虽然只占据很小的变异量,但是在异常检测和离群值识别任务中可能有奇效。It depends.
PCA用于特征工程
使用PCA进行特征工程有两种方式:
第一种是将其作为描述性技术。由于成分能告诉你关于变异性的信息,你可以计算成分的MI分数,看看哪种变异性最能预测你的目标。这可以启发你创建什么类型的特征 —— 如果”大小”很重要,可以是”高度”和”直径”的乘积,或者如果”形状”很重要,可以是”高度”和”直径”的比率。你甚至可以尝试在一个或多个高分成分上进行聚类。
第二种方式是直接将这些成分用作特征。由于这些成分直接揭示了数据的变异结构,它们通常比原始特征更具信息量。以下是一些用例:
- 降维:当特征高度冗余(特别是共线性)时,PCA会将冗余分离到一个或多个接近零方差的成分中,你可以丢弃这些成分,因为它们几乎不包含信息。
- 异常检测:在原始特征中不明显的异常变异通常会在低方差成分中显现。这些成分在异常或离群值检测任务中可能非常有信息量。
- 降噪:传感器读数集合通常会共享一些共同的背景噪声。PCA有时可以将(信息量大的)信号收集到较少的特征中,同时将噪声分离出来,从而提高信噪比。
- 去相关:一些机器学习算法在处理高度相关的特征时表现不佳。PCA将相关特征转换为不相关的成分,这可能使算法更容易处理。
PCA基本上让你直接访问数据的相关结构。你肯定会想出自己的应用!
PCA最佳实践
应用PCA时需要牢记几点:
- PCA只适用于数值特征,如连续量或计数。
- PCA对尺度敏感。除非你有充分理由不这样做,否则最好在应用PCA之前标准化你的数据。
- 考虑移除或约束离群值,因为它们可能对结果产生过度影响。
示例:1985年汽车数据PCA分析
在这个例子中,我们将回到我们的汽车数据集并应用PCA,将其用作发现特征的描述性技术。我们将在练习中查看其他用例。
这个隐藏单元加载数据并定义函数plot_variance和make_mi_scores。
1 | # ......... |
我们选择了四个覆盖一系列属性的特征。这些特征中的每一个与目标price也有较高的MI分数。我们将标准化数据,因为这些特征在自然状态下不在同一尺度上。
1 | features = ["highway_mpg", "engine_size", "horsepower", "curb_weight"] |
现在我们可以拟合scikit-learn的PCA估计器并创建主成分。您可以在这里看到转换后数据集的前几行。
1 | from sklearn.decomposition import PCA |
| PC1 | PC2 | PC3 | PC4 | |
|---|---|---|---|---|
| 0 | 0.382486 | -0.400222 | 0.124122 | 0.169539 |
| 1 | 0.382486 | -0.400222 | 0.124122 | 0.169539 |
| 2 | 1.550890 | -0.107175 | 0.598361 | -0.256081 |
| 3 | -0.408859 | -0.425947 | 0.243335 | 0.013920 |
| 4 | 1.132749 | -0.814565 | -0.202885 | 0.224138 |
拟合后,PCA实例在其components_属性中包含loadings。(不幸的是,PCA的术语表达还没有统一。我们这里把X_pca中转换后的列称为components,否则它们将没有名称。)我们将把loadings包装到dataframe中:
1 | loadings = pd.DataFrame( |
| PC1 | PC2 | PC3 | PC4 | |
|---|---|---|---|---|
| highway_mpg | -0.492347 | 0.770892 | 0.070142 | -0.397996 |
| engine_size | 0.503859 | 0.626709 | 0.019960 | 0.594107 |
| horsepower | 0.500448 | 0.013788 | 0.731093 | -0.463534 |
| curb_weight | 0.503262 | 0.113008 | -0.678369 | -0.523232 |
记住,组件loadings的符号和幅度告诉我们它捕获了什么类型的变异。第一组件(PC1)显示了大型、强力车辆与油耗差,和较小、更经济的车辆与良好油耗之间的对比。我们可能称之为”豪华/经济”轴。下图显示我们选择的四个特征主要沿着豪华/经济轴变化。
1 | # 查看解释方差 |
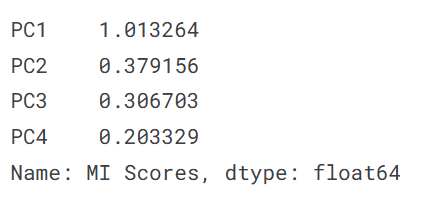
让我们也看看组件的MI分数。不出所料,PC1高度信息丰富,尽管其余组件尽管方差小,但与price仍有显著关系。检查这些组件可能值得发现未被主要豪华/经济轴捕获的关系。
1 | mi_scores = make_mi_scores(X_pca, y, discrete_features=False) |
第三个组件显示了horsepower和curb_weight之间的对比 – 看起来是跑车与旅行车的对比。
1 | # 显示按PC3排序的数据框 |
为了表达这种对比,让我们创建一个新的比率特征:
1 | df["sports_or_wagon"] = X.curb_weight / X.horsepower |
与价格(y轴)的关系,呈U形曲线,中间值价格最低,两端价格较高")
译者注:说明几个问题
1.components选取标准
从定义上讲,主成分实际上是原始特征的线性组合,每个主成分的选取标准是:
- 第一主成分(PC1):寻找数据中方差最大的方向
- 第二主成分(PC2):寻找与第一主成分正交(垂直)且方差第二大的方向
- 依此类推…
这种参考是纯数学的 - PCA算法本身不了解这些数字代表”汽车”,它只是找到数据中变化最显著的方向。
2.载荷矩阵的解释
loadings矩阵告诉我们每个原始特征对主成分的贡献程度:
2
3
4
5
highway_mpg -0.492347 0.770892 0.070142 -0.397996
engine_size 0.503859 0.626709 0.019960 0.594107
horsepower 0.500448 0.013788 0.731093 -0.463534
curb_weight 0.503262 0.113008 -0.678369 -0.523232看PC1列,我们可以解读为:
- highway_mpg(高速公路每加仑英里数,或高速公路油耗效率)与其他特征呈负相关(-0.49 vs ~0.50)
- 这意味着PC1捕获了”省油但小型低功率”与”耗油但大型高功率”车辆之间的对比
豪华车通常引擎大、马力高、车身重、耗油多;而经济车则引擎小、马力低、车身轻、省油多。所以研究人员将PC1命名为”豪华/经济轴”是有意义的 - 这是基于对数据模式的人类解释,而不是算法的内置功能。
3.为什么计算MI值?
这里的关键点是:PCA本身只关心数据的变异性,不关心这些变异与目标变量(这里是价格)的关系。
计算互信息(MI)是为了回答:这些新找到的主成分对预测价格有多大用处?
结果显示:
- PC1的MI值最高(1.01):说明豪华/经济轴与价格关系最密切
- 其他主成分的MI值较低:但仍然包含与价格相关的信息
例如,PC3(”运动车vs旅行车”轴)的MI值为0.31,说明它包含的信息对预测价格有中等程度的帮助。我们不妨对其分析一下:
PC3主要由两个特征驱动:horsepower(马力)和curb_weight(整备重量),因为它们的绝对值最大。
当一辆车在PC3上得分高时,它通常具有:
- 较高的horsepower(高马力)
- 较低的curb_weight(轻车身)
当一辆车在PC3上得分低时,它通常具有:
- 较低的horsepower(低马力)
- 较高的curb_weight(重车身)
这种组合很好地描述了”高性能跑车”与”重型/实用车”之间的区别:
- 跑车:追求高马力与轻车身的组合,以获得更好的加速性能和操控性
- 旅行车/大型车:马力可能不高但车身较重,注重实用性和空间
因此,研究人员将PC3解释为”运动车vs旅行车”轴是合理的,表格也证实了这一点:PC3得分高的车辆确实多为运动型车,而PC3得分低的车辆多为大型车或旅行车。这个主成分虽然只解释了原始数据中较小部分的变异,但它捕获了汽车市场中一个非常有意义的维度。根据最后的图片我们也可以知道,PC3得分越低价格越高,得分中等的车辆最多价格也最少。
所以说呢,结合上上一讲的互信息,目前PCA最好与MI联合使用:
1.先用MI筛选评分最高的几个特征
2.使用PCA划分组件
3.使用载荷矩阵查看占比
4.再次MI分析,打上更具有解释性意义的标签
WOW,为什么我觉得自己讲的比原作者明白多了?(逃
 微信
微信 支付寶
支付寶



